 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBespoke Solvers for Generative Flow Models
Oct 29, 2023


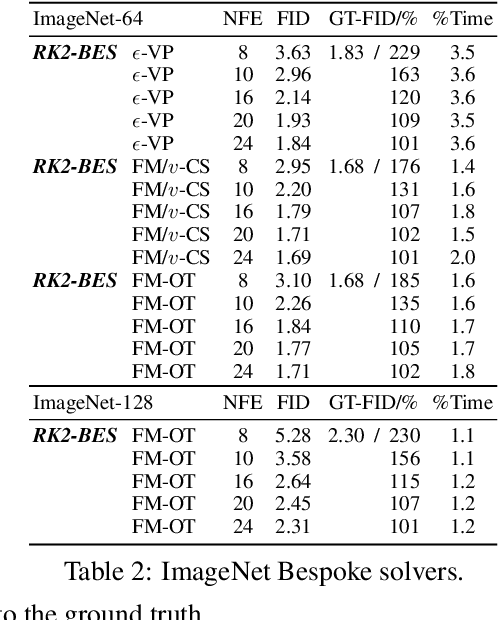
Diffusion or flow-based models are powerful generative paradigms that are notoriously hard to sample as samples are defined as solutions to high-dimensional Ordinary or Stochastic Differential Equations (ODEs/SDEs) which require a large Number of Function Evaluations (NFE) to approximate well. Existing methods to alleviate the costly sampling process include model distillation and designing dedicated ODE solvers. However, distillation is costly to train and sometimes can deteriorate quality, while dedicated solvers still require relatively large NFE to produce high quality samples. In this paper we introduce "Bespoke solvers", a novel framework for constructing custom ODE solvers tailored to the ODE of a given pre-trained flow model. Our approach optimizes an order consistent and parameter-efficient solver (e.g., with 80 learnable parameters), is trained for roughly 1% of the GPU time required for training the pre-trained model, and significantly improves approximation and generation quality compared to dedicated solvers. For example, a Bespoke solver for a CIFAR10 model produces samples with Fr\'echet Inception Distance (FID) of 2.73 with 10 NFE, and gets to 1% of the Ground Truth (GT) FID (2.59) for this model with only 20 NFE. On the more challenging ImageNet-64$\times$64, Bespoke samples at 2.2 FID with 10 NFE, and gets within 2% of GT FID (1.71) with 20 NFE.
BatMan-CLR: Making Few-shots Meta-Learners Resilient Against Label Noise
Sep 12, 2023



The negative impact of label noise is well studied in classical supervised learning yet remains an open research question in meta-learning. Meta-learners aim to adapt to unseen learning tasks by learning a good initial model in meta-training and consecutively fine-tuning it according to new tasks during meta-testing. In this paper, we present the first extensive analysis of the impact of varying levels of label noise on the performance of state-of-the-art meta-learners, specifically gradient-based $N$-way $K$-shot learners. We show that the accuracy of Reptile, iMAML, and foMAML drops by up to 42% on the Omniglot and CifarFS datasets when meta-training is affected by label noise. To strengthen the resilience against label noise, we propose two sampling techniques, namely manifold (Man) and batch manifold (BatMan), which transform the noisy supervised learners into semi-supervised ones to increase the utility of noisy labels. We first construct manifold samples of $N$-way $2$-contrastive-shot tasks through augmentation, learning the embedding via a contrastive loss in meta-training, and then perform classification through zeroing on the embedding in meta-testing. We show that our approach can effectively mitigate the impact of meta-training label noise. Even with 60% wrong labels \batman and \man can limit the meta-testing accuracy drop to ${2.5}$, ${9.4}$, ${1.1}$ percent points, respectively, with existing meta-learners across the Omniglot, CifarFS, and MiniImagenet datasets.