 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Are What You Write: Preserving Privacy in the Era of Large Language Models
Apr 20, 2022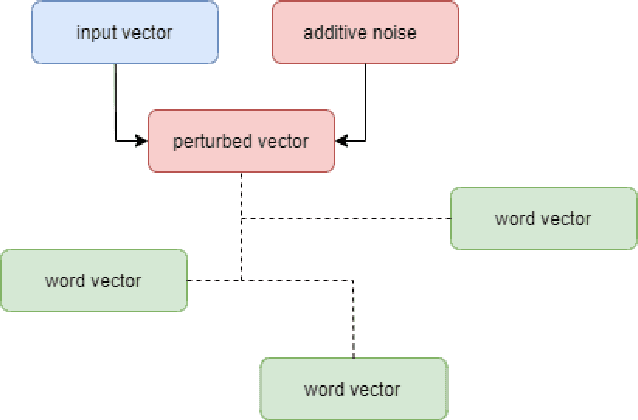

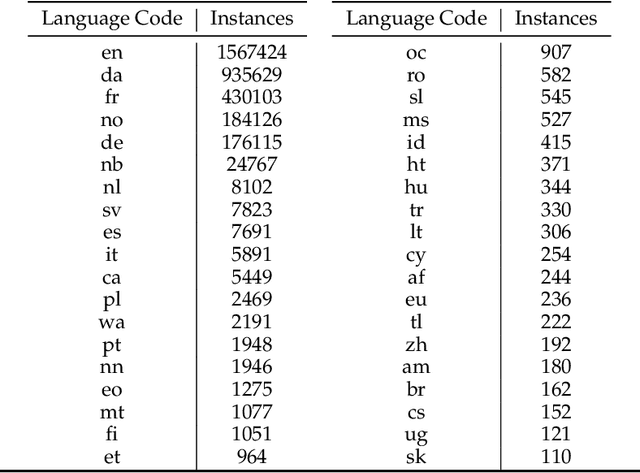
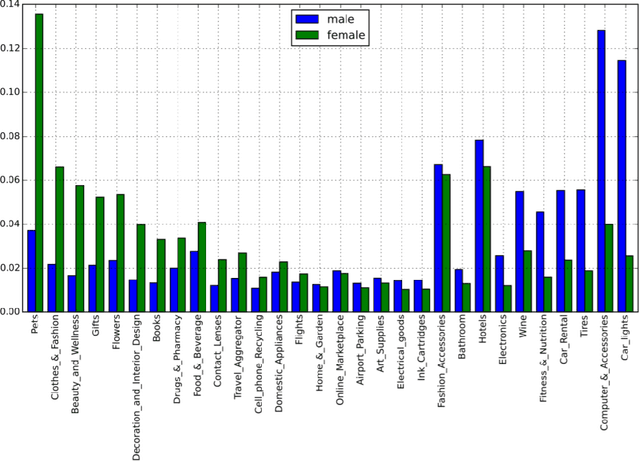
Large scale adoption of large language models has introduced a new era of convenient knowledge transfer for a slew of natural language processing tasks. However, these models also run the risk of undermining user trust by exposing unwanted information about the data subjects, which may be extracted by a malicious party, e.g. through adversarial attacks. We present an empirical investigation into the extent of the personal information encoded into pre-trained representations by a range of popular models, and we show a positive correlation between the complexity of a model, the amount of data used in pre-training, and data leakage. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular privacy-preserving algorithms, on a large, multi-lingual dataset on sentiment analysis annotated with demographic information (location, age and gender). The results show since larger and more complex models are more prone to leaking private information, use of privacy-preserving methods is highly desirable. We also find that highly privacy-preserving technologies like differential privacy (DP) can have serious model utility effects, which can be ameliorated using hybrid or metric-DP techniques.
CAPE: Context-Aware Private Embeddings for Private Language Learning
Aug 27, 2021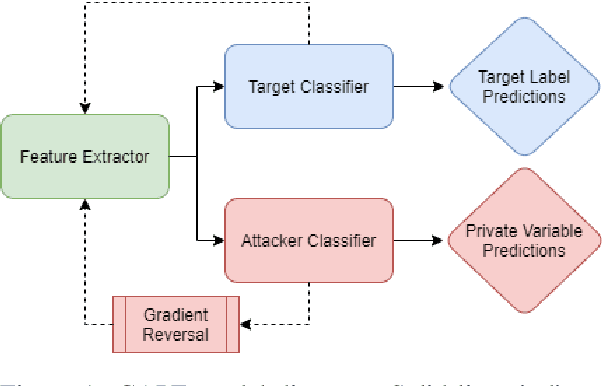
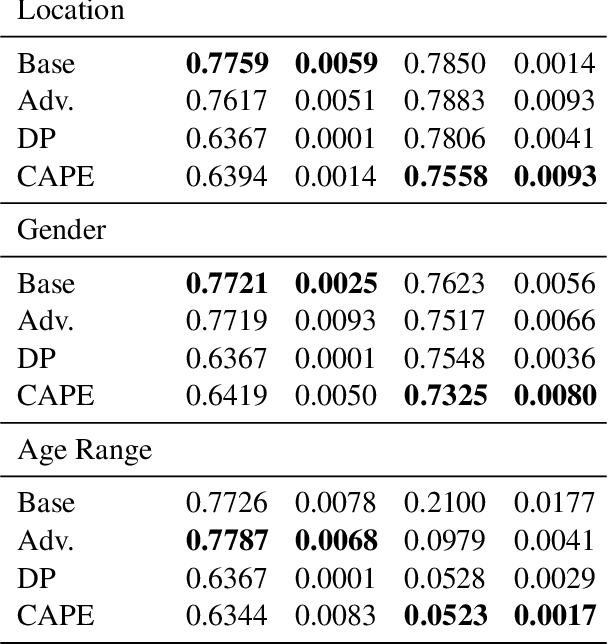
Deep learning-based language models have achieved state-of-the-art results in a number of applications including sentiment analysis, topic labelling, intent classification and others. Obtaining text representations or embeddings using these models presents the possibility of encoding personally identifiable information learned from language and context cues that may present a risk to reputation or privacy. To ameliorate these issues, we propose Context-Aware Private Embeddings (CAPE), a novel approach which preserves privacy during training of embeddings. To maintain the privacy of text representations, CAPE applies calibrated noise through differential privacy, preserving the encoded semantic links while obscuring sensitive information. In addition, CAPE employs an adversarial training regime that obscures identified private variables. Experimental results demonstrate that the proposed approach reduces private information leakage better than either single intervention.