 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Language Model for Feasible and Diverse Population Synthesis
May 07, 2025



Generating a synthetic population that is both feasible and diverse is crucial for ensuring the validity of downstream activity schedule simulation in activity-based models (ABMs). While deep generative models (DGMs), such as variational autoencoders and generative adversarial networks, have been applied to this task, they often struggle to balance the inclusion of rare but plausible combinations (i.e., sampling zeros) with the exclusion of implausible ones (i.e., structural zeros). To improve feasibility while maintaining diversity, we propose a fine-tuning method for large language models (LLMs) that explicitly controls the autoregressive generation process through topological orderings derived from a Bayesian Network (BN). Experimental results show that our hybrid LLM-BN approach outperforms both traditional DGMs and proprietary LLMs (e.g., ChatGPT-4o) with few-shot learning. Specifically, our approach achieves approximately 95% feasibility, significantly higher than the ~80% observed in DGMs, while maintaining comparable diversity, making it well-suited for practical applications. Importantly, the method is based on a lightweight open-source LLM, enabling fine-tuning and inference on standard personal computing environments. This makes the approach cost-effective and scalable for large-scale applications, such as synthesizing populations in megacities, without relying on expensive infrastructure. By initiating the ABM pipeline with high-quality synthetic populations, our method improves overall simulation reliability and reduces downstream error propagation. The source code for these methods is available for research and practical application.
A Deep Generative Model for Feasible and Diverse Population Synthesis
Aug 01, 2022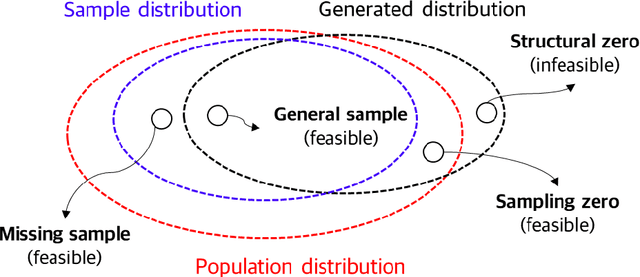
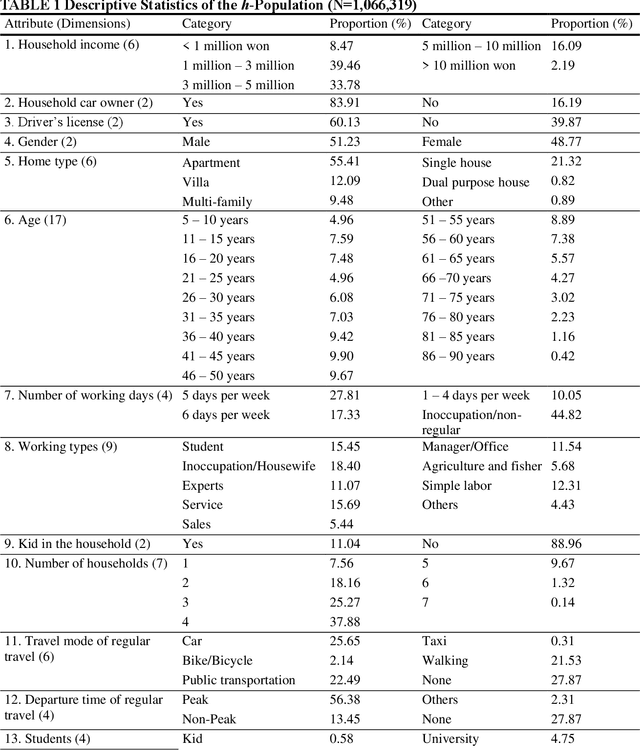

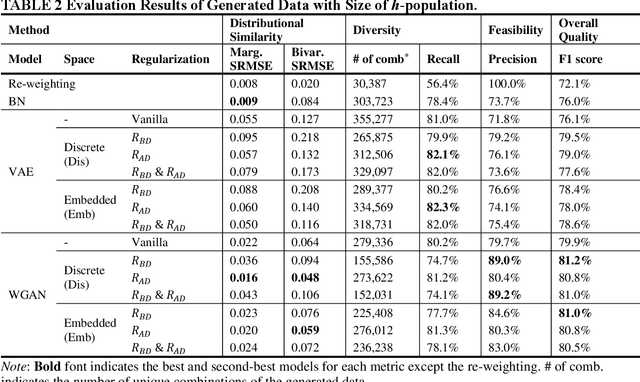
An ideal synthetic population, a key input to activity-based models, mimics the distribution of the individual- and household-level attributes in the actual population. Since the entire population's attributes are generally unavailable, household travel survey (HTS) samples are used for population synthesis. Synthesizing population by directly sampling from HTS ignores the attribute combinations that are unobserved in the HTS samples but exist in the population, called 'sampling zeros'. A deep generative model (DGM) can potentially synthesize the sampling zeros but at the expense of generating 'structural zeros' (i.e., the infeasible attribute combinations that do not exist in the population). This study proposes a novel method to minimize structural zeros while preserving sampling zeros. Two regularizations are devised to customize the training of the DGM and applied to a generative adversarial network (GAN) and a variational autoencoder (VAE). The adopted metrics for feasibility and diversity of the synthetic population indicate the capability of generating sampling and structural zeros -- lower structural zeros and lower sampling zeros indicate the higher feasibility and the lower diversity, respectively. Results show that the proposed regularizations achieve considerable performance improvement in feasibility and diversity of the synthesized population over traditional models. The proposed VAE additionally generated 23.5% of the population ignored by the sample with 79.2% precision (i.e., 20.8% structural zeros rates), while the proposed GAN generated 18.3% of the ignored population with 89.0% precision. The proposed improvement in DGM generates a more feasible and diverse synthetic population, which is critical for the accuracy of an activity-based model.
DT2I: Dense Text-to-Image Generation from Region Descriptions
Apr 05, 2022
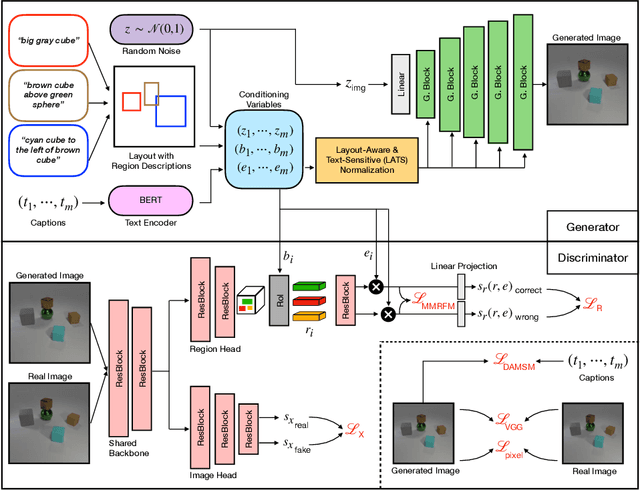
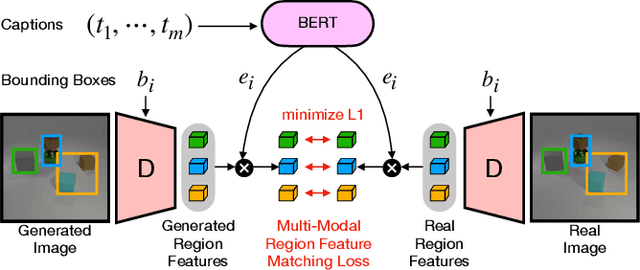
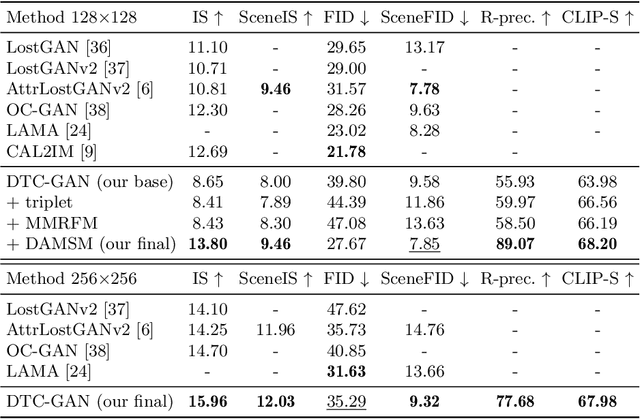
Despite astonishing progress, generating realistic images of complex scenes remains a challenging problem. Recently, layout-to-image synthesis approaches have attracted much interest by conditioning the generator on a list of bounding boxes and corresponding class labels. However, previous approaches are very restrictive because the set of labels is fixed a priori. Meanwhile, text-to-image synthesis methods have substantially improved and provide a flexible way for conditional image generation. In this work, we introduce dense text-to-image (DT2I) synthesis as a new task to pave the way toward more intuitive image generation. Furthermore, we propose DTC-GAN, a novel method to generate images from semantically rich region descriptions, and a multi-modal region feature matching loss to encourage semantic image-text matching. Our results demonstrate the capability of our approach to generate plausible images of complex scenes using region captions.
Fast Bayesian Estimation of Spatial Count Data Models
Jul 07, 2020



Spatial count data models are used to explain and predict the frequency of phenomena such as traffic accidents in geographically distinct entities such as census tracts or road segments. These models are typically estimated using Bayesian Markov chain Monte Carlo (MCMC) simulation methods, which, however, are computationally expensive and do not scale well to large datasets. Variational Bayes (VB), a method from machine learning, addresses the shortcomings of MCMC by casting Bayesian estimation as an optimisation problem instead of a simulation problem. In this paper, we derive a VB method for posterior inference in negative binomial models with unobserved parameter heterogeneity and spatial dependence. The proposed method uses Polya-Gamma augmentation to deal with the non-conjugacy of the negative binomial likelihood and an integrated non-factorised specification of the variational distribution to capture posterior dependencies. We demonstrate the benefits of the approach using simulated data and real data on youth pedestrian injury counts in the census tracts of New York City boroughs Bronx and Manhattan. The empirical analysis suggests that the VB approach is between 7 and 13 times faster than MCMC on a regular eight-core processor, while offering similar estimation and predictive accuracy. Conditional on the availability of computational resources, the embarrassingly parallel architecture of the proposed VB method can be exploited to further accelerate the estimation by up to 100 times.
Pólygamma Data Augmentation to address Non-conjugacy in the Bayesian Estimation of Mixed Multinomial Logit Models
Apr 13, 2019The standard Gibbs sampler of Mixed Multinomial Logit (MMNL) models involves sampling from conditional densities of utility parameters using Metropolis-Hastings (MH) algorithm due to unavailability of conjugate prior for logit kernel. To address this non-conjugacy concern, we propose the application of P\'olygamma data augmentation (PG-DA) technique for the MMNL estimation. The posterior estimates of the augmented and the default Gibbs sampler are similar for two-alternative scenario (binary choice), but we encounter empirical identification issues in the case of more alternatives ($J \geq 3$).
Bayesian Estimation of Mixed Multinomial Logit Models: Advances and Simulation-Based Evaluations
Apr 12, 2019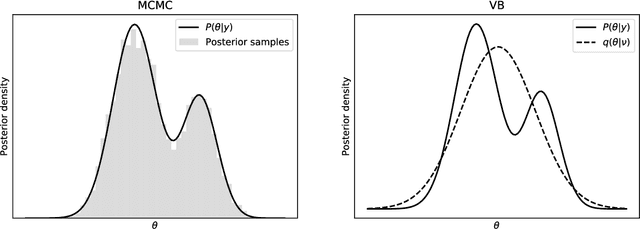
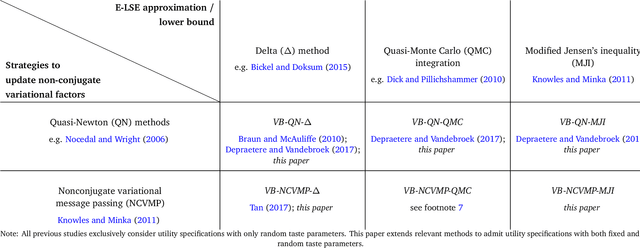
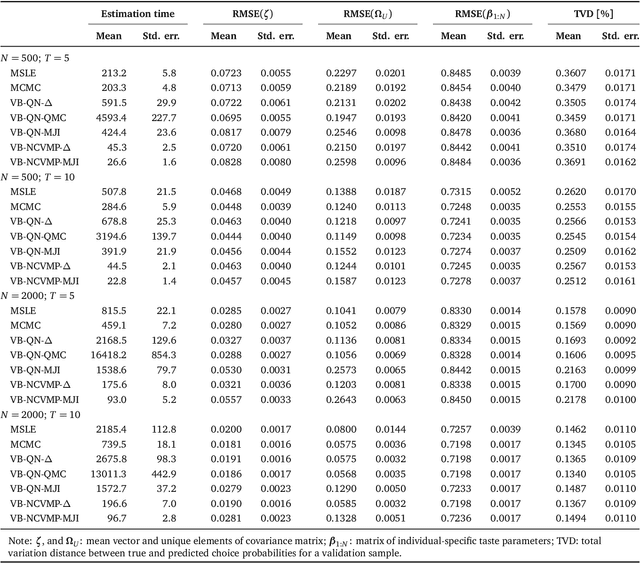
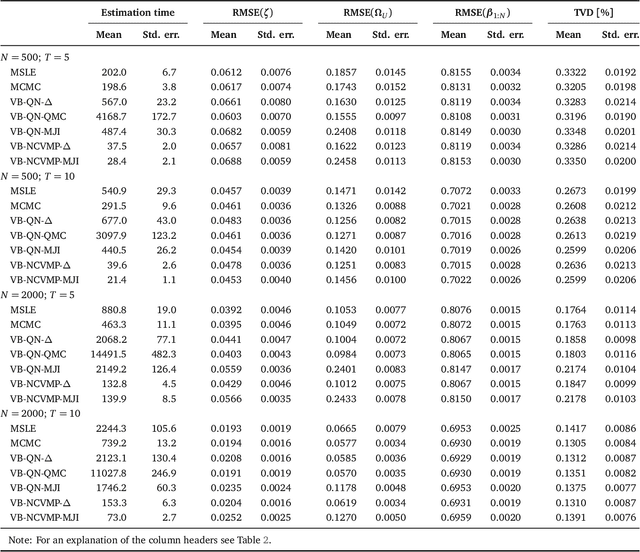
Variational Bayes (VB) methods have emerged as a fast and computationally-efficient alternative to Markov chain Monte Carlo (MCMC) methods for Bayesian estimation of mixed multinomial logit (MMNL) models. It has been established that VB is substantially faster than MCMC at practically no compromises in predictive accuracy. In this paper, we address two critical gaps concerning the usage and understanding of VB for MMNL. First, extant VB methods are limited to utility specifications involving only individual-specific taste parameters. Second, the finite-sample properties of VB estimators and the relative performance of VB, MCMC and maximum simulated likelihood estimation (MSLE) are not known. To address the former, this study extends several VB methods for MMNL to admit utility specifications including both fixed and random utility parameters. To address the latter, we conduct an extensive simulation-based evaluation to benchmark the extended VB methods against MCMC and MSLE in terms of estimation times, parameter recovery and predictive accuracy. The results suggest that all VB variants perform as well as MCMC and MSLE at prediction and recovery of all model parameters with the exception of the covariance matrix of the multivariate normal mixing distribution. In particular, VB with nonconjugate variational message passing and the delta-method (VB-NCVMP-Delta) is relatively accurate and up to 15 times faster than MCMC and MSLE. On the whole, VB-NCVMP-Delta is most suitable for applications in which fast predictions are paramount, while MCMC should be preferred in applications in which accurate inferences are most important.