 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPIE: Topology-Preserved Image Editing With Text Instructions
Nov 22, 2024



Preserving topological structures is important in real-world applications, particularly in sensitive domains such as healthcare and medicine, where the correctness of human anatomy is critical. However, most existing image editing models focus on manipulating intensity and texture features, often overlooking object geometry within images. To address this issue, this paper introduces a novel method, Topology-Preserved Image Editing with text instructions (TPIE), that for the first time ensures the topology and geometry remaining intact in edited images through text-guided generative diffusion models. More specifically, our method treats newly generated samples as deformable variations of a given input template, allowing for controllable and structure-preserving edits. Our proposed TPIE framework consists of two key modules: (i) an autoencoder-based registration network that learns latent representations of object transformations, parameterized by velocity fields, from pairwise training images; and (ii) a novel latent conditional geometric diffusion (LCDG) model efficiently capturing the data distribution of learned transformation features conditioned on custom-defined text instructions. We validate TPIE on a diverse set of 2D and 3D images and compare them with state-of-the-art image editing approaches. Experimental results show that our method outperforms other baselines in generating more realistic images with well-preserved topology. Our code will be made publicly available on Github.
Invariant Shape Representation Learning For Image Classification
Nov 19, 2024



Geometric shape features have been widely used as strong predictors for image classification. Nevertheless, most existing classifiers such as deep neural networks (DNNs) directly leverage the statistical correlations between these shape features and target variables. However, these correlations can often be spurious and unstable across different environments (e.g., in different age groups, certain types of brain changes have unstable relations with neurodegenerative disease); hence leading to biased or inaccurate predictions. In this paper, we introduce a novel framework that for the first time develops invariant shape representation learning (ISRL) to further strengthen the robustness of image classifiers. In contrast to existing approaches that mainly derive features in the image space, our model ISRL is designed to jointly capture invariant features in latent shape spaces parameterized by deformable transformations. To achieve this goal, we develop a new learning paradigm based on invariant risk minimization (IRM) to learn invariant representations of image and shape features across multiple training distributions/environments. By embedding the features that are invariant with regard to target variables in different environments, our model consistently offers more accurate predictions. We validate our method by performing classification tasks on both simulated 2D images, real 3D brain and cine cardiovascular magnetic resonance images (MRIs). Our code is publicly available at https://github.com/tonmoy-hossain/ISRL.
MGAug: Multimodal Geometric Augmentation in Latent Spaces of Image Deformations
Dec 20, 2023Geometric transformations have been widely used to augment the size of training images. Existing methods often assume a unimodal distribution of the underlying transformations between images, which limits their power when data with multimodal distributions occur. In this paper, we propose a novel model, Multimodal Geometric Augmentation (MGAug), that for the first time generates augmenting transformations in a multimodal latent space of geometric deformations. To achieve this, we first develop a deep network that embeds the learning of latent geometric spaces of diffeomorphic transformations (a.k.a. diffeomorphisms) in a variational autoencoder (VAE). A mixture of multivariate Gaussians is formulated in the tangent space of diffeomorphisms and serves as a prior to approximate the hidden distribution of image transformations. We then augment the original training dataset by deforming images using randomly sampled transformations from the learned multimodal latent space of VAE. To validate the efficiency of our model, we jointly learn the augmentation strategy with two distinct domain-specific tasks: multi-class classification on 2D synthetic datasets and segmentation on real 3D brain magnetic resonance images (MRIs). We also compare MGAug with state-of-the-art transformation-based image augmentation algorithms. Experimental results show that our proposed approach outperforms all baselines by significantly improved prediction accuracy. Our code is publicly available at https://github.com/tonmoy-hossain/MGAug.
SADIR: Shape-Aware Diffusion Models for 3D Image Reconstruction
Sep 06, 2023



3D image reconstruction from a limited number of 2D images has been a long-standing challenge in computer vision and image analysis. While deep learning-based approaches have achieved impressive performance in this area, existing deep networks often fail to effectively utilize the shape structures of objects presented in images. As a result, the topology of reconstructed objects may not be well preserved, leading to the presence of artifacts such as discontinuities, holes, or mismatched connections between different parts. In this paper, we propose a shape-aware network based on diffusion models for 3D image reconstruction, named SADIR, to address these issues. In contrast to previous methods that primarily rely on spatial correlations of image intensities for 3D reconstruction, our model leverages shape priors learned from the training data to guide the reconstruction process. To achieve this, we develop a joint learning network that simultaneously learns a mean shape under deformation models. Each reconstructed image is then considered as a deformed variant of the mean shape. We validate our model, SADIR, on both brain and cardiac magnetic resonance images (MRIs). Experimental results show that our method outperforms the baselines with lower reconstruction error and better preservation of the shape structure of objects within the images.
Multimodal Deep Learning to Differentiate Tumor Recurrence from Treatment Effect in Human Glioblastoma
Feb 27, 2023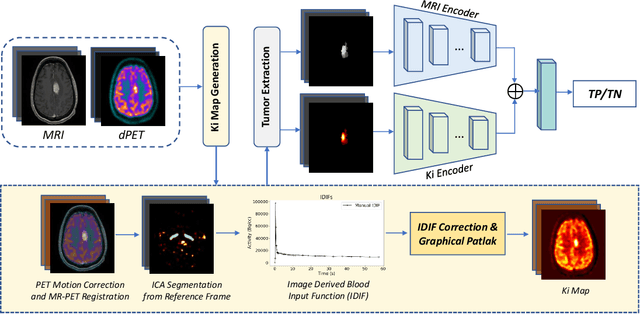
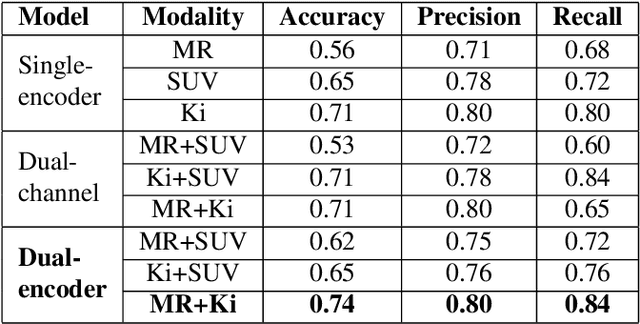

Differentiating tumor progression (TP) from treatment-related necrosis (TN) is critical for clinical management decisions in glioblastoma (GBM). Dynamic FDG PET (dPET), an advance from traditional static FDG PET, may prove advantageous in clinical staging. dPET includes novel methods of a model-corrected blood input function that accounts for partial volume averaging to compute parametric maps that reveal kinetic information. In a preliminary study, a convolution neural network (CNN) was trained to predict classification accuracy between TP and TN for $35$ brain tumors from $26$ subjects in the PET-MR image space. 3D parametric PET Ki (from dPET), traditional static PET standardized uptake values (SUV), and also the brain tumor MR voxels formed the input for the CNN. The average test accuracy across all leave-one-out cross-validation iterations adjusting for class weights was $0.56$ using only the MR, $0.65$ using only the SUV, and $0.71$ using only the Ki voxels. Combining SUV and MR voxels increased the test accuracy to $0.62$. On the other hand, MR and Ki voxels increased the test accuracy to $0.74$. Thus, dPET features alone or with MR features in deep learning models would enhance prediction accuracy in differentiating TP vs TN in GBM.