 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study in Dataset Pruning for Image Super-Resolution
Paper and Code
Mar 25, 2024
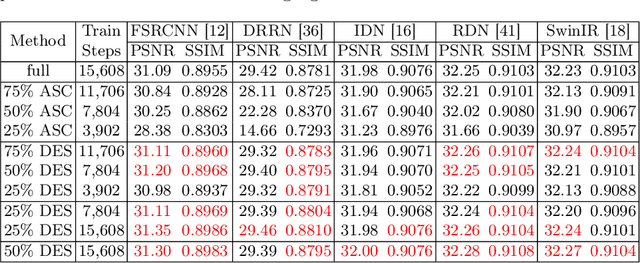


In image Super-Resolution (SR), relying on large datasets for training is a double-edged sword. While offering rich training material, they also demand substantial computational and storage resources. In this work, we analyze dataset pruning as a solution to these challenges. We introduce a novel approach that reduces a dataset to a core-set of training samples, selected based on their loss values as determined by a simple pre-trained SR model. By focusing the training on just 50% of the original dataset, specifically on the samples characterized by the highest loss values, we achieve results comparable to or even surpassing those obtained from training on the entire dataset. Interestingly, our analysis reveals that the top 5% of samples with the highest loss values negatively affect the training process. Excluding these samples and adjusting the selection to favor easier samples further enhances training outcomes. Our work opens new perspectives to the untapped potential of dataset pruning in image SR. It suggests that careful selection of training data based on loss-value metrics can lead to better SR models, challenging the conventional wisdom that more data inevitably leads to better performance.