 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Where to Attend Like a Human Driver
Paper and Code

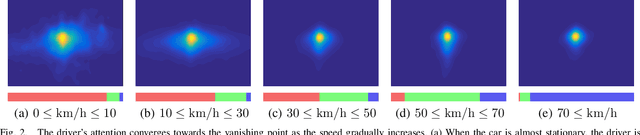


Despite the advent of autonomous cars, it's likely - at least in the near future - that human attention will still maintain a central role as a guarantee in terms of legal responsibility during the driving task. In this paper we study the dynamics of the driver's gaze and use it as a proxy to understand related attentional mechanisms. First, we build our analysis upon two questions: where and what the driver is looking at? Second, we model the driver's gaze by training a coarse-to-fine convolutional network on short sequences extracted from the DR(eye)VE dataset. Experimental comparison against different baselines reveal that the driver's gaze can indeed be learnt to some extent, despite i) being highly subjective and ii) having only one driver's gaze available for each sequence due to the irreproducibility of the scene. Eventually, we advocate for a new assisted driving paradigm which suggests to the driver, with no intervention, where she should focus her attention.