 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardFlow: Topology-Aware Reward Propagation on State Graphs for Agentic RL with Large Language Models
Mar 19, 2026Reinforcement learning (RL) holds significant promise for enhancing the agentic reasoning capabilities of large language models (LLMs) with external environments. However, the inherent sparsity of terminal rewards hinders fine-grained, state-level optimization. Although process reward modeling offers a promising alternative, training dedicated reward models often entails substantial computational costs and scaling difficulties. To address these challenges, we introduce RewardFlow, a lightweight method for estimating state-level rewards tailored to agentic reasoning tasks. RewardFlow leverages the intrinsic topological structure of states within reasoning trajectories by constructing state graphs. This enables an analysis of state-wise contributions to success, followed by topology-aware graph propagation to quantify contributions and yield objective, state-level rewards. When integrated as dense rewards for RL optimization, RewardFlow substantially outperforms prior RL baselines across four agentic reasoning benchmarks, demonstrating superior performance, robustness, and training efficiency. The implementation of RewardFlow is publicly available at https://github.com/tmlr-group/RewardFlow.
HMVLA: Hyperbolic Multimodal Fusion for Vision-Language-Action Models
Jan 28, 2026Vision Language Action (VLA) models have recently shown great potential in bridging multimodal perception with robotic control. However, existing methods often rely on direct fine-tuning of pre-trained Vision-Language Models (VLMs), feeding semantic and visual features directly into a policy network without fully addressing the unique semantic alignment challenges in the VLA domain. In this paper, we propose HMVLA, a novel VLA framework that exploits the inherent hierarchical structures in vision and language for comprehensive semantic alignment. Unlike traditional methods that perform alignment in Euclidean space, our HMVLA embeds multimodal features in hyperbolic space, enabling more effective modeling of the hierarchical relationships present in image text data. Furthermore, we introduce a sparsely gated Mixture of Experts (MoE) mechanism tailored for semantic alignment, which enhances multimodal comprehension between images and text while improving efficiency. Extensive experiments demonstrate that HMVLA surpasses baseline methods in both accuracy and generalization. In addition, we validate its robustness by reconstructing datasets to further test cross domain adaptability.
Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges
Oct 22, 2025Tibetan, one of the major low-resource languages in Asia, presents unique linguistic and sociocultural characteristics that pose both challenges and opportunities for AI research. Despite increasing interest in developing AI systems for underrepresented languages, Tibetan has received limited attention due to a lack of accessible data resources, standardized benchmarks, and dedicated tools. This paper provides a comprehensive survey of the current state of Tibetan AI in the AI domain, covering textual and speech data resources, NLP tasks, machine translation, speech recognition, and recent developments in LLMs. We systematically categorize existing datasets and tools, evaluate methods used across different tasks, and compare performance where possible. We also identify persistent bottlenecks such as data sparsity, orthographic variation, and the lack of unified evaluation metrics. Additionally, we discuss the potential of cross-lingual transfer, multi-modal learning, and community-driven resource creation. This survey aims to serve as a foundational reference for future work on Tibetan AI research and encourages collaborative efforts to build an inclusive and sustainable AI ecosystem for low-resource languages.
RLMR: Reinforcement Learning with Mixed Rewards for Creative Writing
Aug 28, 2025
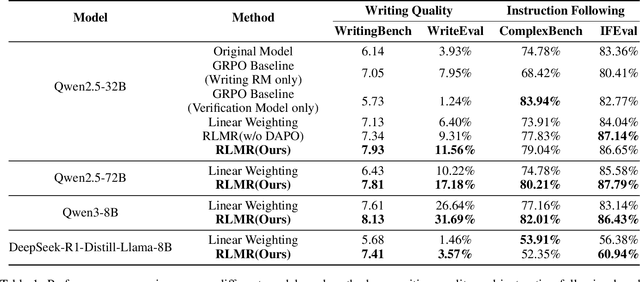
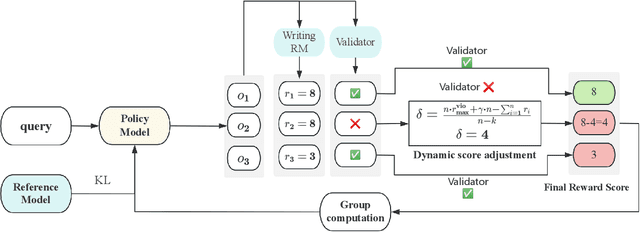
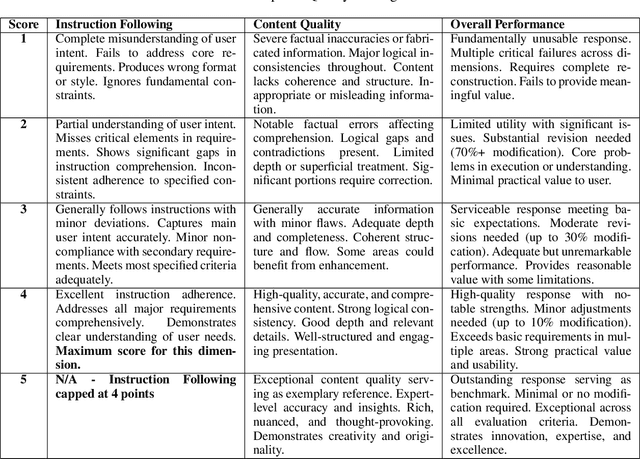
Large language models are extensively utilized in creative writing applications. Creative writing requires a balance between subjective writing quality (e.g., literariness and emotional expression) and objective constraint following (e.g., format requirements and word limits). Existing methods find it difficult to balance these two aspects: single reward strategies fail to improve both abilities simultaneously, while fixed-weight mixed-reward methods lack the ability to adapt to different writing scenarios. To address this problem, we propose Reinforcement Learning with Mixed Rewards (RLMR), utilizing a dynamically mixed reward system from a writing reward model evaluating subjective writing quality and a constraint verification model assessing objective constraint following. The constraint following reward weight is adjusted dynamically according to the writing quality within sampled groups, ensuring that samples violating constraints get negative advantage in GRPO and thus penalized during training, which is the key innovation of this proposed method. We conduct automated and manual evaluations across diverse model families from 8B to 72B parameters. Additionally, we construct a real-world writing benchmark named WriteEval for comprehensive evaluation. Results illustrate that our method achieves consistent improvements in both instruction following (IFEval from 83.36% to 86.65%) and writing quality (72.75% win rate in manual expert pairwise evaluations on WriteEval). To the best of our knowledge, RLMR is the first work to combine subjective preferences with objective verification in online RL training, providing an effective solution for multi-dimensional creative writing optimization.
From Passive to Active Reasoning: Can Large Language Models Ask the Right Questions under Incomplete Information?
Jun 09, 2025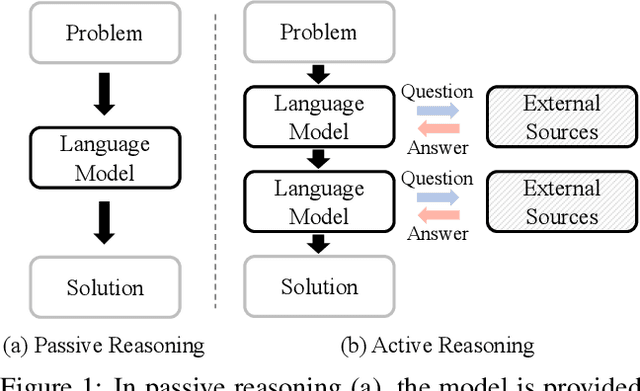
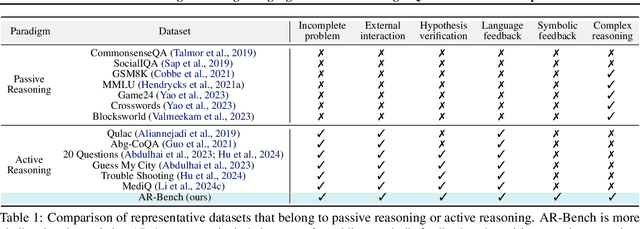
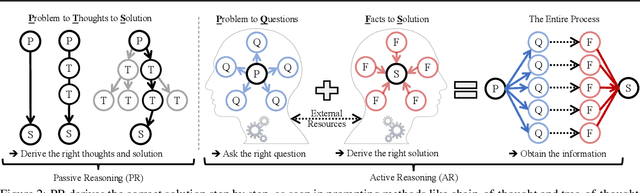

While existing benchmarks probe the reasoning abilities of large language models (LLMs) across diverse domains, they predominantly assess passive reasoning, providing models with all the information needed to reach a solution. By contrast, active reasoning-where an LLM must interact with external systems to acquire missing evidence or data-has received little systematic attention. To address this shortfall, we present AR-Bench, a novel benchmark designed explicitly to evaluate an LLM's active reasoning skills. AR-Bench comprises three task families-detective cases, situation puzzles, and guessing numbers-that together simulate real-world, agentic scenarios and measure performance across commonsense, logical, and symbolic reasoning challenges. Empirical evaluation on AR-Bench demonstrates that contemporary LLMs exhibit pronounced difficulties with active reasoning: they frequently fail to acquire or leverage the information needed to solve tasks. This gap highlights a stark divergence between their passive and active reasoning abilities. Moreover, ablation studies indicate that even advanced strategies, such as tree-based searching or post-training approaches, yield only modest gains and fall short of the levels required for real-world deployment. Collectively, these findings highlight the critical need to advance methodology for active reasoning, e.g., incorporating interactive learning, real-time feedback loops, and environment-aware objectives for training. The benchmark is publicly available at: https://github.com/tmlr-group/AR-Bench.
$C^3$-Bench: The Things Real Disturbing LLM based Agent in Multi-Tasking
May 24, 2025Agents based on large language models leverage tools to modify environments, revolutionizing how AI interacts with the physical world. Unlike traditional NLP tasks that rely solely on historical dialogue for responses, these agents must consider more complex factors, such as inter-tool relationships, environmental feedback and previous decisions, when making choices. Current research typically evaluates agents via multi-turn dialogues. However, it overlooks the influence of these critical factors on agent behavior. To bridge this gap, we present an open-source and high-quality benchmark $C^3$-Bench. This benchmark integrates attack concepts and applies univariate analysis to pinpoint key elements affecting agent robustness. In concrete, we design three challenges: navigate complex tool relationships, handle critical hidden information and manage dynamic decision paths. Complementing these challenges, we introduce fine-grained metrics, innovative data collection algorithms and reproducible evaluation methods. Extensive experiments are conducted on 49 mainstream agents, encompassing general fast-thinking, slow-thinking and domain-specific models. We observe that agents have significant shortcomings in handling tool dependencies, long context information dependencies and frequent policy-type switching. In essence, $C^3$-Bench aims to expose model vulnerabilities through these challenges and drive research into the interpretability of agent performance. The benchmark is publicly available at https://github.com/yupeijei1997/C3-Bench.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Multi-Mission Tool Bench: Assessing the Robustness of LLM based Agents through Related and Dynamic Missions
Apr 03, 2025Large language models (LLMs) demonstrate strong potential as agents for tool invocation due to their advanced comprehension and planning capabilities. Users increasingly rely on LLM-based agents to solve complex missions through iterative interactions. However, existing benchmarks predominantly access agents in single-mission scenarios, failing to capture real-world complexity. To bridge this gap, we propose the Multi-Mission Tool Bench. In the benchmark, each test case comprises multiple interrelated missions. This design requires agents to dynamically adapt to evolving demands. Moreover, the proposed benchmark explores all possible mission-switching patterns within a fixed mission number. Specifically, we propose a multi-agent data generation framework to construct the benchmark. We also propose a novel method to evaluate the accuracy and efficiency of agent decisions with dynamic decision trees. Experiments on diverse open-source and closed-source LLMs reveal critical factors influencing agent robustness and provide actionable insights to the tool invocation society.
Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models
Mar 28, 2025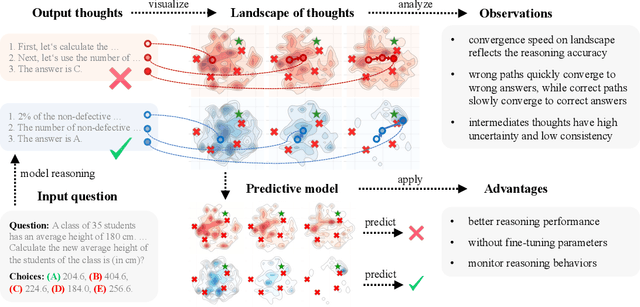
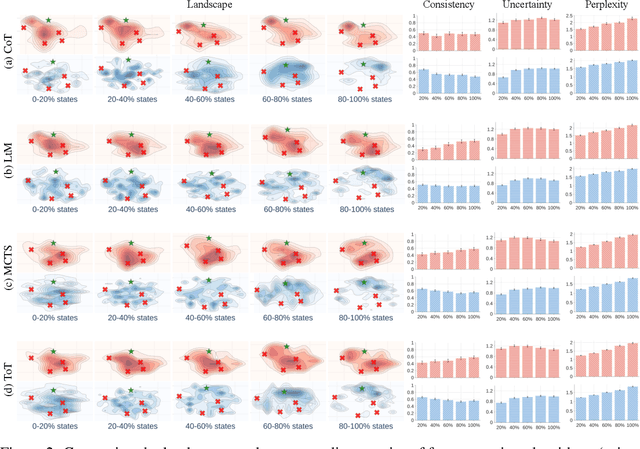
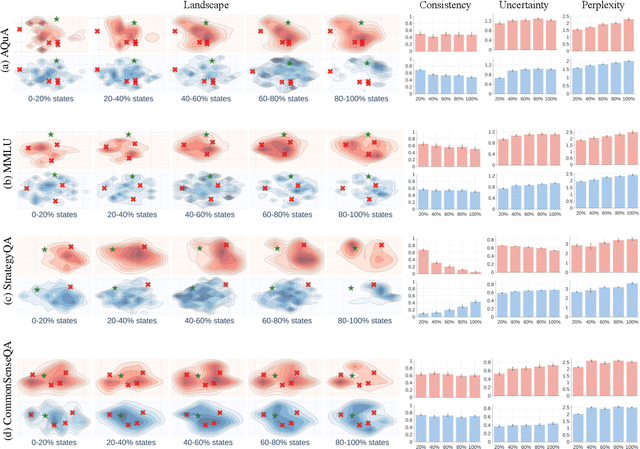
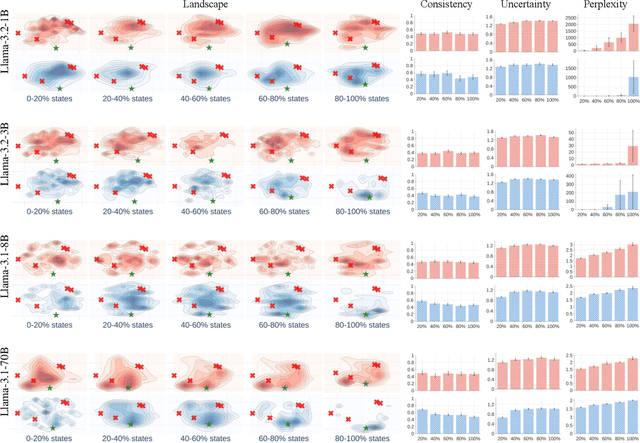
Numerous applications of large language models (LLMs) rely on their ability to perform step-by-step reasoning. However, the reasoning behavior of LLMs remains poorly understood, posing challenges to research, development, and safety. To address this gap, we introduce landscape of thoughts-the first visualization tool for users to inspect the reasoning paths of chain-of-thought and its derivatives on any multi-choice dataset. Specifically, we represent the states in a reasoning path as feature vectors that quantify their distances to all answer choices. These features are then visualized in two-dimensional plots using t-SNE. Qualitative and quantitative analysis with the landscape of thoughts effectively distinguishes between strong and weak models, correct and incorrect answers, as well as different reasoning tasks. It also uncovers undesirable reasoning patterns, such as low consistency and high uncertainty. Additionally, users can adapt our tool to a model that predicts the property they observe. We showcase this advantage by adapting our tool to a lightweight verifier that evaluates the correctness of reasoning paths. The code is publicly available at: https://github.com/tmlr-group/landscape-of-thoughts.
TLUE: A Tibetan Language Understanding Evaluation Benchmark
Mar 15, 2025

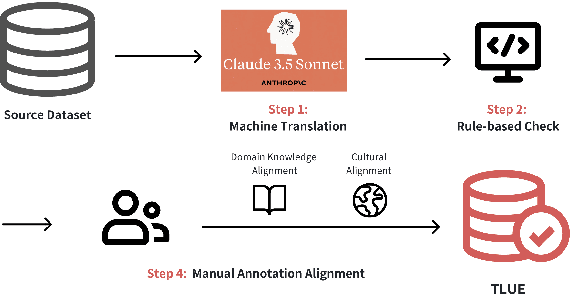

Large language models (LLMs) have made tremendous progress in recent years, but low-resource languages, such as Tibetan, remain significantly underrepresented in their evaluation. Despite Tibetan being spoken by over seven million people, it has largely been neglected in the development and assessment of LLMs. To address this gap, we present TLUE (A Tibetan Language Understanding Evaluation Benchmark), the first large-scale benchmark for assessing LLMs' capabilities in Tibetan. TLUE comprises two major components: (1) a comprehensive multi-task understanding benchmark spanning 5 domains and 67 subdomains, and (2) a safety benchmark covering 7 subdomains. We evaluate a diverse set of state-of-the-art LLMs. Experimental results demonstrate that most LLMs perform below the random baseline, highlighting the considerable challenges LLMs face in processing Tibetan, a low-resource language. TLUE provides an essential foundation for driving future research and progress in Tibetan language understanding and underscores the need for greater inclusivity in LLM development.