 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackFlow: Multi-Object Tracking with Normalizing Flows
Aug 22, 2023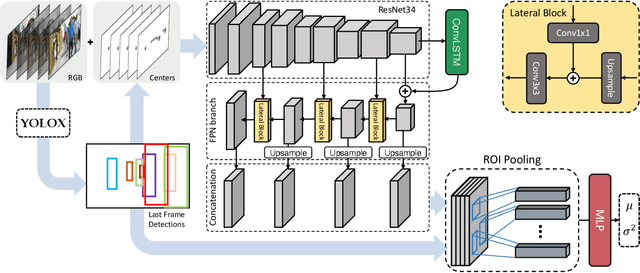


The field of multi-object tracking has recently seen a renewed interest in the good old schema of tracking-by-detection, as its simplicity and strong priors spare it from the complex design and painful babysitting of tracking-by-attention approaches. In view of this, we aim at extending tracking-by-detection to multi-modal settings, where a comprehensive cost has to be computed from heterogeneous information e.g., 2D motion cues, visual appearance, and pose estimates. More precisely, we follow a case study where a rough estimate of 3D information is also available and must be merged with other traditional metrics (e.g., the IoU). To achieve that, recent approaches resort to either simple rules or complex heuristics to balance the contribution of each cost. However, i) they require careful tuning of tailored hyperparameters on a hold-out set, and ii) they imply these costs to be independent, which does not hold in reality. We address these issues by building upon an elegant probabilistic formulation, which considers the cost of a candidate association as the negative log-likelihood yielded by a deep density estimator, trained to model the conditional joint probability distribution of correct associations. Our experiments, conducted on both simulated and real benchmarks, show that our approach consistently enhances the performance of several tracking-by-detection algorithms.
MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?
Aug 21, 2021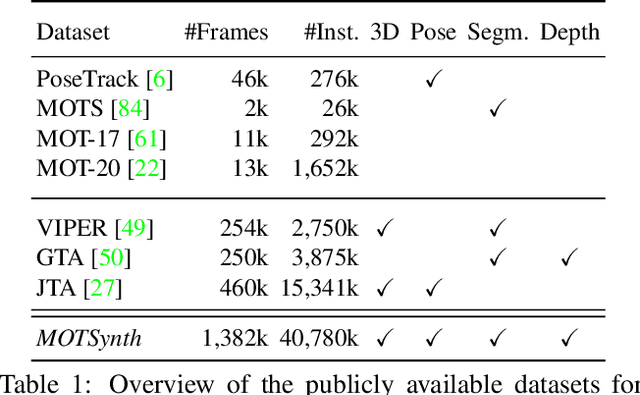

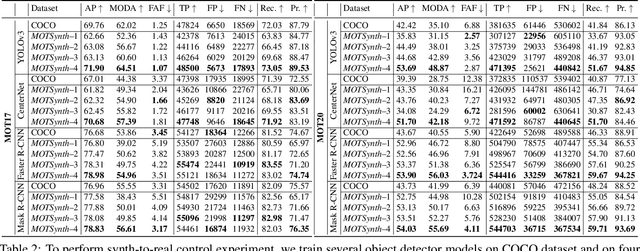
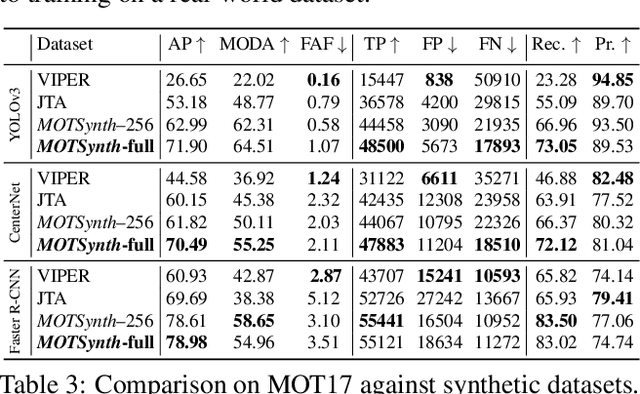
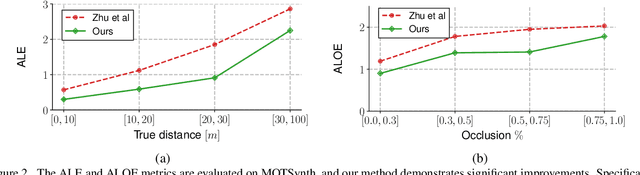
Deep learning-based methods for video pedestrian detection and tracking require large volumes of training data to achieve good performance. However, data acquisition in crowded public environments raises data privacy concerns -- we are not allowed to simply record and store data without the explicit consent of all participants. Furthermore, the annotation of such data for computer vision applications usually requires a substantial amount of manual effort, especially in the video domain. Labeling instances of pedestrians in highly crowded scenarios can be challenging even for human annotators and may introduce errors in the training data. In this paper, we study how we can advance different aspects of multi-person tracking using solely synthetic data. To this end, we generate MOTSynth, a large, highly diverse synthetic dataset for object detection and tracking using a rendering game engine. Our experiments show that MOTSynth can be used as a replacement for real data on tasks such as pedestrian detection, re-identification, segmentation, and tracking.
Inter-Homines: Distance-Based Risk Estimation for Human Safety
Jul 20, 2020



In this document, we report our proposal for modeling the risk of possible contagiousity in a given area monitored by RGB cameras where people freely move and interact. Our system, called Inter-Homines, evaluates in real-time the contagion risk in a monitored area by analyzing video streams: it is able to locate people in 3D space, calculate interpersonal distances and predict risk levels by building dynamic maps of the monitored area. Inter-Homines works both indoor and outdoor, in public and private crowded areas. The software is applicable to already installed cameras or low-cost cameras on industrial PCs, equipped with an additional embedded edge-AI system for temporary measurements. From the AI-side, we exploit a robust pipeline for real-time people detection and localization in the ground plane by homographic transformation based on state-of-the-art computer vision algorithms; it is a combination of a people detector and a pose estimator. From the risk modeling side, we propose a parametric model for a spatio-temporal dynamic risk estimation, that, validated by epidemiologists, could be useful for safety monitoring the acceptance of social distancing prevention measures by predicting the risk level of the scene.
Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation
Apr 01, 2020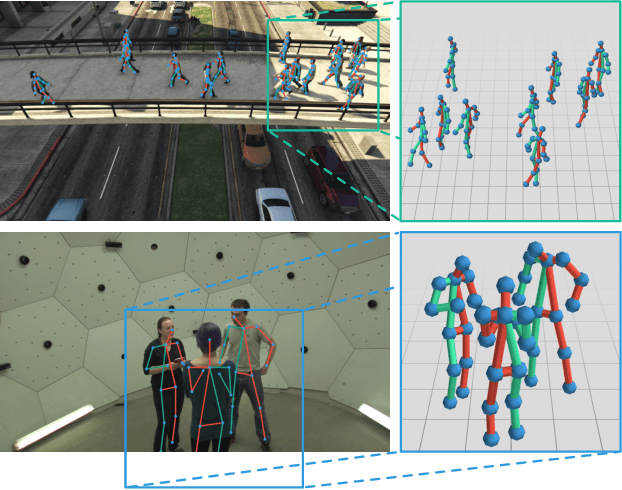
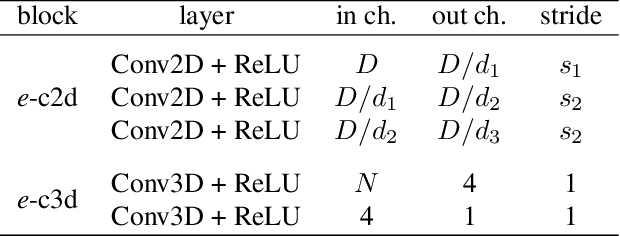
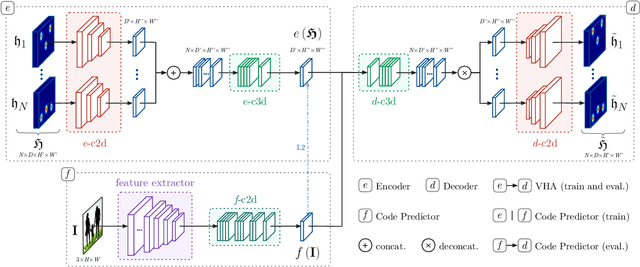

In this paper we present a novel approach for bottom-up multi-person 3D human pose estimation from monocular RGB images. We propose to use high resolution volumetric heatmaps to model joint locations, devising a simple and effective compression method to drastically reduce the size of this representation. At the core of the proposed method lies our Volumetric Heatmap Autoencoder, a fully-convolutional network tasked with the compression of ground-truth heatmaps into a dense intermediate representation. A second model, the Code Predictor, is then trained to predict these codes, which can be decompressed at test time to re-obtain the original representation. Our experimental evaluation shows that our method performs favorably when compared to state of the art on both multi-person and single-person 3D human pose estimation datasets and, thanks to our novel compression strategy, can process full-HD images at the constant runtime of 8 fps regardless of the number of subjects in the scene. Code and models available at https://github.com/fabbrimatteo/LoCO .
Domain Translation with Conditional GANs: from Depth to RGB Face-to-Face
Jan 23, 2019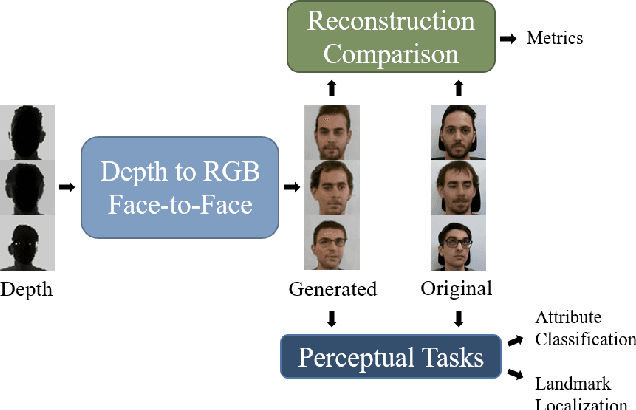
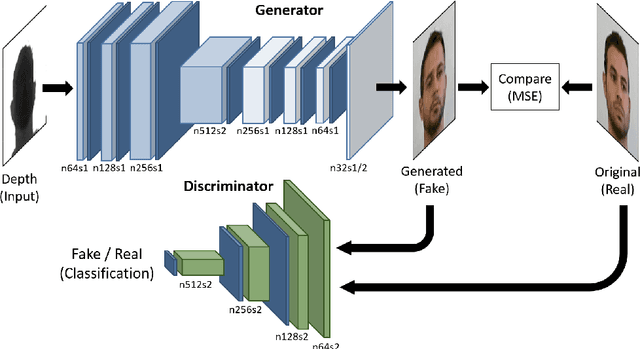


Can faces acquired by low-cost depth sensors be useful to catch some characteristic details of the face? Typically the answer is no. However, new deep architectures can generate RGB images from data acquired in a different modality, such as depth data. In this paper, we propose a new \textit{Deterministic Conditional GAN}, trained on annotated RGB-D face datasets, effective for a face-to-face translation from depth to RGB. Although the network cannot reconstruct the exact somatic features for unknown individual faces, it is capable to reconstruct plausible faces; their appearance is accurate enough to be used in many pattern recognition tasks. In fact, we test the network capability to hallucinate with some \textit{Perceptual Probes}, as for instance face aspect classification or landmark detection. Depth face can be used in spite of the correspondent RGB images, that often are not available due to difficult luminance conditions. Experimental results are very promising and are as far as better than previously proposed approaches: this domain translation can constitute a new way to exploit depth data in new future applications.
Can Adversarial Networks Hallucinate Occluded People With a Plausible Aspect?
Jan 23, 2019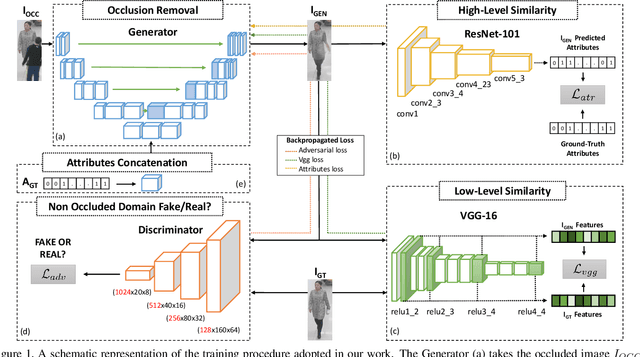
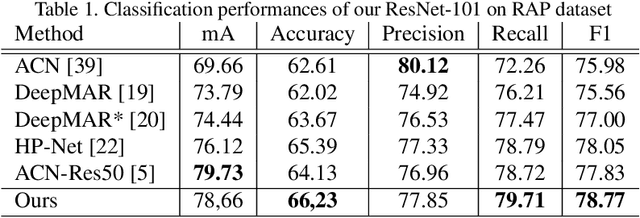
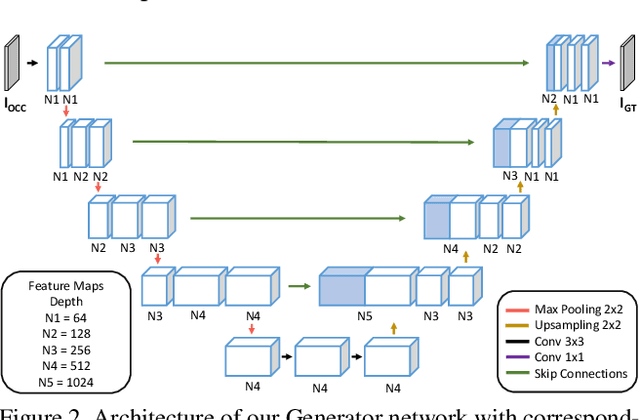

When you see a person in a crowd, occluded by other persons, you miss visual information that can be used to recognize, re-identify or simply classify him or her. You can imagine its appearance given your experience, nothing more. Similarly, AI solutions can try to hallucinate missing information with specific deep learning architectures, suitably trained with people with and without occlusions. The goal of this work is to generate a complete image of a person, given an occluded version in input, that should be a) without occlusion b) similar at pixel level to a completely visible people shape c) capable to conserve similar visual attributes (e.g. male/female) of the original one. For the purpose, we propose a new approach by integrating the state-of-the-art of neural network architectures, namely U-nets and GANs, as well as discriminative attribute classification nets, with an architecture specifically designed to de-occlude people shapes. The network is trained to optimize a Loss function which could take into account the aforementioned objectives. As well we propose two datasets for testing our solution: the first one, occluded RAP, created automatically by occluding real shapes of the RAP dataset (which collects also attributes of the people aspect); the second is a large synthetic dataset, AiC, generated in computer graphics with data extracted from the GTA video game, that contains 3D data of occluded objects by construction. Results are impressive and outperform any other previous proposal. This result could be an initial step to many further researches to recognize people and their behavior in an open crowded world.
Learning to Detect and Track Visible and Occluded Body Joints in a Virtual World
Sep 18, 2018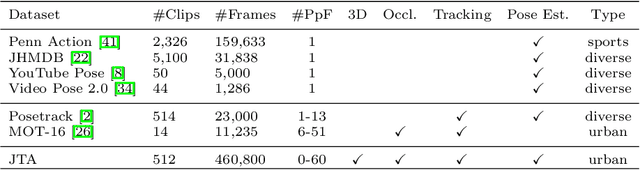


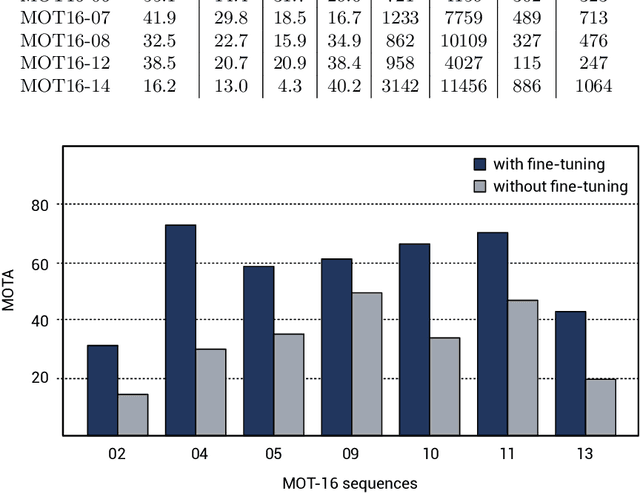
Multi-People Tracking in an open-world setting requires a special effort in precise detection. Moreover, temporal continuity in the detection phase gains more importance when scene cluttering introduces the challenging problems of occluded targets. For the purpose, we propose a deep network architecture that jointly extracts people body parts and associates them across short temporal spans. Our model explicitly deals with occluded body parts, by hallucinating plausible solutions of not visible joints. We propose a new end-to-end architecture composed by four branches (visible heatmaps, occluded heatmaps, part affinity fields and temporal affinity fields) fed by a time linker feature extractor. To overcome the lack of surveillance data with tracking, body part and occlusion annotations we created the vastest Computer Graphics dataset for people tracking in urban scenarios by exploiting a photorealistic videogame. It is up to now the vastest dataset (about 500.000 frames, almost 10 million body poses) of human body parts for people tracking in urban scenarios. Our architecture trained on virtual data exhibits good generalization capabilities also on public real tracking benchmarks, when image resolution and sharpness are high enough, producing reliable tracklets useful for further batch data association or re-id modules.
Face-from-Depth for Head Pose Estimation on Depth Images
Aug 30, 2018
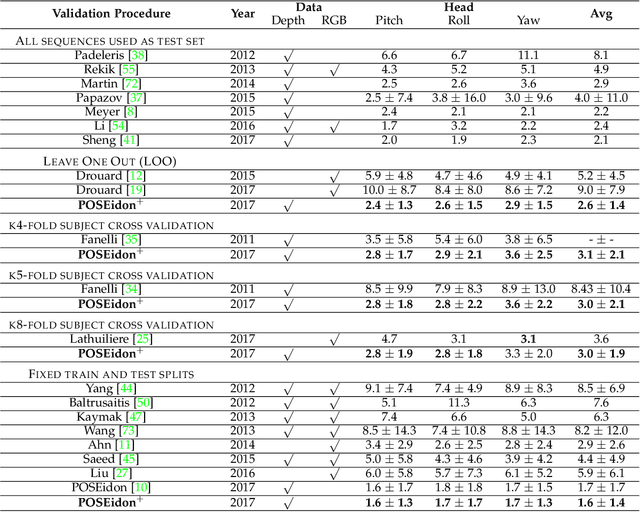


Depth cameras allow to set up reliable solutions for people monitoring and behavior understanding, especially when unstable or poor illumination conditions make unusable common RGB sensors. Therefore, we propose a complete framework for the estimation of the head and shoulder pose based on depth images only. A head detection and localization module is also included, in order to develop a complete end-to-end system. The core element of the framework is a Convolutional Neural Network, called POSEidon+, that receives as input three types of images and provides the 3D angles of the pose as output. Moreover, a Face-from-Depth component based on a Deterministic Conditional GAN model is able to hallucinate a face from the corresponding depth image. We empirically demonstrate that this positively impacts the system performances. We test the proposed framework on two public datasets, namely Biwi Kinect Head Pose and ICT-3DHP, and on Pandora, a new challenging dataset mainly inspired by the automotive setup. Experimental results show that our method overcomes several recent state-of-art works based on both intensity and depth input data, running in real-time at more than 30 frames per second.
Generative Adversarial Models for People Attribute Recognition in Surveillance
Jul 07, 2017



In this paper we propose a deep architecture for detecting people attributes (e.g. gender, race, clothing ...) in surveillance contexts. Our proposal explicitly deal with poor resolution and occlusion issues that often occur in surveillance footages by enhancing the images by means of Deep Convolutional Generative Adversarial Networks (DCGAN). Experiments show that by combining both our Generative Reconstruction and Deep Attribute Classification Network we can effectively extract attributes even when resolution is poor and in presence of strong occlusions up to 80\% of the whole person figure.