Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Q-Learning Provably Efficient? An Extended Analysis
Paper and Code
Sep 22, 2020
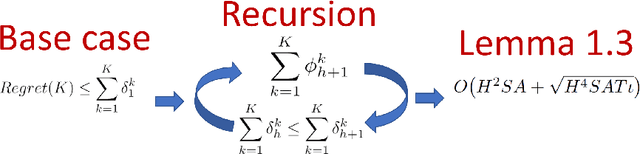

This work extends the analysis of the theoretical results presented within the paper Is Q-Learning Provably Efficient? by Jin et al. We include a survey of related research to contextualize the need for strengthening the theoretical guarantees related to perhaps the most important threads of model-free reinforcement learning. We also expound upon the reasoning used in the proofs to highlight the critical steps leading to the main result showing that Q-learning with UCB exploration achieves a sample efficiency that matches the optimal regret that can be achieved by any model-based approach.
View paper on