 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Multi-Robot Flocking with Gesture Responsiveness and Musical Accompaniment
Mar 30, 2024For decades, robotics researchers have pursued various tasks for multi-robot systems, from cooperative manipulation to search and rescue. These tasks are multi-robot extensions of classical robotic tasks and often optimized on dimensions such as speed or efficiency. As robots transition from commercial and research settings into everyday environments, social task aims such as engagement or entertainment become increasingly relevant. This work presents a compelling multi-robot task, in which the main aim is to enthrall and interest. In this task, the goal is for a human to be drawn to move alongside and participate in a dynamic, expressive robot flock. Towards this aim, the research team created algorithms for robot movements and engaging interaction modes such as gestures and sound. The contributions are as follows: (1) a novel group navigation algorithm involving human and robot agents, (2) a gesture responsive algorithm for real-time, human-robot flocking interaction, (3) a weight mode characterization system for modifying flocking behavior, and (4) a method of encoding a choreographer's preferences inside a dynamic, adaptive, learned system. An experiment was performed to understand individual human behavior while interacting with the flock under three conditions: weight modes selected by a human choreographer, a learned model, or subset list. Results from the experiment showed that the perception of the experience was not influenced by the weight mode selection. This work elucidates how differing task aims such as engagement manifest in multi-robot system design and execution, and broadens the domain of multi-robot tasks.
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022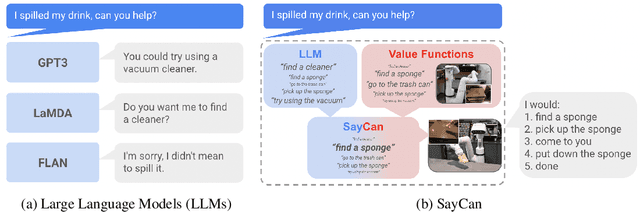
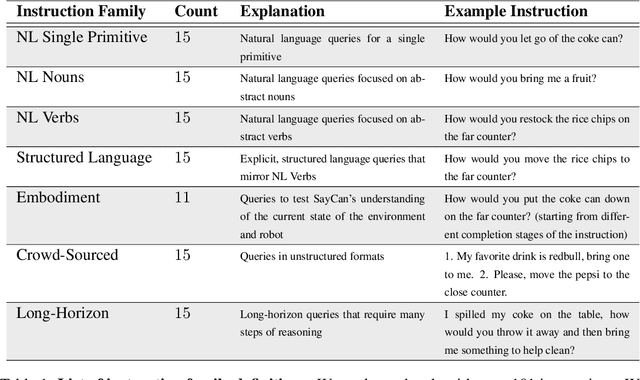
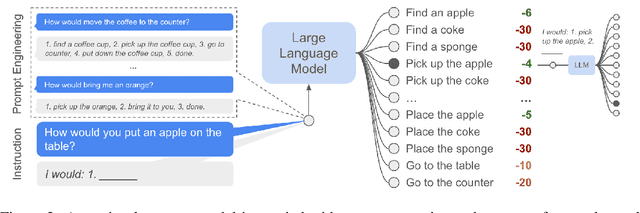
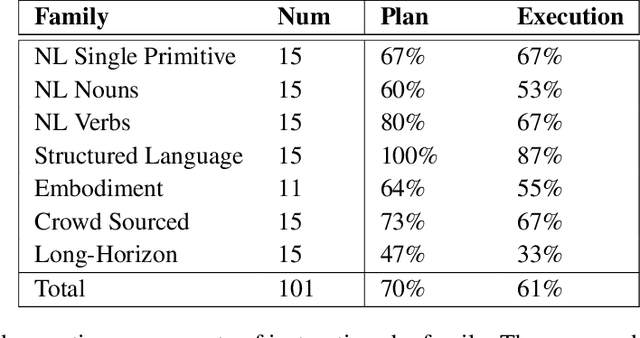
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/