 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeteorNet: Deep Learning on Dynamic 3D Point Cloud Sequences
Paper and Code
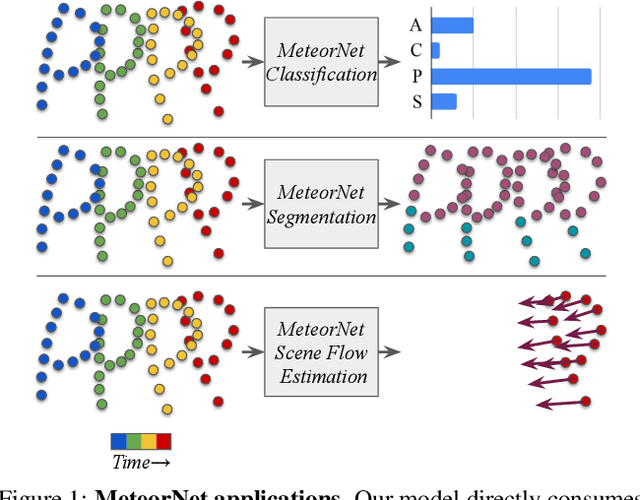
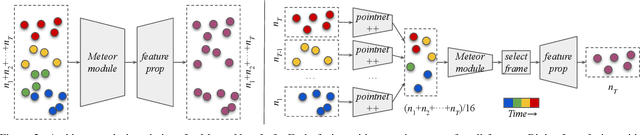
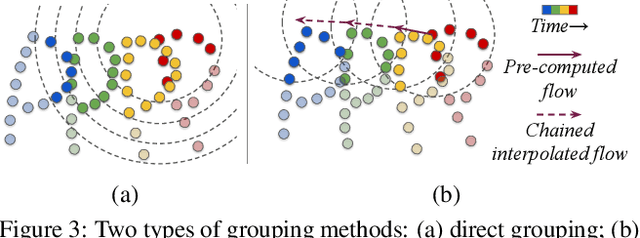
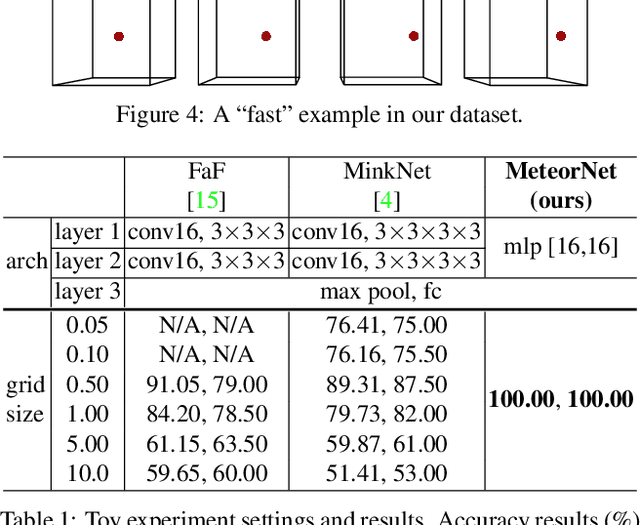
Understanding dynamic 3D environment is crucial for robotic agents and many other applications. We propose a novel neural network architecture called $MeteorNet$ for learning representations for dynamic 3D point cloud sequences. Different from previous work that adopts a grid-based representation and applies 3D or 4D convolutions, our network directly processes point clouds. We propose two ways to construct spatiotemporal neighborhoods for each point in the point cloud sequence. Information from these neighborhoods is aggregated to learn features per point. We benchmark our network on a variety of 3D recognition tasks including action recognition, semantic segmentation and scene flow estimation. MeteorNet shows stronger performance than previous grid-based methods while achieving state-of-the-art performance on Synthia. MeteorNet also outperforms previous baseline methods that are able to process at most two consecutive point clouds. To the best of our knowledge, this is the first work on deep learning for dynamic raw point cloud sequences.