 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNNAccel: A Fusion Recurrent Neural Network Accelerator for Edge Intelligence
Oct 26, 2020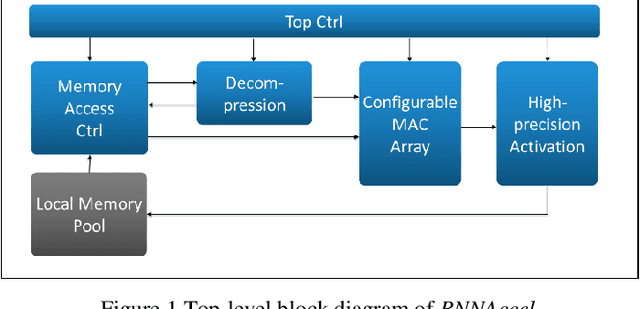
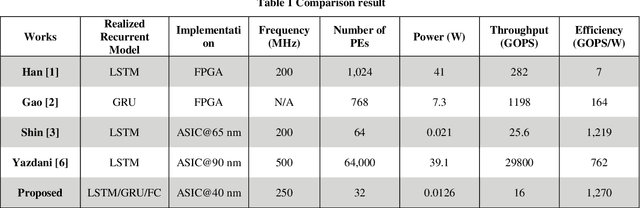
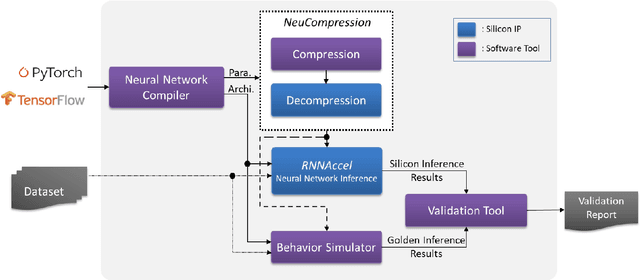
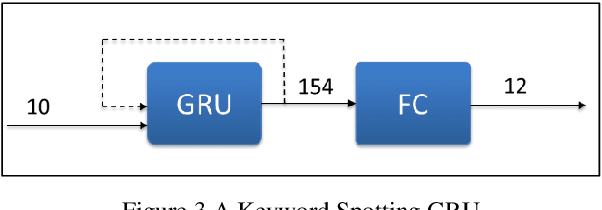
Many edge devices employ Recurrent Neural Networks (RNN) to enhance their product intelligence. However, the increasing computation complexity poses challenges for performance, energy efficiency and product development time. In this paper, we present an RNN deep learning accelerator, called RNNAccel, which supports Long Short-Term Memory (LSTM) network, Gated Recurrent Unit (GRU) network, and Fully Connected Layer (FC)/ Multiple-Perceptron Layer (MLP) networks. This RNN accelerator addresses (1) computing unit utilization bottleneck caused by RNN data dependency, (2) inflexible design for specific applications, (3) energy consumption dominated by memory access, (4) accuracy loss due to coefficient compression, and (5) unpredictable performance resulting from processor-accelerator integration. Our proposed RNN accelerator consists of a configurable 32-MAC array and a coefficient decompression engine. The MAC array can be scaled-up to meet throughput requirement and power budget. Its sophisticated off-line compression and simple hardware-friendly on-line decompression, called NeuCompression, reduces memory footprint up to 16x and decreases memory access power. Furthermore, for easy SOC integration, we developed a tool set for bit-accurate simulation and integration result validation. Evaluated using a keyword spotting application, the 32-MAC RNN accelerator achieves 90% MAC utilization, 1.27 TOPs/W at 40nm process, 8x compression ratio, and 90% inference accuracy.
HarDNet: A Low Memory Traffic Network
Sep 03, 2019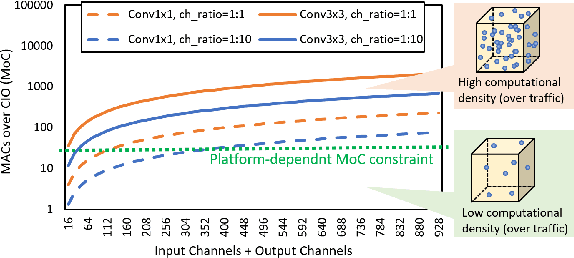
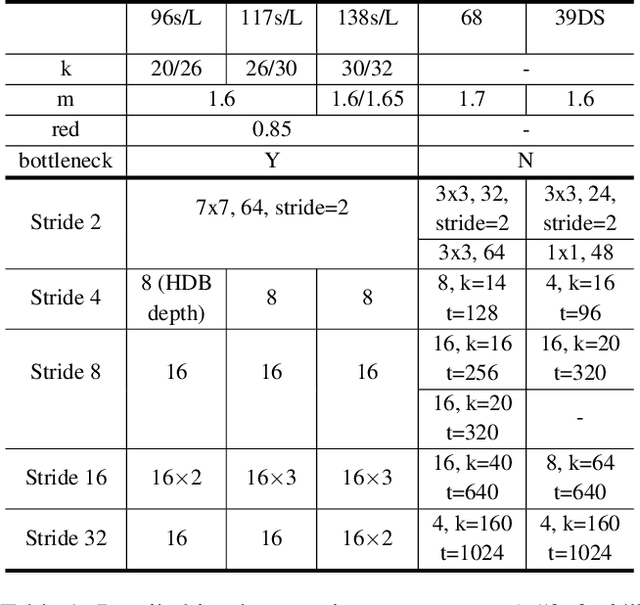
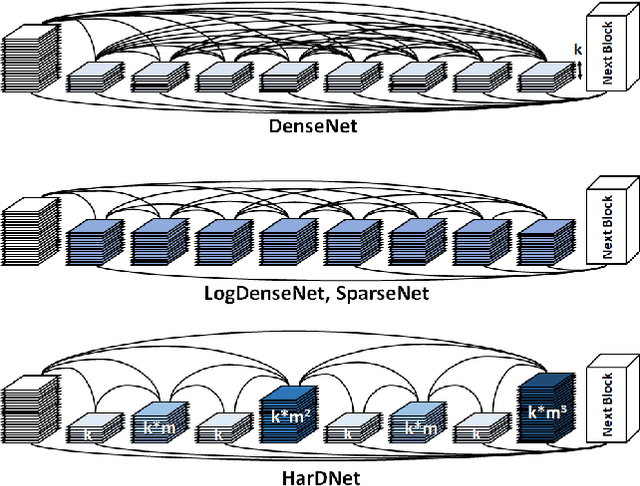
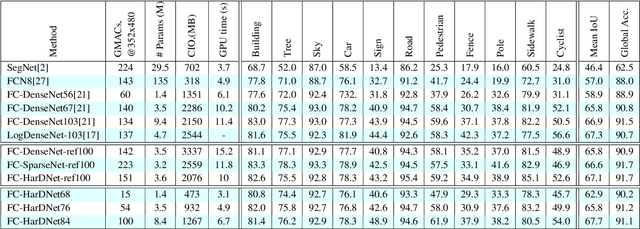
State-of-the-art neural network architectures such as ResNet, MobileNet, and DenseNet have achieved outstanding accuracy over low MACs and small model size counterparts. However, these metrics might not be accurate for predicting the inference time. We suggest that memory traffic for accessing intermediate feature maps can be a factor dominating the inference latency, especially in such tasks as real-time object detection and semantic segmentation of high-resolution video. We propose a Harmonic Densely Connected Network to achieve high efficiency in terms of both low MACs and memory traffic. The new network achieves 35%, 36%, 30%, 32%, and 45% inference time reduction compared with FC-DenseNet-103, DenseNet-264, ResNet-50, ResNet-152, and SSD-VGG, respectively. We use tools including Nvidia profiler and ARM Scale-Sim to measure the memory traffic and verify that the inference latency is indeed proportional to the memory traffic consumption and the proposed network consumes low memory traffic. We conclude that one should take memory traffic into consideration when designing neural network architectures for high-resolution applications at the edge.