 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTAB-GAN+: Enhancing Tabular Data Synthesis
Apr 01, 2022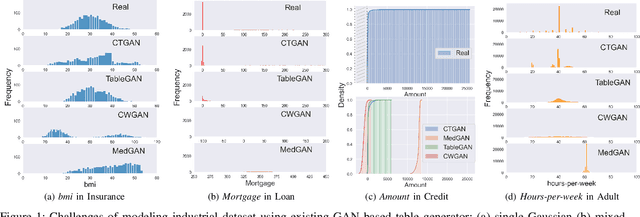
While data sharing is crucial for knowledge development, privacy concerns and strict regulation (e.g., European General Data Protection Regulation (GDPR)) limit its full effectiveness. Synthetic tabular data emerges as alternative to enable data sharing while fulfilling regulatory and privacy constraints. State-of-the-art tabular data synthesizers draw methodologies from Generative Adversarial Networks (GAN). As GANs improve the synthesized data increasingly resemble the real data risking to leak privacy. Differential privacy (DP) provides theoretical guarantees on privacy loss but degrades data utility. Striking the best trade-off remains yet a challenging research question. We propose CTAB-GAN+ a novel conditional tabular GAN. CTAB-GAN+ improves upon state-of-the-art by (i) adding downstream losses to conditional GANs for higher utility synthetic data in both classification and regression domains; (ii) using Wasserstein loss with gradient penalty for better training convergence; (iii) introducing novel encoders targeting mixed continuous-categorical variables and variables with unbalanced or skewed data; and (iv) training with DP stochastic gradient descent to impose strict privacy guarantees. We extensively evaluate CTAB-GAN+ on data similarity and analysis utility against state-of-the-art tabular GANs. The results show that CTAB-GAN+ synthesizes privacy-preserving data with at least 48.16% higher utility across multiple datasets and learning tasks under different privacy budgets.
Fed-TGAN: Federated Learning Framework for Synthesizing Tabular Data
Aug 18, 2021
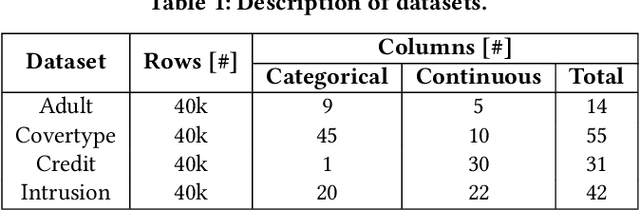
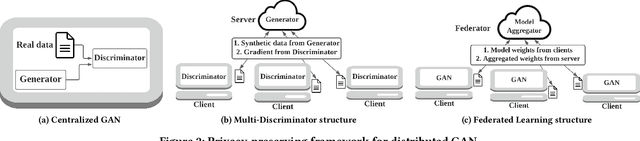
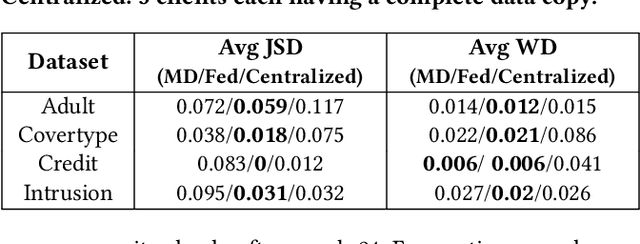
Generative Adversarial Networks (GANs) are typically trained to synthesize data, from images and more recently tabular data, under the assumption of directly accessible training data. Recently, federated learning (FL) is an emerging paradigm that features decentralized learning on client's local data with a privacy-preserving capability. And, while learning GANs to synthesize images on FL systems has just been demonstrated, it is unknown if GANs for tabular data can be learned from decentralized data sources. Moreover, it remains unclear which distributed architecture suits them best. Different from image GANs, state-of-the-art tabular GANs require prior knowledge on the data distribution of each (discrete and continuous) column to agree on a common encoding -- risking privacy guarantees. In this paper, we propose Fed-TGAN, the first Federated learning framework for Tabular GANs. To effectively learn a complex tabular GAN on non-identical participants, Fed-TGAN designs two novel features: (i) a privacy-preserving multi-source feature encoding for model initialization; and (ii) table similarity aware weighting strategies to aggregate local models for countering data skew. We extensively evaluate the proposed Fed-TGAN against variants of decentralized learning architectures on four widely used datasets. Results show that Fed-TGAN accelerates training time per epoch up to 200% compared to the alternative architectures, for both IID and Non-IID data. Overall, Fed-TGAN not only stabilizes the training loss, but also achieves better similarity between generated and original data.
Effective and Privacy preserving Tabular Data Synthesizing
Aug 11, 2021
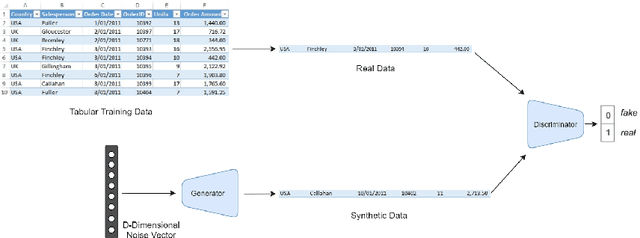


While data sharing is crucial for knowledge development, privacy concerns and strict regulation (e.g., European General Data Protection Regulation (GDPR)) unfortunately limits its full effectiveness. Synthetic tabular data emerges as an alternative to enable data sharing while fulfilling regulatory and privacy constraints. The state-of-the-art tabular data synthesizers draw methodologies from Generative Adversarial Networks (GAN). In this thesis, we develop CTAB-GAN, a novel conditional table GAN architecture that can effectively model diverse data types with complex distributions. CTAB-GAN is extensively evaluated with the state of the art GANs that generate synthetic tables, in terms of data similarity and analysis utility. The results on five datasets show that the synthetic data of CTAB-GAN remarkably resembles the real data for all three types of variables and results in higher accuracy for five machine learning algorithms, by up to 17%. Additionally, to ensure greater security for training tabular GANs against malicious privacy attacks, differential privacy (DP) is studied and used to train CTAB-GAN with strict privacy guarantees. DP-CTAB-GAN is rigorously evaluated using state-of-the-art DP-tabular GANs in terms of data utility and privacy robustness against membership and attribute inference attacks. Our results on three datasets indicate that strict theoretical differential privacy guarantees come only after severely affecting data utility. However, it is shown empirically that these guarantees help provide a stronger defence against privacy attacks. Overall, it is found that DP-CTABGAN is capable of being robust to privacy attacks while maintaining the highest data utility as compared to prior work, by up to 18% in terms of the average precision score.
DTGAN: Differential Private Training for Tabular GANs
Aug 02, 2021


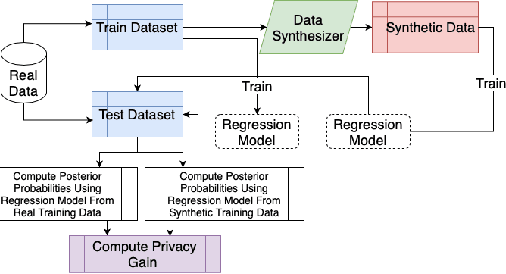
Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.
CTAB-GAN: Effective Table Data Synthesizing
Feb 16, 2021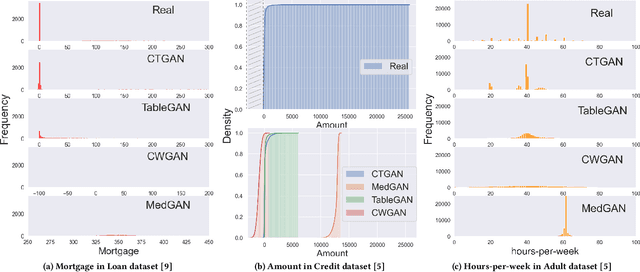
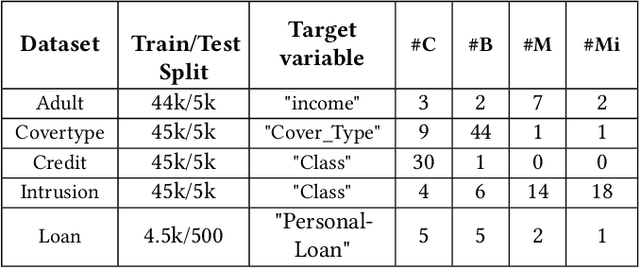
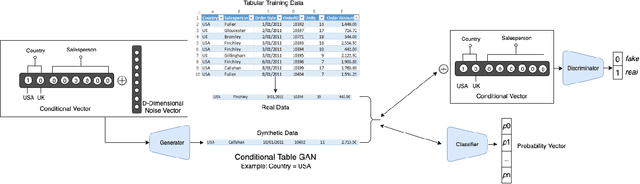
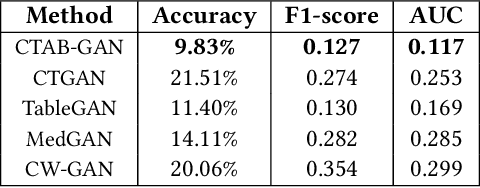
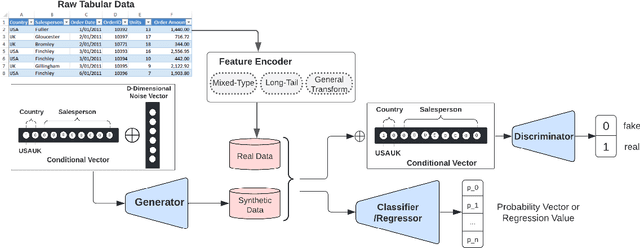
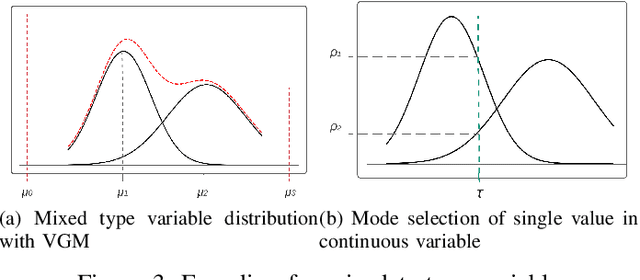
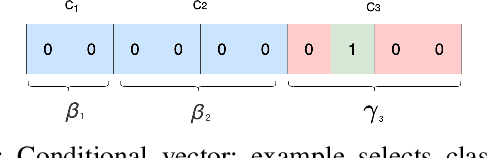
While data sharing is crucial for knowledge development, privacy concerns and strict regulation (e.g., European General Data Protection Regulation (GDPR)) unfortunately limit its full effectiveness. Synthetic tabular data emerges as an alternative to enable data sharing while fulfilling regulatory and privacy constraints. The state-of-the-art tabular data synthesizers draw methodologies from generative Adversarial Networks (GAN) and address two main data types in the industry, i.e., continuous and categorical. In this paper, we develop CTAB-GAN, a novel conditional table GAN architecture that can effectively model diverse data types, including a mix of continuous and categorical variables. Moreover, we address data imbalance and long-tail issues, i.e., certain variables have drastic frequency differences across large values. To achieve those aims, we first introduce the information loss and classification loss to the conditional GAN. Secondly, we design a novel conditional vector, which efficiently encodes the mixed data type and skewed distribution of data variable. We extensively evaluate CTAB-GAN with the state of the art GANs that generate synthetic tables, in terms of data similarity and analysis utility. The results on five datasets show that the synthetic data of CTAB-GAN remarkably resembles the real data for all three types of variables and results into higher accuracy for five machine learning algorithms, by up to 17%.