 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioCLIP: Extending CLIP to Image, Text and Audio
Jun 24, 2021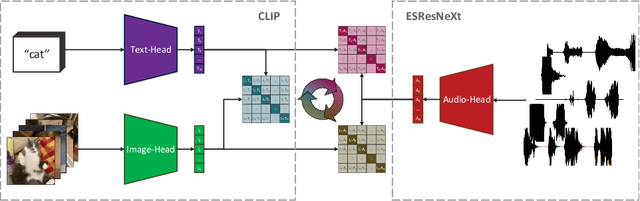

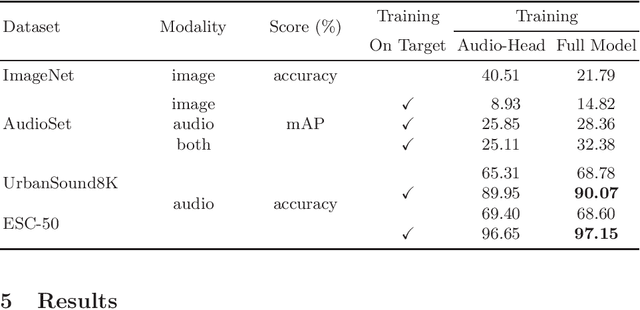

In the past, the rapidly evolving field of sound classification greatly benefited from the application of methods from other domains. Today, we observe the trend to fuse domain-specific tasks and approaches together, which provides the community with new outstanding models. In this work, we present an extension of the CLIP model that handles audio in addition to text and images. Our proposed model incorporates the ESResNeXt audio-model into the CLIP framework using the AudioSet dataset. Such a combination enables the proposed model to perform bimodal and unimodal classification and querying, while keeping CLIP's ability to generalize to unseen datasets in a zero-shot inference fashion. AudioCLIP achieves new state-of-the-art results in the Environmental Sound Classification (ESC) task, out-performing other approaches by reaching accuracies of 90.07% on the UrbanSound8K and 97.15% on the ESC-50 datasets. Further it sets new baselines in the zero-shot ESC-task on the same datasets 68.78% and 69.40%, respectively). Finally, we also assess the cross-modal querying performance of the proposed model as well as the influence of full and partial training on the results. For the sake of reproducibility, our code is published.
ESResNe(X)t-fbsp: Learning Robust Time-Frequency Transformation of Audio
Apr 23, 2021

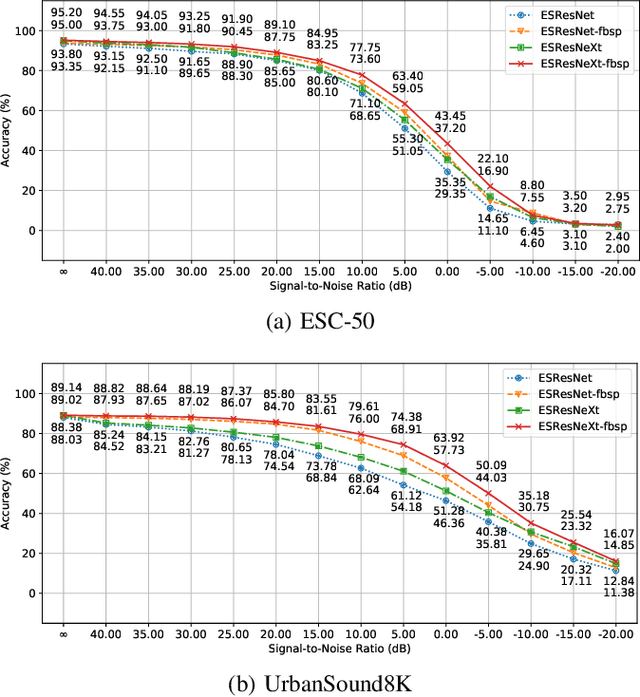

Environmental Sound Classification (ESC) is a rapidly evolving field that recently demonstrated the advantages of application of visual domain techniques to the audio-related tasks. Previous studies indicate that the domain-specific modification of cross-domain approaches show a promise in pushing the whole area of ESC forward. In this paper, we present a new time-frequency transformation layer that is based on complex frequency B-spline (fbsp) wavelets. Being used with a high-performance audio classification model, the proposed fbsp-layer provides an accuracy improvement over the previously used Short-Time Fourier Transform (STFT) on standard datasets. We also investigate the influence of different pre-training strategies, including the joint use of two large-scale datasets for weight initialization: ImageNet and AudioSet. Our proposed model out-performs other approaches by achieving accuracies of 95.20 % on the ESC-50 and 89.14 % on the UrbanSound8K datasets. Additionally, we assess the increase of model robustness against additive white Gaussian noise and reduction of an effective sample rate introduced by the proposed layer and demonstrate that the fbsp-layer improves the model's ability to withstand signal perturbations, in comparison to STFT-based training. For the sake of reproducibility, our code is made available.
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Apr 15, 2020

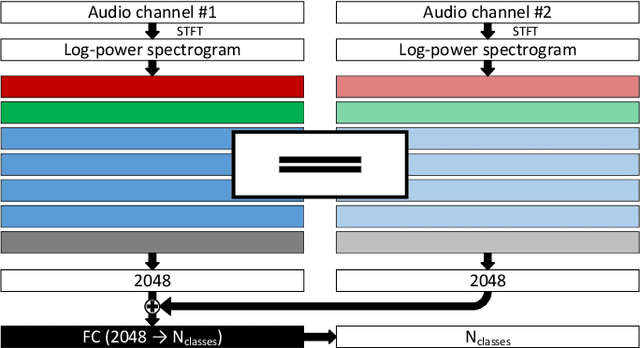

Environmental Sound Classification (ESC) is an active research area in the audio domain and has seen a lot of progress in the past years. However, many of the existing approaches achieve high accuracy by relying on domain-specific features and architectures, making it harder to benefit from advances in other fields (e.g., the image domain). Additionally, some of the past successes have been attributed to a discrepancy of how results are evaluated (i.e., on unofficial splits of the UrbanSound8K (US8K) dataset), distorting the overall progression of the field. The contribution of this paper is twofold. First, we present a model that is inherently compatible with mono and stereo sound inputs. Our model is based on simple log-power Short-Time Fourier Transform (STFT) spectrograms and combines them with several well-known approaches from the image domain (i.e., ResNet, Siamese-like networks and attention). We investigate the influence of cross-domain pre-training, architectural changes, and evaluate our model on standard datasets. We find that our model out-performs all previously known approaches in a fair comparison by achieving accuracies of 97.0 % (ESC-10), 91.5 % (ESC-50) and 84.2 % / 85.4 % (US8K mono / stereo). Second, we provide a comprehensive overview of the actual state of the field, by differentiating several previously reported results on the US8K dataset between official or unofficial splits. For better reproducibility, our code (including any re-implementations) is made available.