 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-Homines: Distance-Based Risk Estimation for Human Safety
Jul 20, 2020



In this document, we report our proposal for modeling the risk of possible contagiousity in a given area monitored by RGB cameras where people freely move and interact. Our system, called Inter-Homines, evaluates in real-time the contagion risk in a monitored area by analyzing video streams: it is able to locate people in 3D space, calculate interpersonal distances and predict risk levels by building dynamic maps of the monitored area. Inter-Homines works both indoor and outdoor, in public and private crowded areas. The software is applicable to already installed cameras or low-cost cameras on industrial PCs, equipped with an additional embedded edge-AI system for temporary measurements. From the AI-side, we exploit a robust pipeline for real-time people detection and localization in the ground plane by homographic transformation based on state-of-the-art computer vision algorithms; it is a combination of a people detector and a pose estimator. From the risk modeling side, we propose a parametric model for a spatio-temporal dynamic risk estimation, that, validated by epidemiologists, could be useful for safety monitoring the acceptance of social distancing prevention measures by predicting the risk level of the scene.
Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation
Apr 01, 2020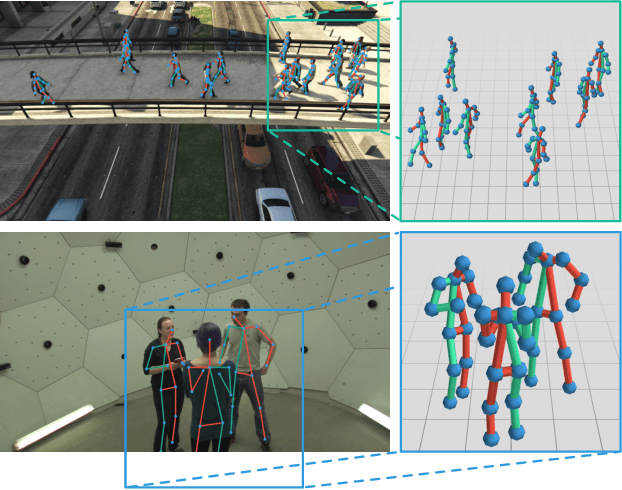
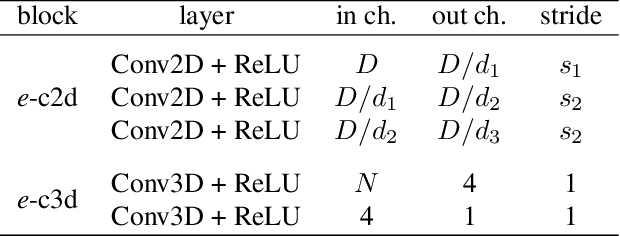
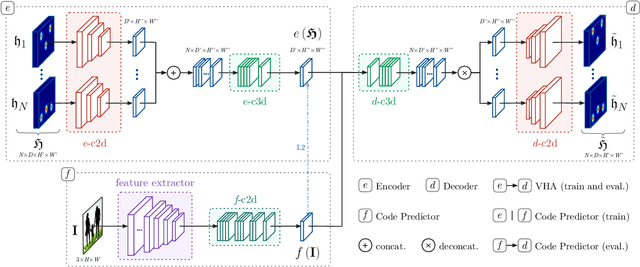

In this paper we present a novel approach for bottom-up multi-person 3D human pose estimation from monocular RGB images. We propose to use high resolution volumetric heatmaps to model joint locations, devising a simple and effective compression method to drastically reduce the size of this representation. At the core of the proposed method lies our Volumetric Heatmap Autoencoder, a fully-convolutional network tasked with the compression of ground-truth heatmaps into a dense intermediate representation. A second model, the Code Predictor, is then trained to predict these codes, which can be decompressed at test time to re-obtain the original representation. Our experimental evaluation shows that our method performs favorably when compared to state of the art on both multi-person and single-person 3D human pose estimation datasets and, thanks to our novel compression strategy, can process full-HD images at the constant runtime of 8 fps regardless of the number of subjects in the scene. Code and models available at https://github.com/fabbrimatteo/LoCO .
Domain Translation with Conditional GANs: from Depth to RGB Face-to-Face
Jan 23, 2019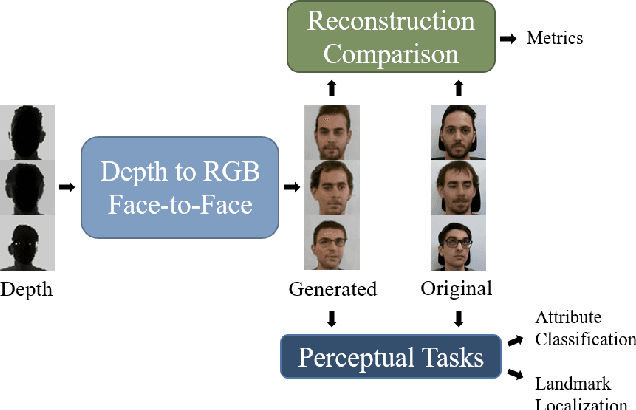
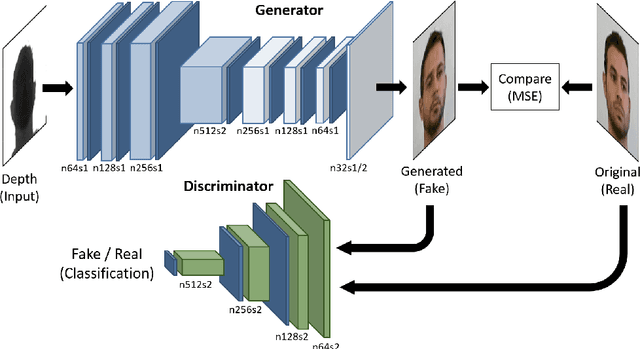


Can faces acquired by low-cost depth sensors be useful to catch some characteristic details of the face? Typically the answer is no. However, new deep architectures can generate RGB images from data acquired in a different modality, such as depth data. In this paper, we propose a new \textit{Deterministic Conditional GAN}, trained on annotated RGB-D face datasets, effective for a face-to-face translation from depth to RGB. Although the network cannot reconstruct the exact somatic features for unknown individual faces, it is capable to reconstruct plausible faces; their appearance is accurate enough to be used in many pattern recognition tasks. In fact, we test the network capability to hallucinate with some \textit{Perceptual Probes}, as for instance face aspect classification or landmark detection. Depth face can be used in spite of the correspondent RGB images, that often are not available due to difficult luminance conditions. Experimental results are very promising and are as far as better than previously proposed approaches: this domain translation can constitute a new way to exploit depth data in new future applications.
Learning to Detect and Track Visible and Occluded Body Joints in a Virtual World
Sep 18, 2018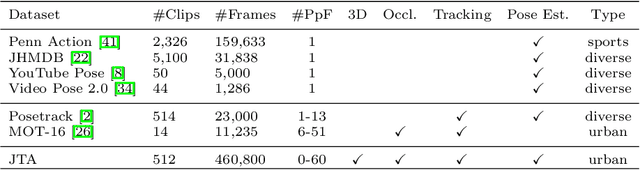


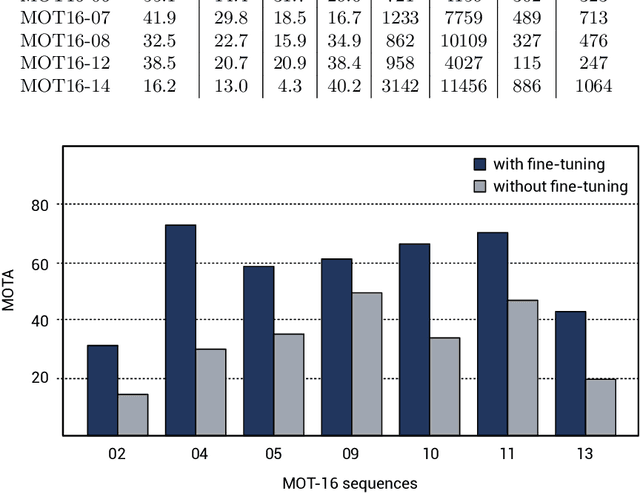
Multi-People Tracking in an open-world setting requires a special effort in precise detection. Moreover, temporal continuity in the detection phase gains more importance when scene cluttering introduces the challenging problems of occluded targets. For the purpose, we propose a deep network architecture that jointly extracts people body parts and associates them across short temporal spans. Our model explicitly deals with occluded body parts, by hallucinating plausible solutions of not visible joints. We propose a new end-to-end architecture composed by four branches (visible heatmaps, occluded heatmaps, part affinity fields and temporal affinity fields) fed by a time linker feature extractor. To overcome the lack of surveillance data with tracking, body part and occlusion annotations we created the vastest Computer Graphics dataset for people tracking in urban scenarios by exploiting a photorealistic videogame. It is up to now the vastest dataset (about 500.000 frames, almost 10 million body poses) of human body parts for people tracking in urban scenarios. Our architecture trained on virtual data exhibits good generalization capabilities also on public real tracking benchmarks, when image resolution and sharpness are high enough, producing reliable tracklets useful for further batch data association or re-id modules.