 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime to Retrain? Detecting Concept Drifts in Machine Learning Systems
Oct 11, 2024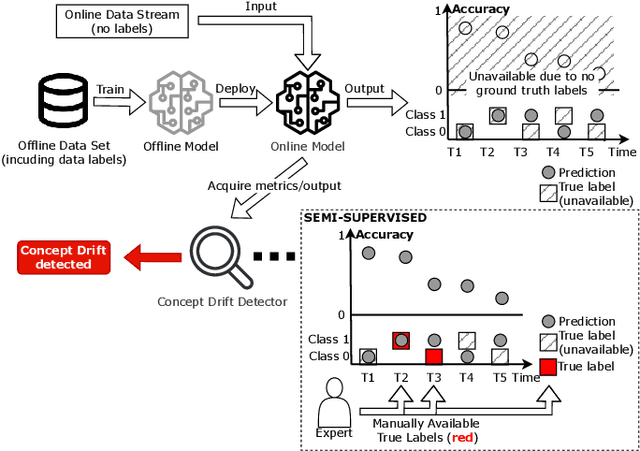
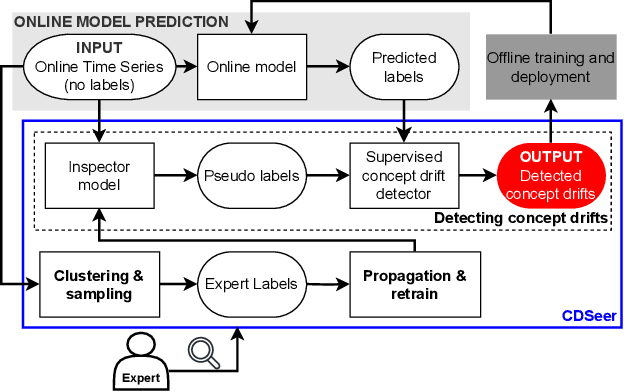
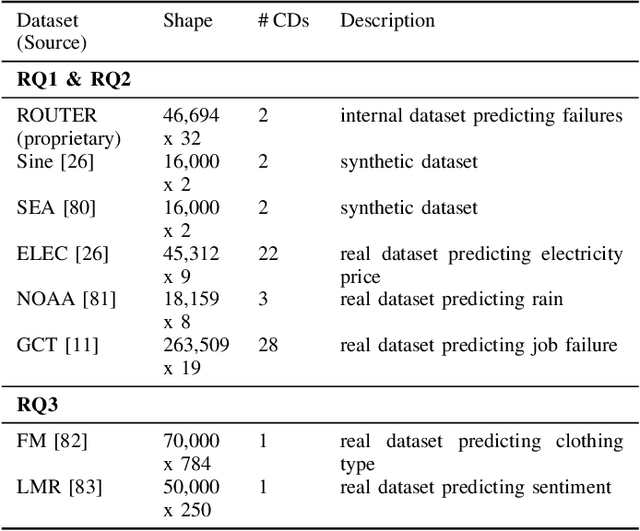
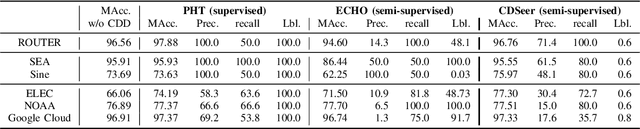
With the boom of machine learning (ML) techniques, software practitioners build ML systems to process the massive volume of streaming data for diverse software engineering tasks such as failure prediction in AIOps. Trained using historical data, such ML models encounter performance degradation caused by concept drift, i.e., data and inter-relationship (concept) changes between training and production. It is essential to use concept rift detection to monitor the deployed ML models and re-train the ML models when needed. In this work, we explore applying state-of-the-art (SOTA) concept drift detection techniques on synthetic and real-world datasets in an industrial setting. Such an industrial setting requires minimal manual effort in labeling and maximal generality in ML model architecture. We find that current SOTA semi-supervised methods not only require significant labeling effort but also only work for certain types of ML models. To overcome such limitations, we propose a novel model-agnostic technique (CDSeer) for detecting concept drift. Our evaluation shows that CDSeer has better precision and recall compared to the state-of-the-art while requiring significantly less manual labeling. We demonstrate the effectiveness of CDSeer at concept drift detection by evaluating it on eight datasets from different domains and use cases. Results from internal deployment of CDSeer on an industrial proprietary dataset show a 57.1% improvement in precision while using 99% fewer labels compared to the SOTA concept drift detection method. The performance is also comparable to the supervised concept drift detection method, which requires 100% of the data to be labeled. The improved performance and ease of adoption of CDSeer are valuable in making ML systems more reliable.