 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Rewards via LLM-Generated Progress Functions
Oct 11, 2024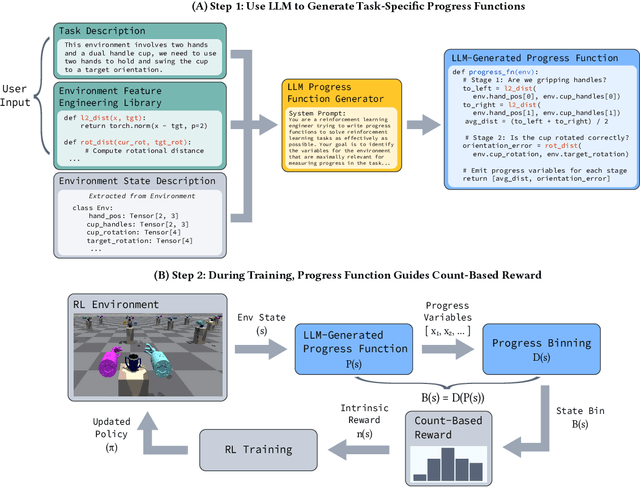
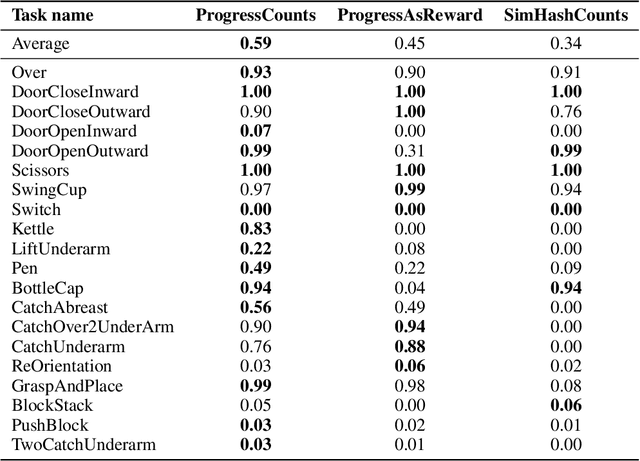
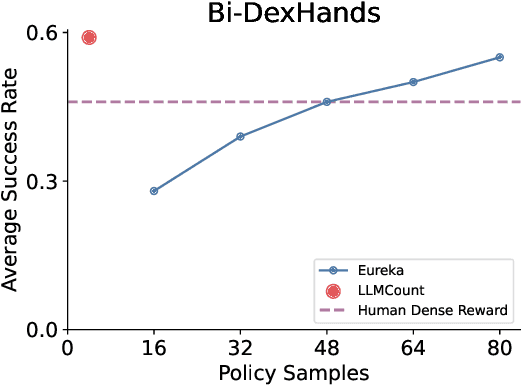

Large Language Models (LLMs) have the potential to automate reward engineering by leveraging their broad domain knowledge across various tasks. However, they often need many iterations of trial-and-error to generate effective reward functions. This process is costly because evaluating every sampled reward function requires completing the full policy optimization process for each function. In this paper, we introduce an LLM-driven reward generation framework that is able to produce state-of-the-art policies on the challenging Bi-DexHands benchmark \textbf{with 20$\times$ fewer reward function samples} than the prior state-of-the-art work. Our key insight is that we reduce the problem of generating task-specific rewards to the problem of coarsely estimating \emph{task progress}. Our two-step solution leverages the task domain knowledge and the code synthesis abilities of LLMs to author \emph{progress functions} that estimate task progress from a given state. Then, we use this notion of progress to discretize states, and generate count-based intrinsic rewards using the low-dimensional state space. We show that the combination of LLM-generated progress functions and count-based intrinsic rewards is essential for our performance gains, while alternatives such as generic hash-based counts or using progress directly as a reward function fall short.