 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniHang: Learning to Hang Arbitrary Objects using Contact Point Correspondences and Neural Collision Estimation
Mar 26, 2021
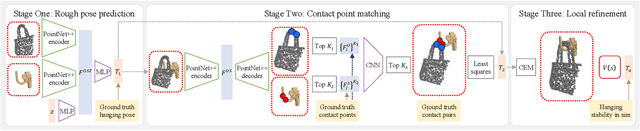
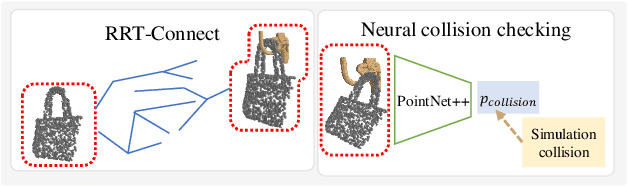
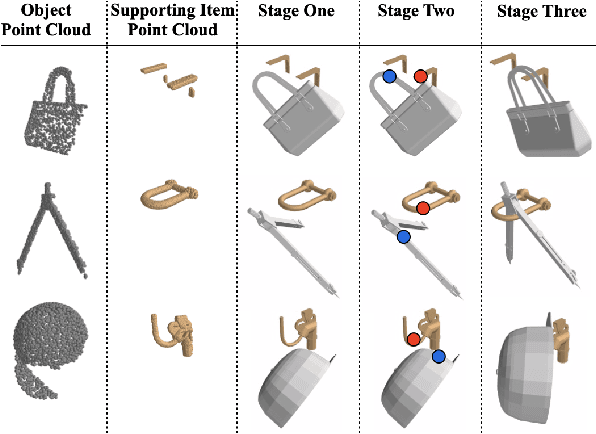
In this paper, we explore whether a robot can learn to hang arbitrary objects onto a diverse set of supporting items such as racks or hooks. Endowing robots with such an ability has applications in many domains such as domestic services, logistics, or manufacturing. Yet, it is a challenging manipulation task due to the large diversity of geometry and topology of everyday objects. In this paper, we propose a system that takes partial point clouds of an object and a supporting item as input and learns to decide where and how to hang the object stably. Our system learns to estimate the contact point correspondences between the object and supporting item to get an estimated stable pose. We then run a deep reinforcement learning algorithm to refine the predicted stable pose. Then, the robot needs to find a collision-free path to move the object from its initial pose to stable hanging pose. To this end, we train a neural network based collision estimator that takes as input partial point clouds of the object and supporting item. We generate a new and challenging, large-scale, synthetic dataset annotated with stable poses of objects hung on various supporting items and their contact point correspondences. In this dataset, we show that our system is able to achieve a 68.3% success rate of predicting stable object poses and has a 52.1% F1 score in terms of finding feasible paths. Supplemental material and videos are available on our project webpage.
GRAC: Self-Guided and Self-Regularized Actor-Critic
Sep 18, 2020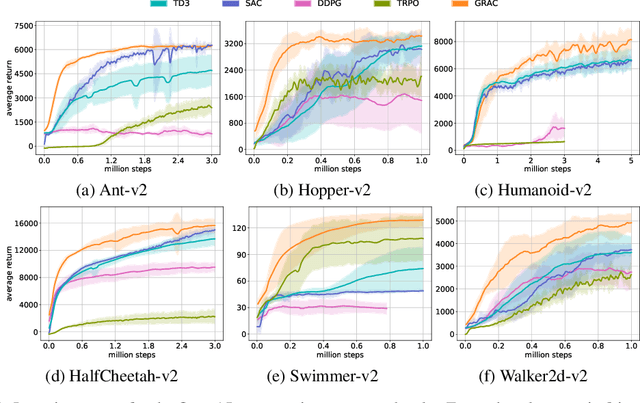
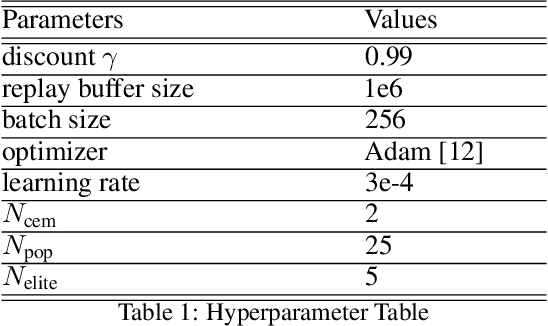
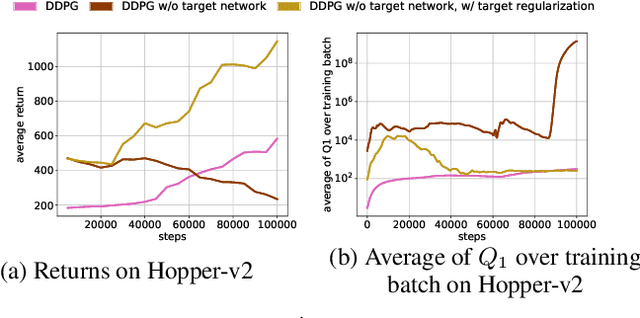
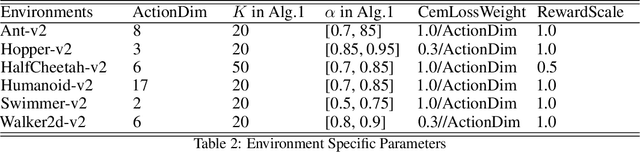
Deep reinforcement learning (DRL) algorithms have successfully been demonstrated on a range of challenging decision making and control tasks. One dominant component of recent deep reinforcement learning algorithms is the target network which mitigates the divergence when learning the Q function. However, target networks can slow down the learning process due to delayed function updates. Another dominant component especially in continuous domains is the policy gradient method which models and optimizes the policy directly. However, when Q functions are approximated with neural networks, their landscapes can be complex and therefore mislead the local gradient. In this work, we propose a self-regularized and self-guided actor-critic method. We introduce a self-regularization term within the TD-error minimization and remove the need for the target network. In addition, we propose a self-guided policy improvement method by combining policy-gradient with zero-order optimization such as the Cross Entropy Method. It helps to search for actions associated with higher Q-values in a broad neighborhood and is robust to local noise in the Q function approximation. These actions help to guide the updates of our actor network. We evaluate our method on the suite of OpenAI gym tasks, achieving or outperforming state of the art in every environment tested.