 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Urban Scenes Generation Through Vehicles Synthesis
Jul 01, 2020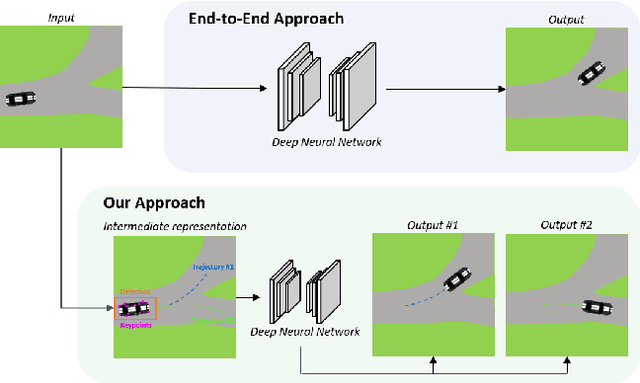
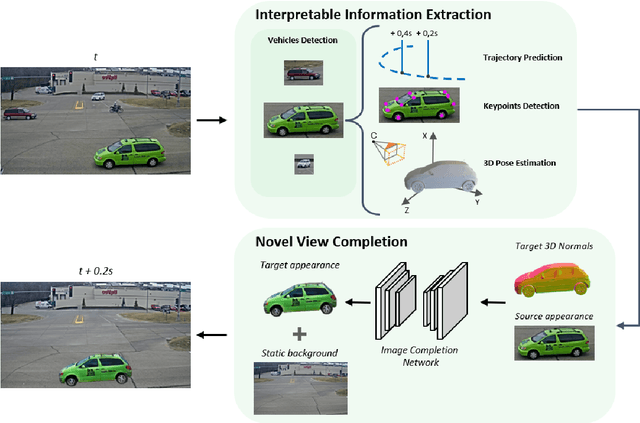

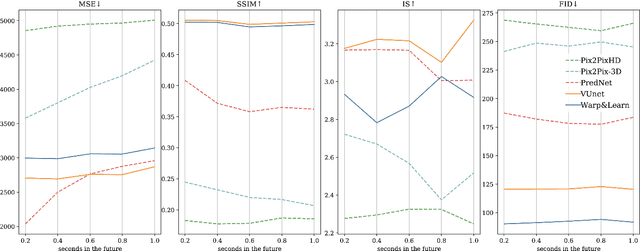
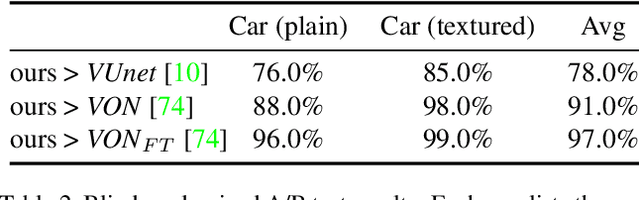
In this work we propose a deep learning pipeline to predict the visual future appearance of an urban scene. Despite recent advances, generating the entire scene in an end-to-end fashion is still far from being achieved. Instead, here we follow a two stages approach, where interpretable information is included in the loop and each actor is modelled independently. We leverage a per-object novel view synthesis paradigm; i.e. generating a synthetic representation of an object undergoing a geometrical roto-translation in the 3D space. Our model can be easily conditioned with constraints (e.g. input trajectories) provided by state-of-the-art tracking methods or by the user itself. This allows us to generate a set of diverse realistic futures starting from the same input in a multi-modal fashion. We visually and quantitatively show the superiority of this approach over traditional end-to-end scene-generation methods on CityFlow, a challenging real world dataset.
Semi-parametric Object Synthesis
Jul 24, 2019

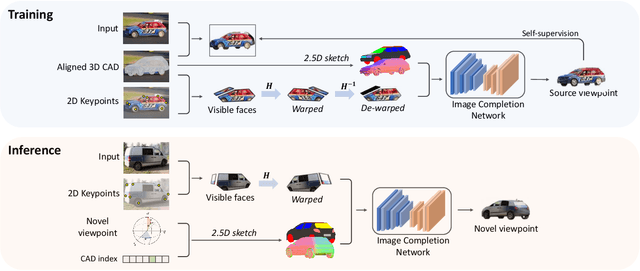
We present a new semi-parametric approach to synthesize novel views of an object from a single monocular image. First, we exploit man-made object symmetry and piece-wise planarity to integrate rich a-priori visual information into the novel viewpoint synthesis process. An Image Completion Network (ICN) then leverages 2.5D sketches rendered from a 3D CAD as guidance to generate a realistic image. In contrast to concurrent works, we do not rely solely on synthetic data but leverage instead existing datasets for 3D object detection to operate in a real-world scenario. Differently from competitors, our semi-parametric framework allows the handling of a wide range of 3D transformations. Thorough experimental analysis against state-of-the-art baselines shows the efficacy of our method both from a quantitative and a perceptive point of view. Code and supplementary material are available at: https://github.com/ndrplz/semiparametric
Learning to Detect and Track Visible and Occluded Body Joints in a Virtual World
Sep 18, 2018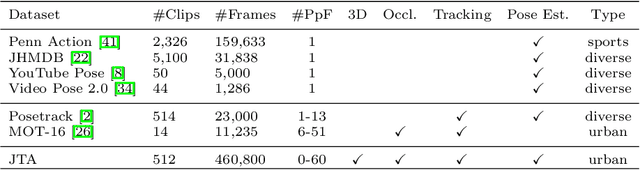


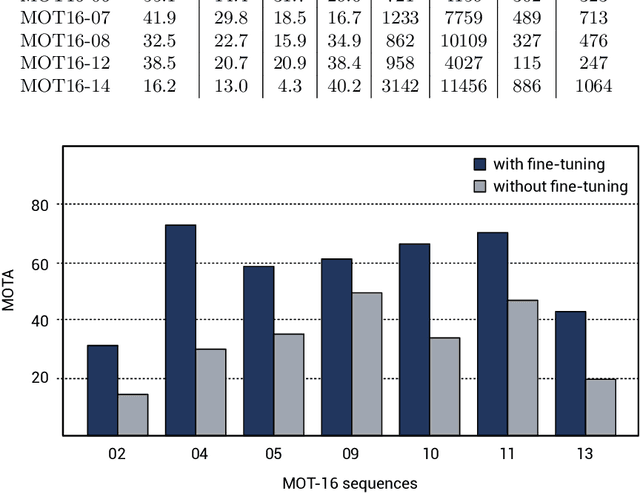
Multi-People Tracking in an open-world setting requires a special effort in precise detection. Moreover, temporal continuity in the detection phase gains more importance when scene cluttering introduces the challenging problems of occluded targets. For the purpose, we propose a deep network architecture that jointly extracts people body parts and associates them across short temporal spans. Our model explicitly deals with occluded body parts, by hallucinating plausible solutions of not visible joints. We propose a new end-to-end architecture composed by four branches (visible heatmaps, occluded heatmaps, part affinity fields and temporal affinity fields) fed by a time linker feature extractor. To overcome the lack of surveillance data with tracking, body part and occlusion annotations we created the vastest Computer Graphics dataset for people tracking in urban scenarios by exploiting a photorealistic videogame. It is up to now the vastest dataset (about 500.000 frames, almost 10 million body poses) of human body parts for people tracking in urban scenarios. Our architecture trained on virtual data exhibits good generalization capabilities also on public real tracking benchmarks, when image resolution and sharpness are high enough, producing reliable tracklets useful for further batch data association or re-id modules.
Predicting the Driver's Focus of Attention: the DRVE Project
Jun 06, 2018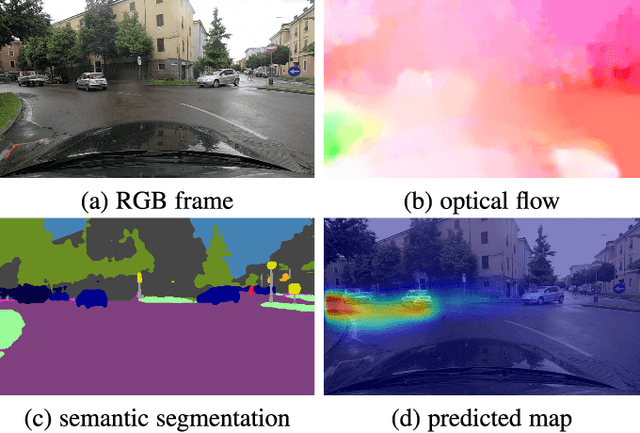



In this work we aim to predict the driver's focus of attention. The goal is to estimate what a person would pay attention to while driving, and which part of the scene around the vehicle is more critical for the task. To this end we propose a new computer vision model based on a multi-branch deep architecture that integrates three sources of information: raw video, motion and scene semantics. We also introduce DR(eye)VE, the largest dataset of driving scenes for which eye-tracking annotations are available. This dataset features more than 500,000 registered frames, matching ego-centric views (from glasses worn by drivers) and car-centric views (from roof-mounted camera), further enriched by other sensors measurements. Results highlight that several attention patterns are shared across drivers and can be reproduced to some extent. The indication of which elements in the scene are likely to capture the driver's attention may benefit several applications in the context of human-vehicle interaction and driver attention analysis.
Learning to Map Vehicles into Bird's Eye View
Jun 26, 2017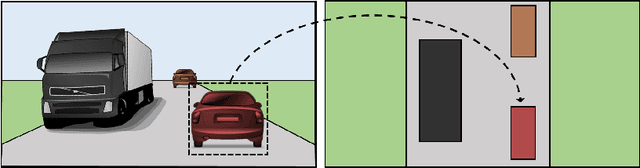

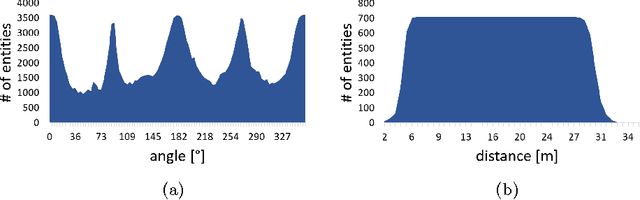
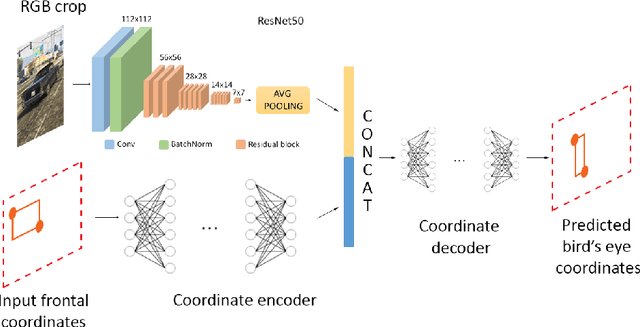
Awareness of the road scene is an essential component for both autonomous vehicles and Advances Driver Assistance Systems and is gaining importance both for the academia and car companies. This paper presents a way to learn a semantic-aware transformation which maps detections from a dashboard camera view onto a broader bird's eye occupancy map of the scene. To this end, a huge synthetic dataset featuring 1M couples of frames, taken from both car dashboard and bird's eye view, has been collected and automatically annotated. A deep-network is then trained to warp detections from the first to the second view. We demonstrate the effectiveness of our model against several baselines and observe that is able to generalize on real-world data despite having been trained solely on synthetic ones.
Learning Where to Attend Like a Human Driver
May 09, 2017
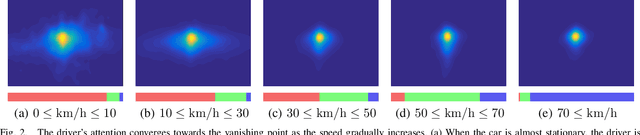


Despite the advent of autonomous cars, it's likely - at least in the near future - that human attention will still maintain a central role as a guarantee in terms of legal responsibility during the driving task. In this paper we study the dynamics of the driver's gaze and use it as a proxy to understand related attentional mechanisms. First, we build our analysis upon two questions: where and what the driver is looking at? Second, we model the driver's gaze by training a coarse-to-fine convolutional network on short sequences extracted from the DR(eye)VE dataset. Experimental comparison against different baselines reveal that the driver's gaze can indeed be learnt to some extent, despite i) being highly subjective and ii) having only one driver's gaze available for each sequence due to the irreproducibility of the scene. Eventually, we advocate for a new assisted driving paradigm which suggests to the driver, with no intervention, where she should focus her attention.
A Statistical Test for Joint Distributions Equivalence
Jul 25, 2016

We provide a distribution-free test that can be used to determine whether any two joint distributions $p$ and $q$ are statistically different by inspection of a large enough set of samples. Following recent efforts from Long et al. [1], we rely on joint kernel distribution embedding to extend the kernel two-sample test of Gretton et al. [2] to the case of joint probability distributions. Our main result can be directly applied to verify if a dataset-shift has occurred between training and test distributions in a learning framework, without further assuming the shift has occurred only in the input, in the target or in the conditional distribution.