 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESResNet: Environmental Sound Classification Based on Visual Domain Models
Paper and Code


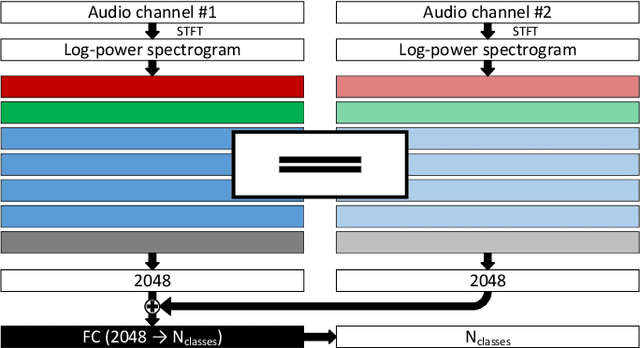

Environmental Sound Classification (ESC) is an active research area in the audio domain and has seen a lot of progress in the past years. However, many of the existing approaches achieve high accuracy by relying on domain-specific features and architectures, making it harder to benefit from advances in other fields (e.g., the image domain). Additionally, some of the past successes have been attributed to a discrepancy of how results are evaluated (i.e., on unofficial splits of the UrbanSound8K (US8K) dataset), distorting the overall progression of the field. The contribution of this paper is twofold. First, we present a model that is inherently compatible with mono and stereo sound inputs. Our model is based on simple log-power Short-Time Fourier Transform (STFT) spectrograms and combines them with several well-known approaches from the image domain (i.e., ResNet, Siamese-like networks and attention). We investigate the influence of cross-domain pre-training, architectural changes, and evaluate our model on standard datasets. We find that our model out-performs all previously known approaches in a fair comparison by achieving accuracies of 97.0 % (ESC-10), 91.5 % (ESC-50) and 84.2 % / 85.4 % (US8K mono / stereo). Second, we provide a comprehensive overview of the actual state of the field, by differentiating several previously reported results on the US8K dataset between official or unofficial splits. For better reproducibility, our code (including any re-implementations) is made available.