 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Machine Translation Robustness via Data Augmentation: Beyond Back Translation
Paper and Code

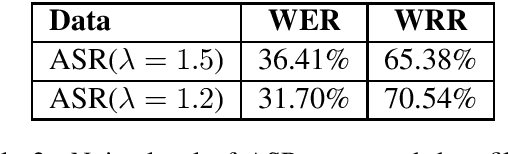


Neural Machine Translation (NMT) models have been proved strong when translating clean texts, but they are very sensitive to noise in the input. Improving NMT models robustness can be seen as a form of "domain" adaption to noise. The recently created Machine Translation on Noisy Text task corpus provides noisy-clean parallel data for a few language pairs, but this data is very limited in size and diversity. The state-of-the-art approaches are heavily dependent on large volumes of back-translated data. This paper has two main contributions: Firstly, we propose new data augmentation methods to extend limited noisy data and further improve NMT robustness to noise while keeping the models small. Secondly, we explore the effect of utilizing noise from external data in the form of speech transcripts and show that it could help robustness.