 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Driver's Focus of Attention: the DRVE Project
Jun 06, 2018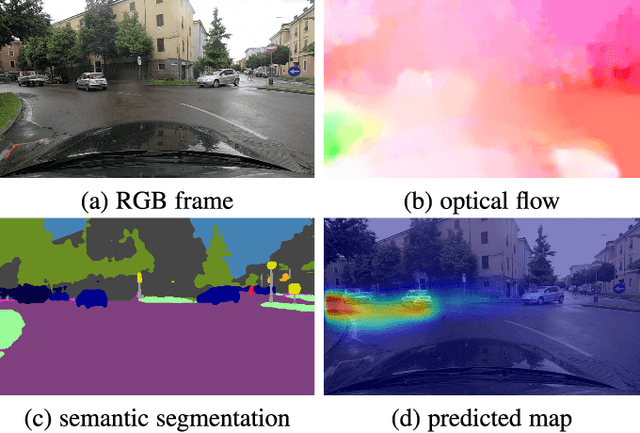



In this work we aim to predict the driver's focus of attention. The goal is to estimate what a person would pay attention to while driving, and which part of the scene around the vehicle is more critical for the task. To this end we propose a new computer vision model based on a multi-branch deep architecture that integrates three sources of information: raw video, motion and scene semantics. We also introduce DR(eye)VE, the largest dataset of driving scenes for which eye-tracking annotations are available. This dataset features more than 500,000 registered frames, matching ego-centric views (from glasses worn by drivers) and car-centric views (from roof-mounted camera), further enriched by other sensors measurements. Results highlight that several attention patterns are shared across drivers and can be reproduced to some extent. The indication of which elements in the scene are likely to capture the driver's attention may benefit several applications in the context of human-vehicle interaction and driver attention analysis.
Learning Where to Attend Like a Human Driver
May 09, 2017
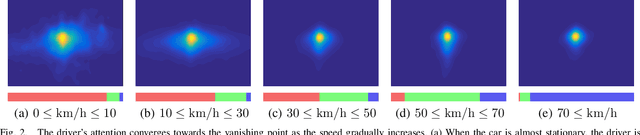


Despite the advent of autonomous cars, it's likely - at least in the near future - that human attention will still maintain a central role as a guarantee in terms of legal responsibility during the driving task. In this paper we study the dynamics of the driver's gaze and use it as a proxy to understand related attentional mechanisms. First, we build our analysis upon two questions: where and what the driver is looking at? Second, we model the driver's gaze by training a coarse-to-fine convolutional network on short sequences extracted from the DR(eye)VE dataset. Experimental comparison against different baselines reveal that the driver's gaze can indeed be learnt to some extent, despite i) being highly subjective and ii) having only one driver's gaze available for each sequence due to the irreproducibility of the scene. Eventually, we advocate for a new assisted driving paradigm which suggests to the driver, with no intervention, where she should focus her attention.
Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking
Sep 19, 2016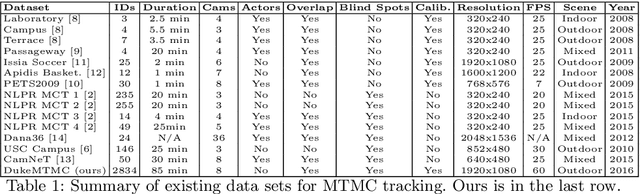


To help accelerate progress in multi-target, multi-camera tracking systems, we present (i) a new pair of precision-recall measures of performance that treats errors of all types uniformly and emphasizes correct identification over sources of error; (ii) the largest fully-annotated and calibrated data set to date with more than 2 million frames of 1080p, 60fps video taken by 8 cameras observing more than 2,700 identities over 85 minutes; and (iii) a reference software system as a comparison baseline. We show that (i) our measures properly account for bottom-line identity match performance in the multi-camera setting; (ii) our data set poses realistic challenges to current trackers; and (iii) the performance of our system is comparable to the state of the art.
A Statistical Test for Joint Distributions Equivalence
Jul 25, 2016

We provide a distribution-free test that can be used to determine whether any two joint distributions $p$ and $q$ are statistically different by inspection of a large enough set of samples. Following recent efforts from Long et al. [1], we rely on joint kernel distribution embedding to extend the kernel two-sample test of Gretton et al. [2] to the case of joint probability distributions. Our main result can be directly applied to verify if a dataset-shift has occurred between training and test distributions in a learning framework, without further assuming the shift has occurred only in the input, in the target or in the conditional distribution.
Learning to Divide and Conquer for Online Multi-Target Tracking
Sep 14, 2015



Online Multiple Target Tracking (MTT) is often addressed within the tracking-by-detection paradigm. Detections are previously extracted independently in each frame and then objects trajectories are built by maximizing specifically designed coherence functions. Nevertheless, ambiguities arise in presence of occlusions or detection errors. In this paper we claim that the ambiguities in tracking could be solved by a selective use of the features, by working with more reliable features if possible and exploiting a deeper representation of the target only if necessary. To this end, we propose an online divide and conquer tracker for static camera scenes, which partitions the assignment problem in local subproblems and solves them by selectively choosing and combining the best features. The complete framework is cast as a structural learning task that unifies these phases and learns tracker parameters from examples. Experiments on two different datasets highlights a significant improvement of tracking performances (MOTA +10%) over the state of the art.
Socially Constrained Structural Learning for Groups Detection in Crowd
Aug 06, 2015



Modern crowd theories agree that collective behavior is the result of the underlying interactions among small groups of individuals. In this work, we propose a novel algorithm for detecting social groups in crowds by means of a Correlation Clustering procedure on people trajectories. The affinity between crowd members is learned through an online formulation of the Structural SVM framework and a set of specifically designed features characterizing both their physical and social identity, inspired by Proxemic theory, Granger causality, DTW and Heat-maps. To adhere to sociological observations, we introduce a loss function (G-MITRE) able to deal with the complexity of evaluating group detection performances. We show our algorithm achieves state-of-the-art results when relying on both ground truth trajectories and tracklets previously extracted by available detector/tracker systems.