 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Retrieval for Question Answering with Cross-Attention Supervised Data Augmentation
Sep 29, 2020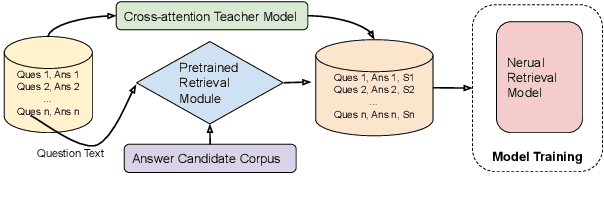
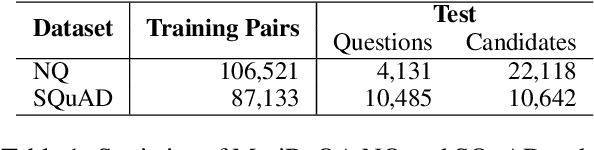
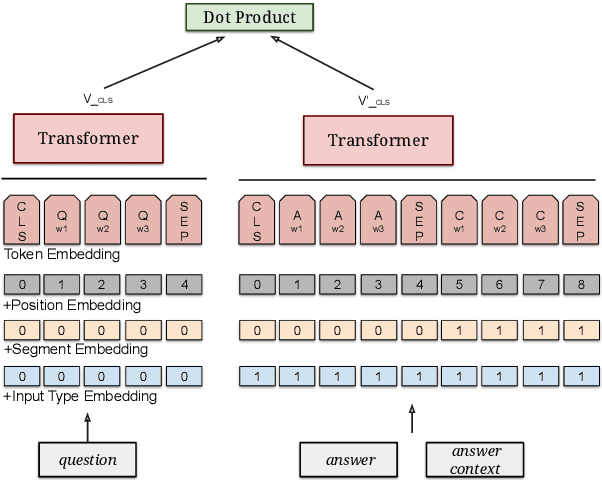
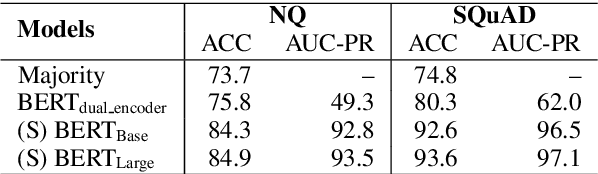
Neural models that independently project questions and answers into a shared embedding space allow for efficient continuous space retrieval from large corpora. Independently computing embeddings for questions and answers results in late fusion of information related to matching questions to their answers. While critical for efficient retrieval, late fusion underperforms models that make use of early fusion (e.g., a BERT based classifier with cross-attention between question-answer pairs). We present a supervised data mining method using an accurate early fusion model to improve the training of an efficient late fusion retrieval model. We first train an accurate classification model with cross-attention between questions and answers. The accurate cross-attention model is then used to annotate additional passages in order to generate weighted training examples for a neural retrieval model. The resulting retrieval model with additional data significantly outperforms retrieval models directly trained with gold annotations on Precision at $N$ (P@N) and Mean Reciprocal Rank (MRR).