 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOAST: Constraints and Streams for Task and Motion Planning
May 14, 2024
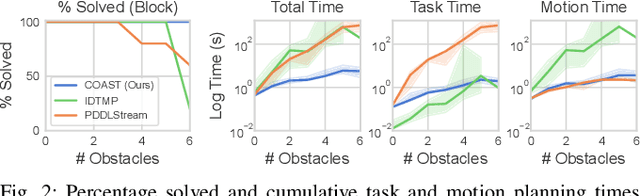
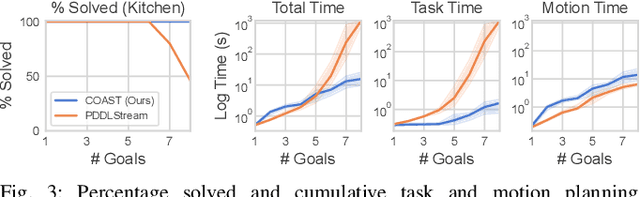
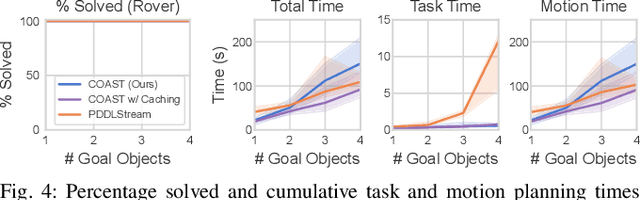
Task and Motion Planning (TAMP) algorithms solve long-horizon robotics tasks by integrating task planning with motion planning; the task planner proposes a sequence of actions towards a goal state and the motion planner verifies whether this action sequence is geometrically feasible for the robot. However, state-of-the-art TAMP algorithms do not scale well with the difficulty of the task and require an impractical amount of time to solve relatively small problems. We propose Constraints and Streams for Task and Motion Planning (COAST), a probabilistically-complete, sampling-based TAMP algorithm that combines stream-based motion planning with an efficient, constrained task planning strategy. We validate COAST on three challenging TAMP domains and demonstrate that our method outperforms baselines in terms of cumulative task planning time by an order of magnitude. You can find more supplementary materials on our project \href{https://branvu.github.io/coast.github.io}{website}.
Text2Motion: From Natural Language Instructions to Feasible Plans
Mar 21, 2023We propose Text2Motion, a language-based planning framework enabling robots to solve sequential manipulation tasks that require long-horizon reasoning. Given a natural language instruction, our framework constructs both a task- and policy-level plan that is verified to reach inferred symbolic goals. Text2Motion uses skill feasibility heuristics encoded in learned Q-functions to guide task planning with Large Language Models. Whereas previous language-based planners only consider the feasibility of individual skills, Text2Motion actively resolves geometric dependencies spanning skill sequences by performing policy sequence optimization during its search. We evaluate our method on a suite of problems that require long-horizon reasoning, interpretation of abstract goals, and handling of partial affordance perception. Our experiments show that Text2Motion can solve these challenging problems with a success rate of 64%, while prior state-of-the-art language-based planning methods only achieve 13%. Text2Motion thus provides promising generalization characteristics to semantically diverse sequential manipulation tasks with geometric dependencies between skills.
Active Task Randomization: Learning Visuomotor Skills for Sequential Manipulation by Proposing Feasible and Novel Tasks
Nov 11, 2022



Solving real-world sequential manipulation tasks requires robots to have a repertoire of skills applicable to a wide range of circumstances. To acquire such skills using data-driven approaches, we need massive and diverse training data which is often labor-intensive and non-trivial to collect and curate. In this work, we introduce Active Task Randomization (ATR), an approach that learns visuomotor skills for sequential manipulation by automatically creating feasible and novel tasks in simulation. During training, our approach procedurally generates tasks using a graph-based task parameterization. To adaptively estimate the feasibility and novelty of sampled tasks, we develop a relational neural network that maps each task parameter into a compact embedding. We demonstrate that our approach can automatically create suitable tasks for efficiently training the skill policies to handle diverse scenarios with a variety of objects. We evaluate our method on simulated and real-world sequential manipulation tasks by composing the learned skills using a task planner. Compared to baseline methods, the skills learned using our approach consistently achieve better success rates.
Category-Independent Articulated Object Tracking with Factor Graphs
May 07, 2022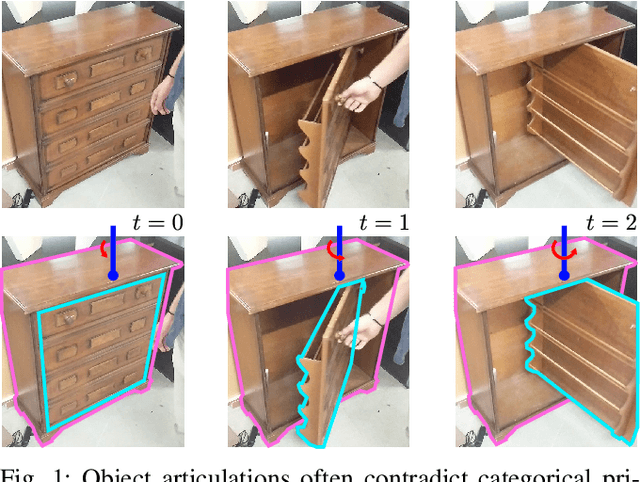
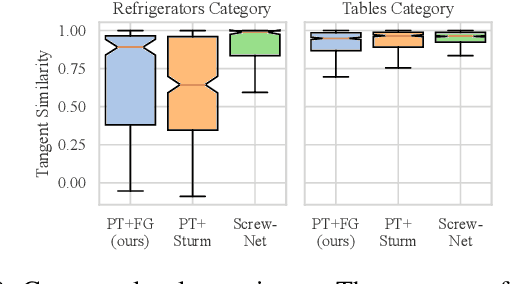
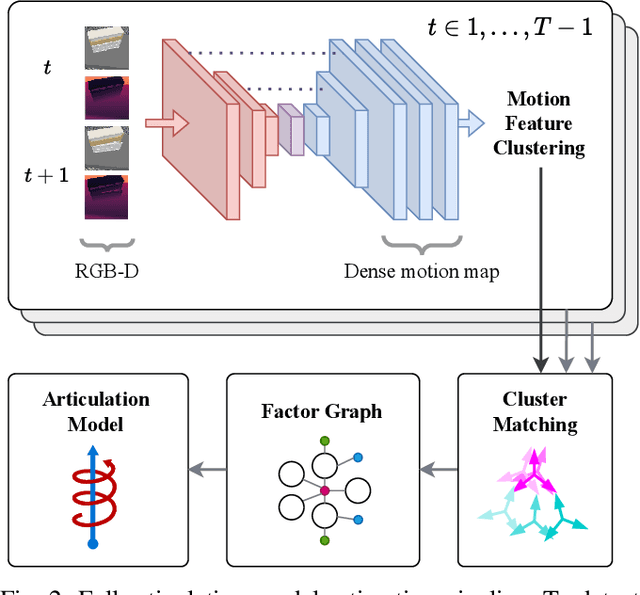
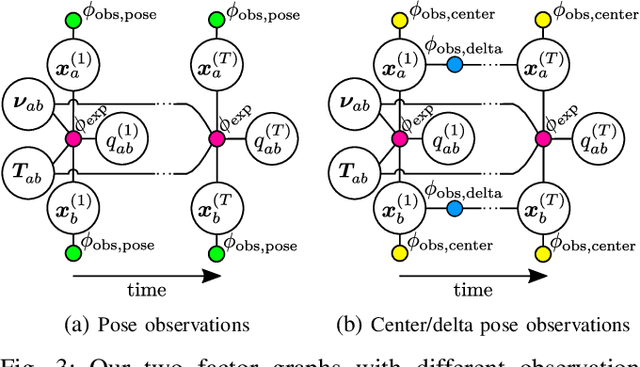
Robots deployed in human-centric environments may need to manipulate a diverse range of articulated objects, such as doors, dishwashers, and cabinets. Articulated objects often come with unexpected articulation mechanisms that are inconsistent with categorical priors: for example, a drawer might rotate about a hinge joint instead of sliding open. We propose a category-independent framework for predicting the articulation models of unknown objects from sequences of RGB-D images. The prediction is performed by a two-step process: first, a visual perception module tracks object part poses from raw images, and second, a factor graph takes these poses and infers the articulation model including the current configuration between the parts as a 6D twist. We also propose a manipulation-oriented metric to evaluate predicted joint twists in terms of how well a compliant robot controller would be able to manipulate the articulated object given the predicted twist. We demonstrate that our visual perception and factor graph modules outperform baselines on simulated data and show the applicability of our factor graph on real world data.
Symbolic State Estimation with Predicates for Contact-Rich Manipulation Tasks
Mar 04, 2022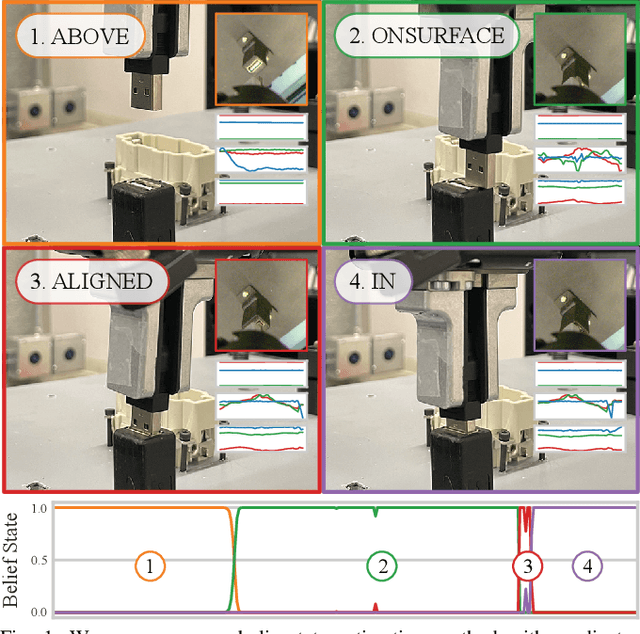

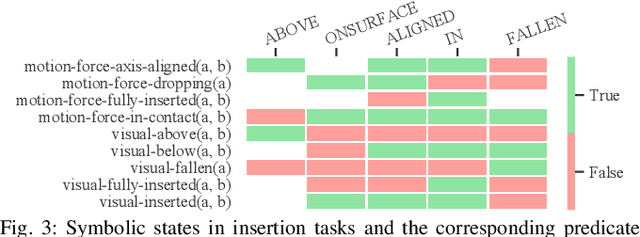

Manipulation tasks often require a robot to adjust its sensorimotor skills based on the state it finds itself in. Taking peg-in-hole as an example: once the peg is aligned with the hole, the robot should push the peg downwards. While high level execution frameworks such as state machines and behavior trees are commonly used to formalize such decision-making problems, these frameworks require a mechanism to detect the high-level symbolic state. Handcrafting heuristics to identify symbolic states can be brittle, and using data-driven methods can produce noisy predictions, particularly when working with limited datasets, as is common in real-world robotic scenarios. This paper proposes a Bayesian state estimation method to predict symbolic states with predicate classifiers. This method requires little training data and allows fusing noisy observations from multiple sensor modalities. We evaluate our framework on a set of real-world peg-in-hole and connector-socket insertion tasks, demonstrating its ability to classify symbolic states and to generalize to unseen tasks, outperforming baseline methods. We also demonstrate the ability of our method to improve the robustness of manipulation policies on a real robot.
Grounding Predicates through Actions
Sep 29, 2021



Symbols representing abstract states such as "dish in dishwasher" or "cup on table" allow robots to reason over long horizons by hiding details unnecessary for high level planning. Current methods for learning to identify symbolic states in visual data require large amounts of labeled training data, but manually annotating such datasets is prohibitively expensive due to the combinatorial number of predicates in images. We propose a novel method for automatically labeling symbolic states in large-scale video activity datasets by exploiting known pre- and post-conditions of actions. This automatic labeling scheme only requires weak supervision in the form of an action label that describes which action is demonstrated in each video. We apply our framework to an existing large-scale human activity dataset. We train predicate classifiers to identify symbolic relationships between objects when prompted with object bounding boxes and achieve 0.93 test accuracy. We further demonstrate the ability of these predicate classifiers trained on human data to be applied to robot environments in a real-world task planning domain.
OmniHang: Learning to Hang Arbitrary Objects using Contact Point Correspondences and Neural Collision Estimation
Mar 26, 2021
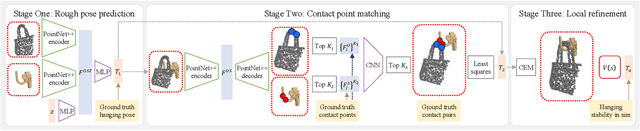
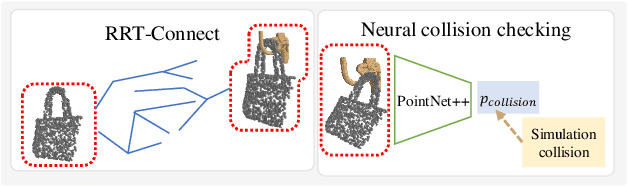
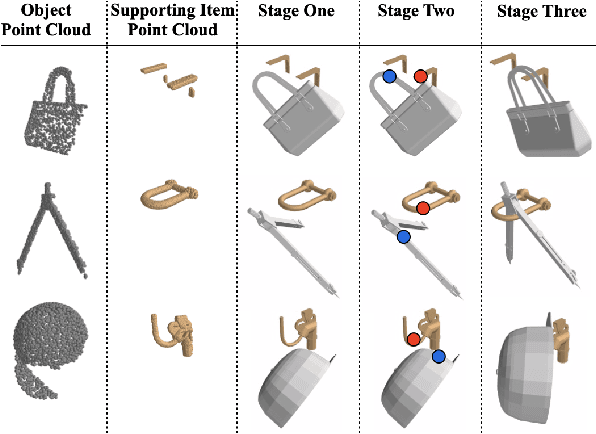
In this paper, we explore whether a robot can learn to hang arbitrary objects onto a diverse set of supporting items such as racks or hooks. Endowing robots with such an ability has applications in many domains such as domestic services, logistics, or manufacturing. Yet, it is a challenging manipulation task due to the large diversity of geometry and topology of everyday objects. In this paper, we propose a system that takes partial point clouds of an object and a supporting item as input and learns to decide where and how to hang the object stably. Our system learns to estimate the contact point correspondences between the object and supporting item to get an estimated stable pose. We then run a deep reinforcement learning algorithm to refine the predicted stable pose. Then, the robot needs to find a collision-free path to move the object from its initial pose to stable hanging pose. To this end, we train a neural network based collision estimator that takes as input partial point clouds of the object and supporting item. We generate a new and challenging, large-scale, synthetic dataset annotated with stable poses of objects hung on various supporting items and their contact point correspondences. In this dataset, we show that our system is able to achieve a 68.3% success rate of predicting stable object poses and has a 52.1% F1 score in terms of finding feasible paths. Supplemental material and videos are available on our project webpage.
Object-Centric Task and Motion Planning in Dynamic Environments
Nov 12, 2019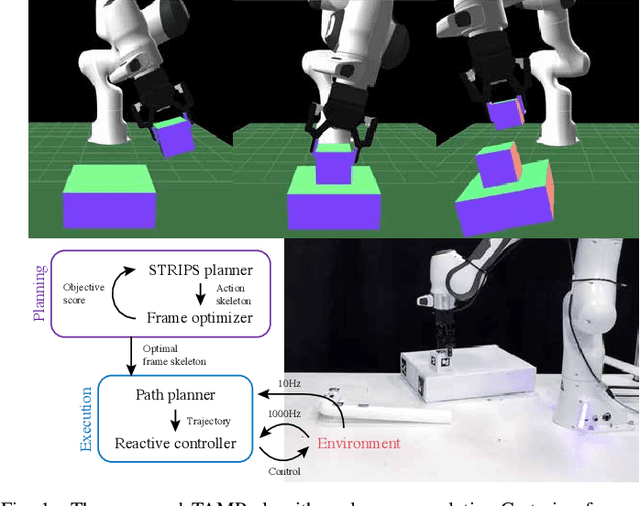
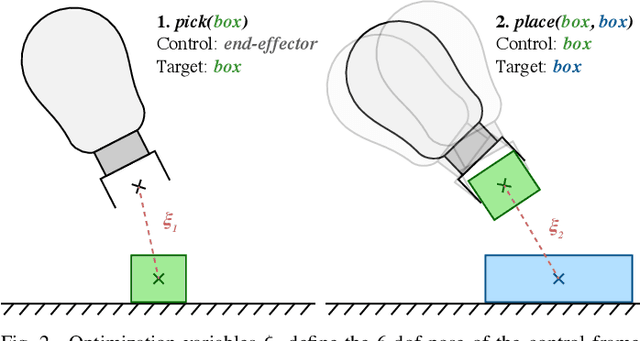

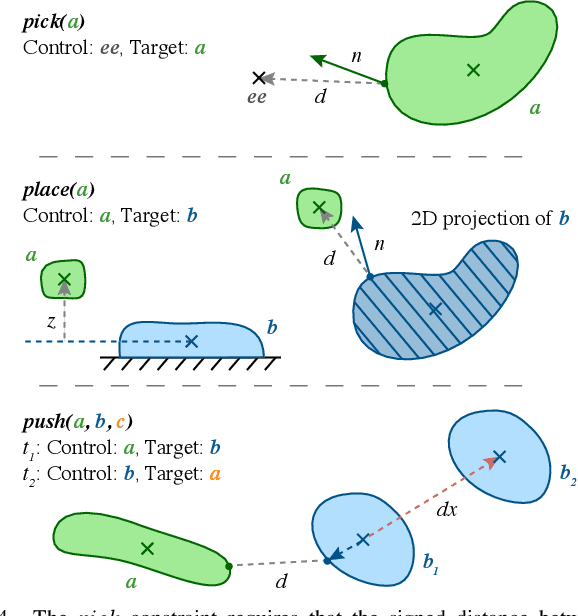
We address the problem of applying Task and Motion Planning (TAMP) in real world environments. TAMP combines symbolic and geometric reasoning to produce sequential manipulation plans, typically specified as joint-space trajectories, which are valid only as long as the environment is static and perception and control are highly accurate. In case of any changes in the environment, slow re-planning is required. We propose a TAMP algorithm that optimizes over Cartesian frames defined relative to target objects. The resulting plan then remains valid even if the objects are moving and can be executed by reactive controllers that adapt to these changes in real time. We apply our TAMP framework to a torque-controlled robot in a pick and place setting and demonstrate its ability to adapt to changing environments, inaccurate perception, and imprecise control, both in simulation and the real world.
Learning to Scaffold the Development of Robotic Manipulation Skills
Nov 03, 2019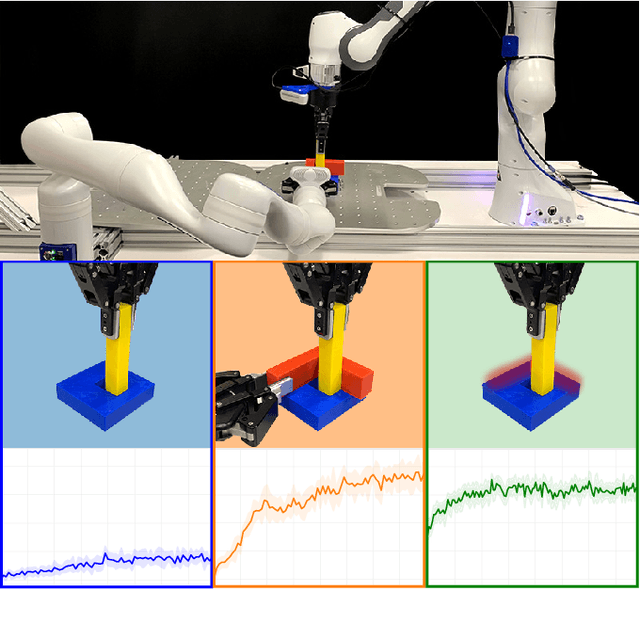



Learning contact-rich, robotic manipulation skills is a challenging problem due to the high-dimensionality of the state and action space as well as uncertainty from noisy sensors and inaccurate motor control. To combat these factors and achieve more robust manipulation, humans actively exploit contact constraints in the environment. By adopting a similar strategy, robots can also achieve more robust manipulation. In this paper, we enable a robot to autonomously modify its environment and thereby discover how to ease manipulation skill learning. Specifically, we provide the robot with fixtures that it can freely place within the environment. These fixtures provide hard constraints that limit the outcome of robot actions. Thereby, they funnel uncertainty from perception and motor control and scaffold manipulation skill learning. We propose a learning system that consists of two learning loops. In the outer loop, the robot positions the fixture in the workspace. In the inner loop, the robot learns a manipulation skill and after a fixed number of episodes, returns the reward to the outer loop. Thereby, the robot is incentivised to place the fixture such that the inner loop quickly achieves a high reward. We demonstrate our framework both in simulation and in the real world on three tasks: peg insertion, wrench manipulation and shallow-depth insertion. We show that manipulation skill learning is dramatically sped up through this way of scaffolding.
Driverseat: Crowdstrapping Learning Tasks for Autonomous Driving
Dec 07, 2015
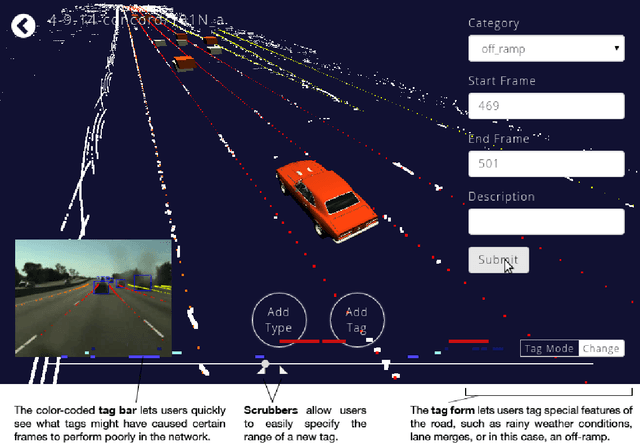
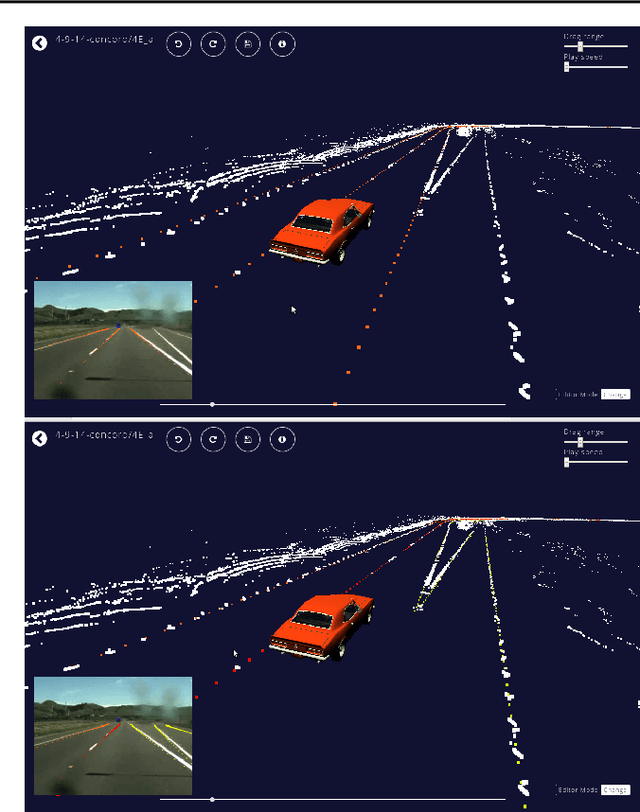
While emerging deep-learning systems have outclassed knowledge-based approaches in many tasks, their application to detection tasks for autonomous technologies remains an open field for scientific exploration. Broadly, there are two major developmental bottlenecks: the unavailability of comprehensively labeled datasets and of expressive evaluation strategies. Approaches for labeling datasets have relied on intensive hand-engineering, and strategies for evaluating learning systems have been unable to identify failure-case scenarios. Human intelligence offers an untapped approach for breaking through these bottlenecks. This paper introduces Driverseat, a technology for embedding crowds around learning systems for autonomous driving. Driverseat utilizes crowd contributions for (a) collecting complex 3D labels and (b) tagging diverse scenarios for ready evaluation of learning systems. We demonstrate how Driverseat can crowdstrap a convolutional neural network on the lane-detection task. More generally, crowdstrapping introduces a valuable paradigm for any technology that can benefit from leveraging the powerful combination of human and computer intelligence.