 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness and Diversity Seeking Data-Free Knowledge Distillation
Nov 07, 2020


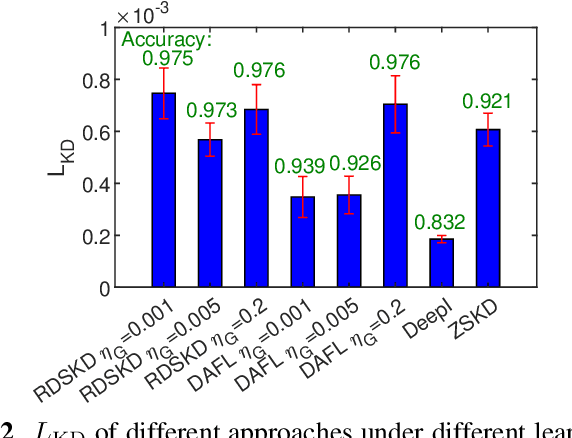
Knowledge distillation (KD) has enabled remarkable progress in model compression and knowledge transfer. However, KD requires a large volume of original data or their representation statistics that are not usually available in practice. Data-free KD has recently been proposed to resolve this problem, wherein teacher and student models are fed by a synthetic sample generator trained from the teacher. Nonetheless, existing data-free KD methods rely on fine-tuning of weights to balance multiple losses, and ignore the diversity of generated samples, resulting in limited accuracy and robustness. To overcome this challenge, we propose robustness and diversity seeking data-free KD (RDSKD) in this paper. The generator loss function is crafted to produce samples with high authenticity, class diversity, and inter-sample diversity. Without real data, the objectives of seeking high sample authenticity and class diversity often conflict with each other, causing frequent loss fluctuations. We mitigate this by exponentially penalizing loss increments. With MNIST, CIFAR-10, and SVHN datasets, our experiments show that RDSKD achieves higher accuracy with more robustness over different hyperparameter settings, compared to other data-free KD methods such as DAFL, MSKD, ZSKD, and DeepInversion.