 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Integral Guided Policy Search
Oct 11, 2018
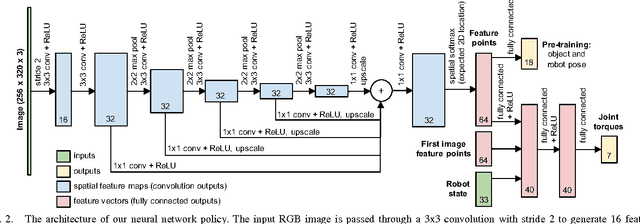

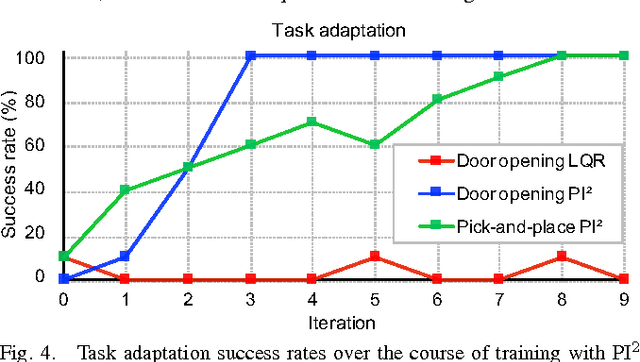
We present a policy search method for learning complex feedback control policies that map from high-dimensional sensory inputs to motor torques, for manipulation tasks with discontinuous contact dynamics. We build on a prior technique called guided policy search (GPS), which iteratively optimizes a set of local policies for specific instances of a task, and uses these to train a complex, high-dimensional global policy that generalizes across task instances. We extend GPS in the following ways: (1) we propose the use of a model-free local optimizer based on path integral stochastic optimal control (PI2), which enables us to learn local policies for tasks with highly discontinuous contact dynamics; and (2) we enable GPS to train on a new set of task instances in every iteration by using on-policy sampling: this increases the diversity of the instances that the policy is trained on, and is crucial for achieving good generalization. We show that these contributions enable us to learn deep neural network policies that can directly perform torque control from visual input. We validate the method on a challenging door opening task and a pick-and-place task, and we demonstrate that our approach substantially outperforms the prior LQR-based local policy optimizer on these tasks. Furthermore, we show that on-policy sampling significantly increases the generalization ability of these policies.
Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search
Oct 03, 2016
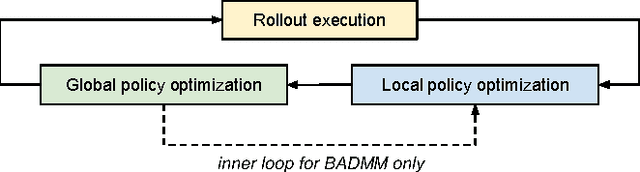
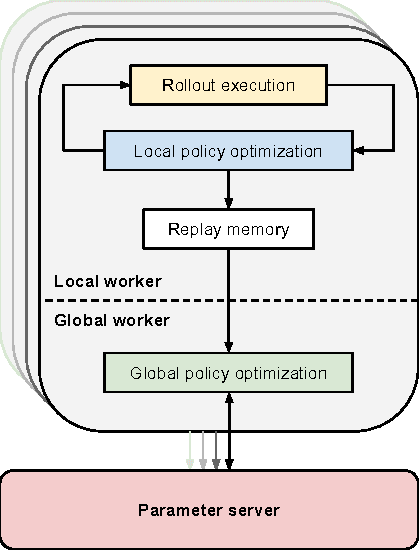
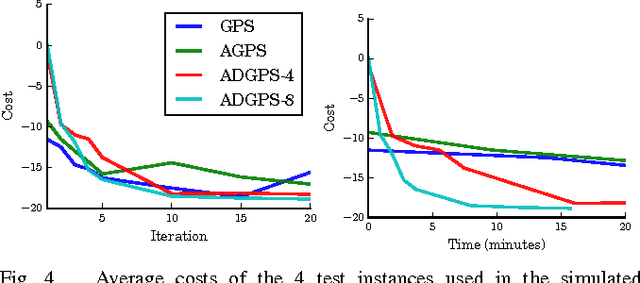
In principle, reinforcement learning and policy search methods can enable robots to learn highly complex and general skills that may allow them to function amid the complexity and diversity of the real world. However, training a policy that generalizes well across a wide range of real-world conditions requires far greater quantity and diversity of experience than is practical to collect with a single robot. Fortunately, it is possible for multiple robots to share their experience with one another, and thereby, learn a policy collectively. In this work, we explore distributed and asynchronous policy learning as a means to achieve generalization and improved training times on challenging, real-world manipulation tasks. We propose a distributed and asynchronous version of Guided Policy Search and use it to demonstrate collective policy learning on a vision-based door opening task using four robots. We show that it achieves better generalization, utilization, and training times than the single robot alternative.