 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNNAccel: A Fusion Recurrent Neural Network Accelerator for Edge Intelligence
Oct 26, 2020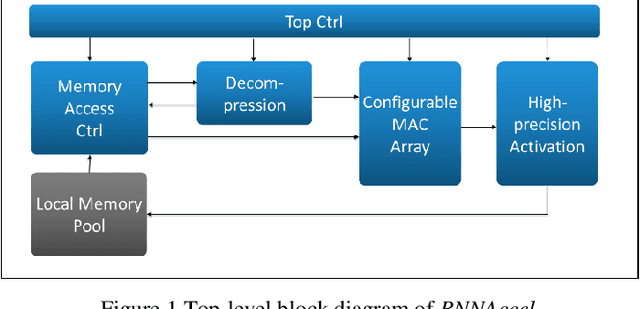
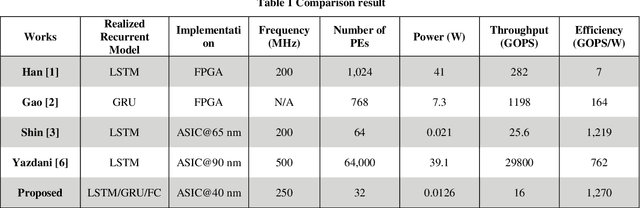
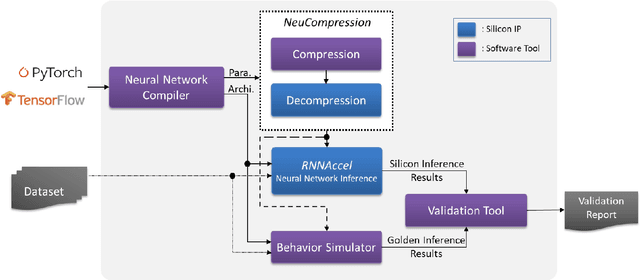
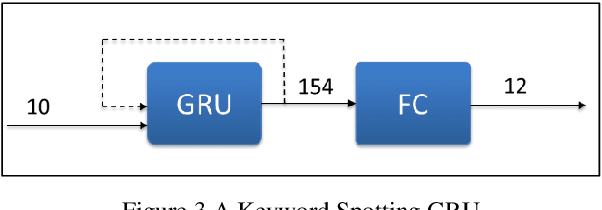
Many edge devices employ Recurrent Neural Networks (RNN) to enhance their product intelligence. However, the increasing computation complexity poses challenges for performance, energy efficiency and product development time. In this paper, we present an RNN deep learning accelerator, called RNNAccel, which supports Long Short-Term Memory (LSTM) network, Gated Recurrent Unit (GRU) network, and Fully Connected Layer (FC)/ Multiple-Perceptron Layer (MLP) networks. This RNN accelerator addresses (1) computing unit utilization bottleneck caused by RNN data dependency, (2) inflexible design for specific applications, (3) energy consumption dominated by memory access, (4) accuracy loss due to coefficient compression, and (5) unpredictable performance resulting from processor-accelerator integration. Our proposed RNN accelerator consists of a configurable 32-MAC array and a coefficient decompression engine. The MAC array can be scaled-up to meet throughput requirement and power budget. Its sophisticated off-line compression and simple hardware-friendly on-line decompression, called NeuCompression, reduces memory footprint up to 16x and decreases memory access power. Furthermore, for easy SOC integration, we developed a tool set for bit-accurate simulation and integration result validation. Evaluated using a keyword spotting application, the 32-MAC RNN accelerator achieves 90% MAC utilization, 1.27 TOPs/W at 40nm process, 8x compression ratio, and 90% inference accuracy.