 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Deep Models through the Lens of Data
Paper and Code
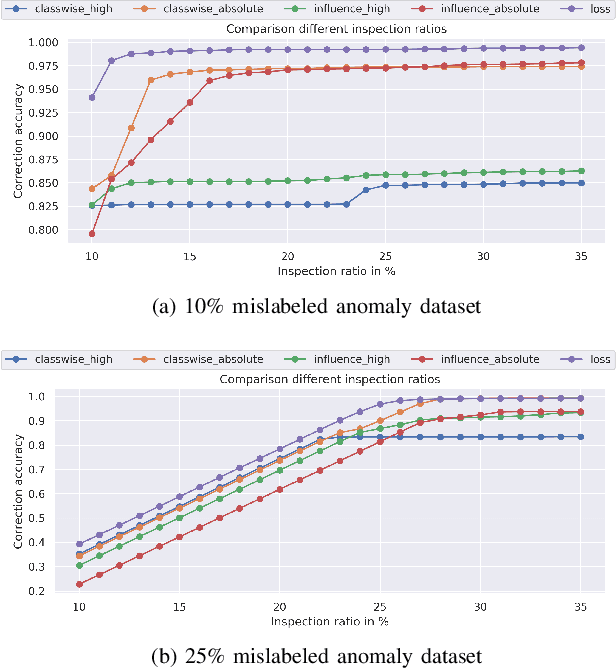
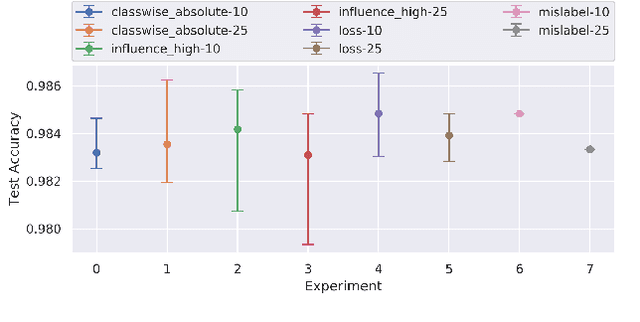
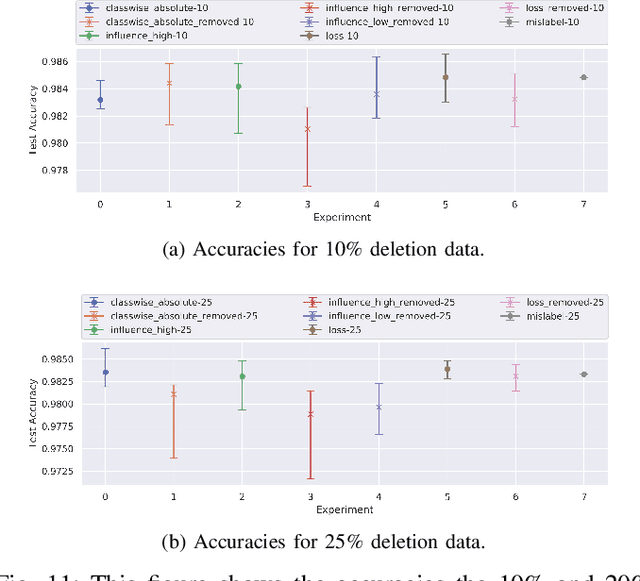
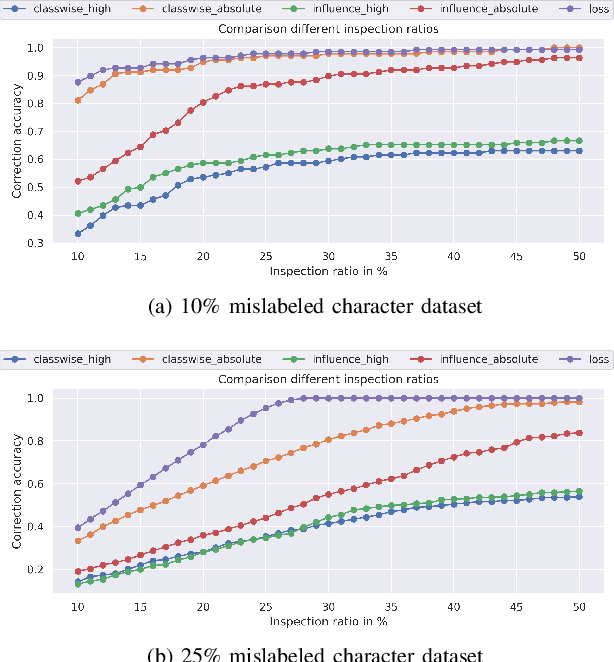
Identification of input data points relevant for the classifier (i.e. serve as the support vector) has recently spurred the interest of researchers for both interpretability as well as dataset debugging. This paper presents an in-depth analysis of the methods which attempt to identify the influence of these data points on the resulting classifier. To quantify the quality of the influence, we curated a set of experiments where we debugged and pruned the dataset based on the influence information obtained from different methods. To do so, we provided the classifier with mislabeled examples that hampered the overall performance. Since the classifier is a combination of both the data and the model, therefore, it is essential to also analyze these influences for the interpretability of deep learning models. Analysis of the results shows that some interpretability methods can detect mislabels better than using a random approach, however, contrary to the claim of these methods, the sample selection based on the training loss showed a superior performance.