 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Driver's Focus of Attention: the DRVE Project
Paper and Code
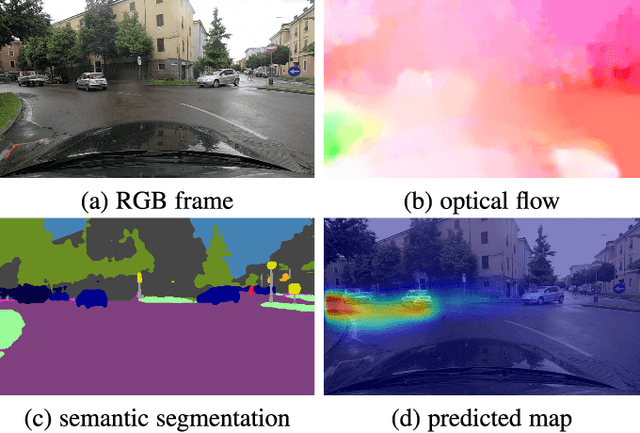



In this work we aim to predict the driver's focus of attention. The goal is to estimate what a person would pay attention to while driving, and which part of the scene around the vehicle is more critical for the task. To this end we propose a new computer vision model based on a multi-branch deep architecture that integrates three sources of information: raw video, motion and scene semantics. We also introduce DR(eye)VE, the largest dataset of driving scenes for which eye-tracking annotations are available. This dataset features more than 500,000 registered frames, matching ego-centric views (from glasses worn by drivers) and car-centric views (from roof-mounted camera), further enriched by other sensors measurements. Results highlight that several attention patterns are shared across drivers and can be reproduced to some extent. The indication of which elements in the scene are likely to capture the driver's attention may benefit several applications in the context of human-vehicle interaction and driver attention analysis.