 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse and Privacy-enhanced Representation for Human Pose Estimation
Sep 18, 2023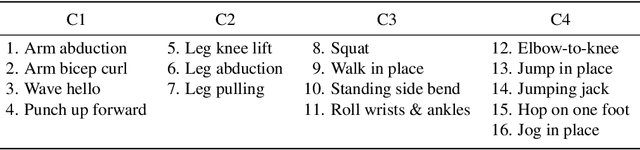
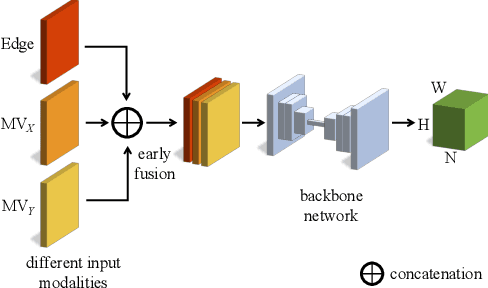
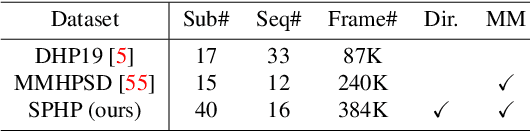
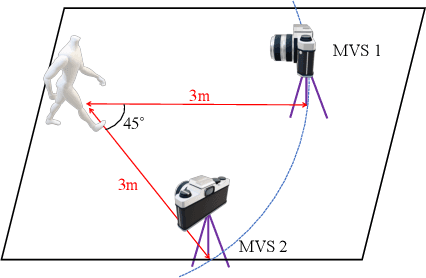
We propose a sparse and privacy-enhanced representation for Human Pose Estimation (HPE). Given a perspective camera, we use a proprietary motion vector sensor(MVS) to extract an edge image and a two-directional motion vector image at each time frame. Both edge and motion vector images are sparse and contain much less information (i.e., enhancing human privacy). We advocate that edge information is essential for HPE, and motion vectors complement edge information during fast movements. We propose a fusion network leveraging recent advances in sparse convolution used typically for 3D voxels to efficiently process our proposed sparse representation, which achieves about 13x speed-up and 96% reduction in FLOPs. We collect an in-house edge and motion vector dataset with 16 types of actions by 40 users using the proprietary MVS. Our method outperforms individual modalities using only edge or motion vector images. Finally, we validate the privacy-enhanced quality of our sparse representation through face recognition on CelebA (a large face dataset) and a user study on our in-house dataset.