 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Truly Need So Many Samples? Multi-LLM Repeated Sampling Efficiently Scales Test-Time Compute
Apr 02, 2025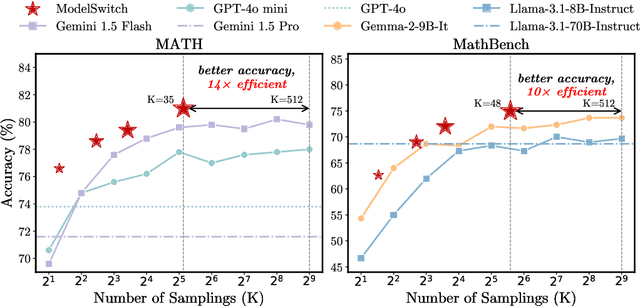

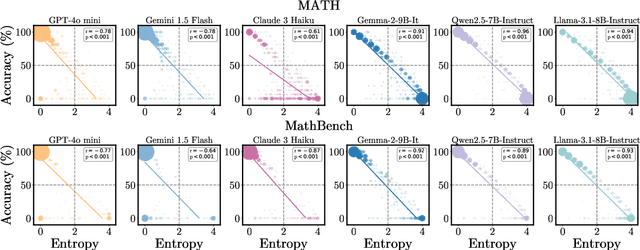
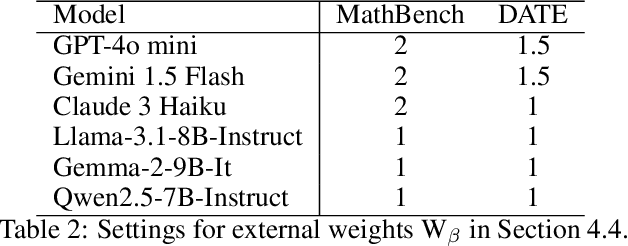
This paper presents a simple, effective, and cost-efficient strategy to improve LLM performance by scaling test-time compute. Our strategy builds upon the repeated-sampling-then-voting framework, with a novel twist: incorporating multiple models, even weaker ones, to leverage their complementary strengths that potentially arise from diverse training data and paradigms. By using consistency as a signal, our strategy dynamically switches between models. Theoretical analysis highlights the efficiency and performance advantages of our strategy. Extensive experiments on six datasets demonstrate that our strategy not only outperforms self-consistency and state-of-the-art multi-agent debate approaches, but also significantly reduces inference costs. Additionally, ModelSwitch requires only a few comparable LLMs to achieve optimal performance and can be extended with verification methods, demonstrating the potential of leveraging multiple LLMs in the generation-verification paradigm.
Understanding When and Why Graph Attention Mechanisms Work via Node Classification
Dec 20, 2024Despite the growing popularity of graph attention mechanisms, their theoretical understanding remains limited. This paper aims to explore the conditions under which these mechanisms are effective in node classification tasks through the lens of Contextual Stochastic Block Models (CSBMs). Our theoretical analysis reveals that incorporating graph attention mechanisms is \emph{not universally beneficial}. Specifically, by appropriately defining \emph{structure noise} and \emph{feature noise} in graphs, we show that graph attention mechanisms can enhance classification performance when structure noise exceeds feature noise. Conversely, when feature noise predominates, simpler graph convolution operations are more effective. Furthermore, we examine the over-smoothing phenomenon and show that, in the high signal-to-noise ratio (SNR) regime, graph convolutional networks suffer from over-smoothing, whereas graph attention mechanisms can effectively resolve this issue. Building on these insights, we propose a novel multi-layer Graph Attention Network (GAT) architecture that significantly outperforms single-layer GATs in achieving \emph{perfect node classification} in CSBMs, relaxing the SNR requirement from $ \omega(\sqrt{\log n}) $ to $ \omega(\sqrt{\log n} / \sqrt[3]{n}) $. To our knowledge, this is the first study to delineate the conditions for perfect node classification using multi-layer GATs. Our theoretical contributions are corroborated by extensive experiments on both synthetic and real-world datasets, highlighting the practical implications of our findings.