 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntersectionZoo: Eco-driving for Benchmarking Multi-Agent Contextual Reinforcement Learning
Oct 19, 2024Despite the popularity of multi-agent reinforcement learning (RL) in simulated and two-player applications, its success in messy real-world applications has been limited. A key challenge lies in its generalizability across problem variations, a common necessity for many real-world problems. Contextual reinforcement learning (CRL) formalizes learning policies that generalize across problem variations. However, the lack of standardized benchmarks for multi-agent CRL has hindered progress in the field. Such benchmarks are desired to be based on real-world applications to naturally capture the many open challenges of real-world problems that affect generalization. To bridge this gap, we propose IntersectionZoo, a comprehensive benchmark suite for multi-agent CRL through the real-world application of cooperative eco-driving in urban road networks. The task of cooperative eco-driving is to control a fleet of vehicles to reduce fleet-level vehicular emissions. By grounding IntersectionZoo in a real-world application, we naturally capture real-world problem characteristics, such as partial observability and multiple competing objectives. IntersectionZoo is built on data-informed simulations of 16,334 signalized intersections derived from 10 major US cities, modeled in an open-source industry-grade microscopic traffic simulator. By modeling factors affecting vehicular exhaust emissions (e.g., temperature, road conditions, travel demand), IntersectionZoo provides one million data-driven traffic scenarios. Using these traffic scenarios, we benchmark popular multi-agent RL and human-like driving algorithms and demonstrate that the popular multi-agent RL algorithms struggle to generalize in CRL settings.
A Data-Informed Analysis of Scalable Supervision for Safety in Autonomous Vehicle Fleets
Sep 14, 2024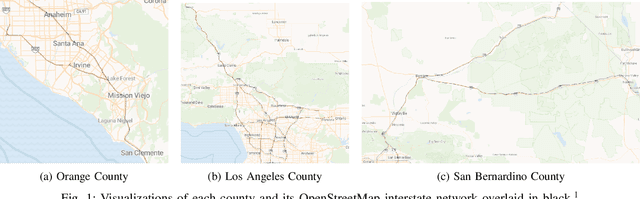
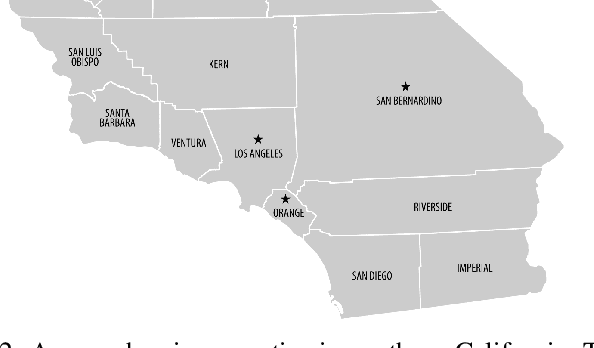
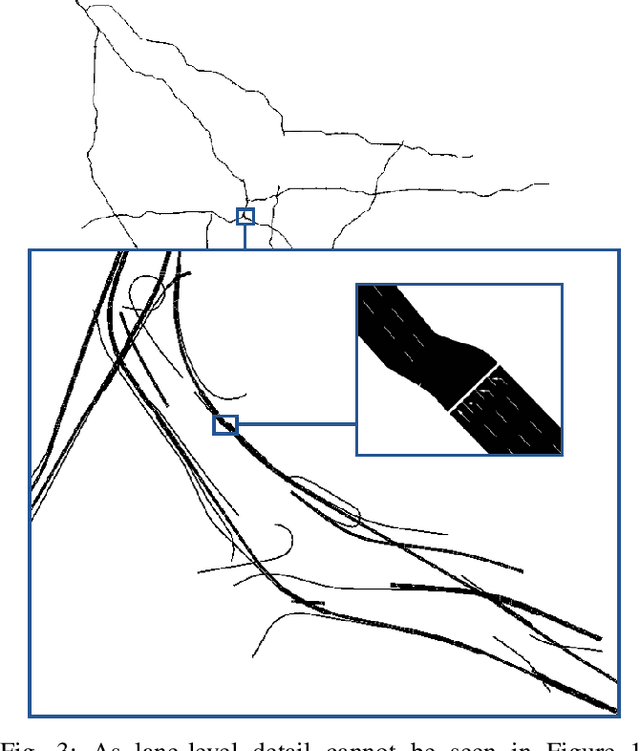
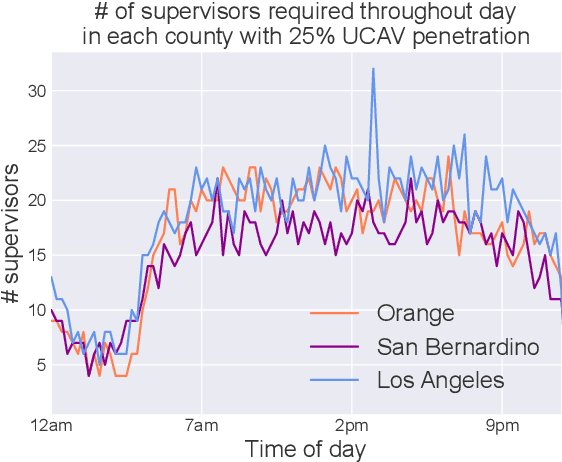
Autonomous driving is a highly anticipated approach toward eliminating roadway fatalities. At the same time, the bar for safety is both high and costly to verify. This work considers the role of remotely-located human operators supervising a fleet of autonomous vehicles (AVs) for safety. Such a 'scalable supervision' concept was previously proposed to bridge the gap between still-maturing autonomy technology and the pressure to begin commercial offerings of autonomous driving. The present article proposes DISCES, a framework for Data-Informed Safety-Critical Event Simulation, to investigate the practicality of this concept from a dynamic network loading standpoint. With a focus on the safety-critical context of AVs merging into mixed-autonomy traffic, vehicular arrival processes at 1,097 highway merge points are modeled using microscopic traffic reconstruction with historical data from interstates across three California counties. Combined with a queuing theoretic model, these results characterize the dynamic supervision requirements and thereby scalability of the teleoperation approach. Across all scenarios we find reductions in operator requirements greater than 99% as compared to in-vehicle supervisors for the time period analyzed. The work also demonstrates two methods for reducing these empirical supervision requirements: (i) the use of cooperative connected AVs -- which are shown to produce an average 3.67 orders-of-magnitude system reliability improvement across the scenarios studied -- and (ii) aggregation across larger regions.
Multi-agent Path Finding for Mixed Autonomy Traffic Coordination
Sep 05, 2024



In the evolving landscape of urban mobility, the prospective integration of Connected and Automated Vehicles (CAVs) with Human-Driven Vehicles (HDVs) presents a complex array of challenges and opportunities for autonomous driving systems. While recent advancements in robotics have yielded Multi-Agent Path Finding (MAPF) algorithms tailored for agent coordination task characterized by simplified kinematics and complete control over agent behaviors, these solutions are inapplicable in mixed-traffic environments where uncontrollable HDVs must coexist and interact with CAVs. Addressing this gap, we propose the Behavior Prediction Kinematic Priority Based Search (BK-PBS), which leverages an offline-trained conditional prediction model to forecast HDV responses to CAV maneuvers, integrating these insights into a Priority Based Search (PBS) where the A* search proceeds over motion primitives to accommodate kinematic constraints. We compare BK-PBS with CAV planning algorithms derived by rule-based car-following models, and reinforcement learning. Through comprehensive simulation on a highway merging scenario across diverse scenarios of CAV penetration rate and traffic density, BK-PBS outperforms these baselines in reducing collision rates and enhancing system-level travel delay. Our work is directly applicable to many scenarios of multi-human multi-robot coordination.
Multi-agent Path Finding for Cooperative Autonomous Driving
Feb 01, 2024


Anticipating possible future deployment of connected and automated vehicles (CAVs), cooperative autonomous driving at intersections has been studied by many works in control theory and intelligent transportation across decades. Simultaneously, recent parallel works in robotics have devised efficient algorithms for multi-agent path finding (MAPF), though often in environments with simplified kinematics. In this work, we hybridize insights and algorithms from MAPF with the structure and heuristics of optimizing the crossing order of CAVs at signal-free intersections. We devise an optimal and complete algorithm, Order-based Search with Kinematics Arrival Time Scheduling (OBS-KATS), which significantly outperforms existing algorithms, fixed heuristics, and prioritized planning with KATS. The performance is maintained under different vehicle arrival rates, lane lengths, crossing speeds, and control horizon. Through ablations and dissections, we offer insight on the contributing factors to OBS-KATS's performance. Our work is directly applicable to many similarly scaled traffic and multi-robot scenarios with directed lanes.
Unified Automatic Control of Vehicular Systems with Reinforcement Learning
Jul 30, 2022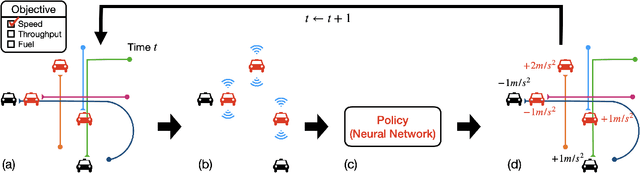
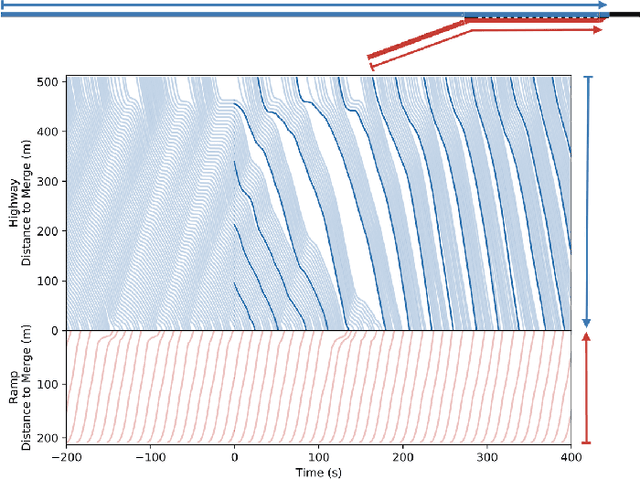
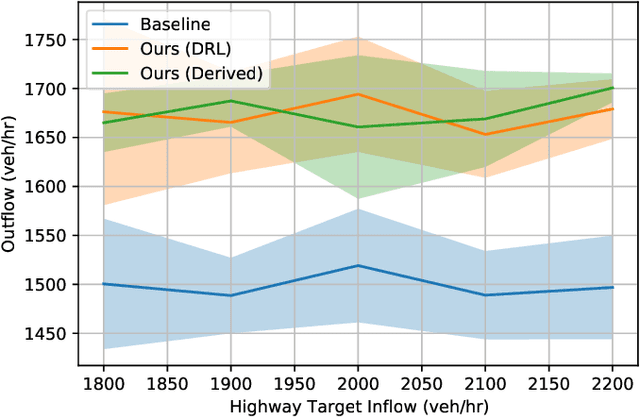

Emerging vehicular systems with increasing proportions of automated components present opportunities for optimal control to mitigate congestion and increase efficiency. There has been a recent interest in applying deep reinforcement learning (DRL) to these nonlinear dynamical systems for the automatic design of effective control strategies. Despite conceptual advantages of DRL being model-free, studies typically nonetheless rely on training setups that are painstakingly specialized to specific vehicular systems. This is a key challenge to efficient analysis of diverse vehicular and mobility systems. To this end, this article contributes a streamlined methodology for vehicular microsimulation and discovers high performance control strategies with minimal manual design. A variable-agent, multi-task approach is presented for optimization of vehicular Partially Observed Markov Decision Processes. The methodology is experimentally validated on mixed autonomy traffic systems, where fractions of vehicles are automated; empirical improvement, typically 15-60% over a human driving baseline, is observed in all configurations of six diverse open or closed traffic systems. The study reveals numerous emergent behaviors resembling wave mitigation, traffic signaling, and ramp metering. Finally, the emergent behaviors are analyzed to produce interpretable control strategies, which are validated against the learned control strategies.
Reinforcement Learning for Mixed Autonomy Intersections
Nov 08, 2021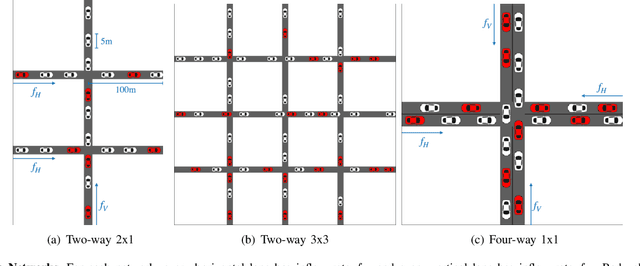
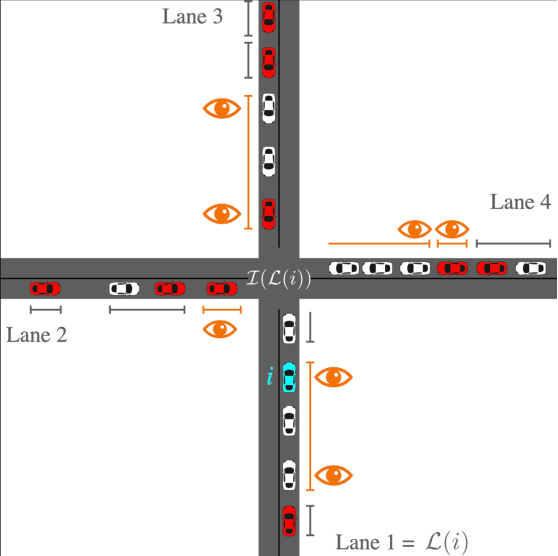
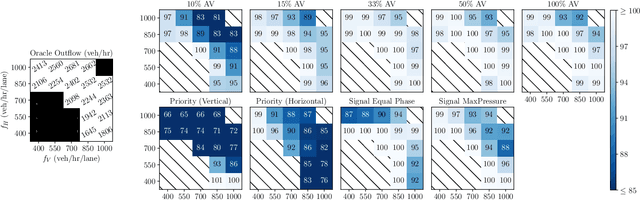
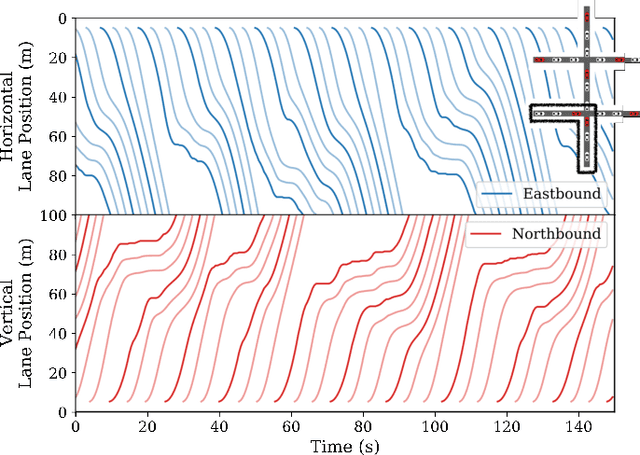
We propose a model-free reinforcement learning method for controlling mixed autonomy traffic in simulated traffic networks with through-traffic-only two-way and four-way intersections. Our method utilizes multi-agent policy decomposition which allows decentralized control based on local observations for an arbitrary number of controlled vehicles. We demonstrate that, even without reward shaping, reinforcement learning learns to coordinate the vehicles to exhibit traffic signal-like behaviors, achieving near-optimal throughput with 33-50% controlled vehicles. With the help of multi-task learning and transfer learning, we show that this behavior generalizes across inflow rates and size of the traffic network. Our code, models, and videos of results are available at https://github.com/ZhongxiaYan/mixed_autonomy_intersections.
* 7 pages, 6 figures, ITSC 2021, 2021 IEEE International Conference on Intelligent Transportation Systems (ITSC)
Learning to Delegate for Large-scale Vehicle Routing
Jul 08, 2021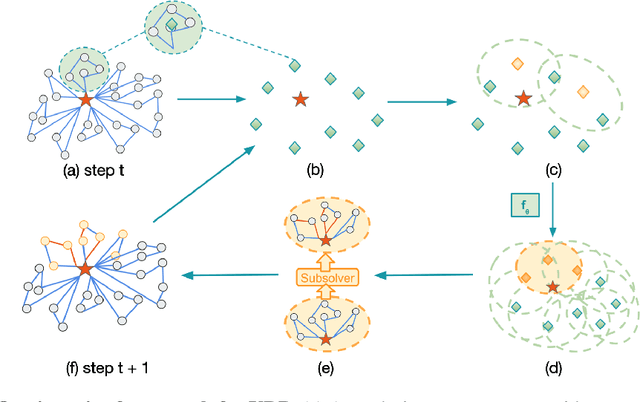
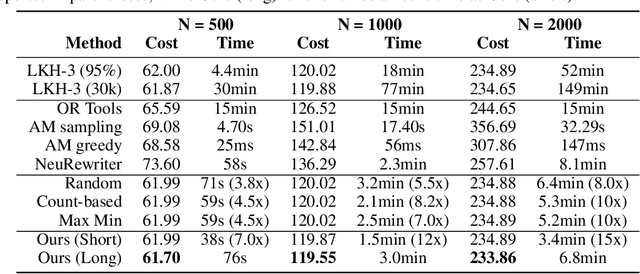
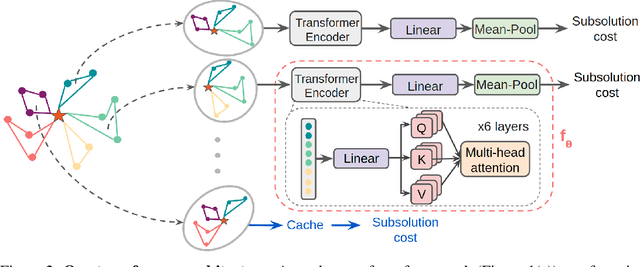
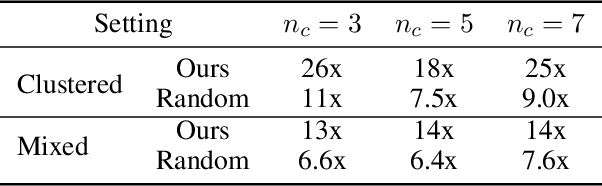
Vehicle routing problems (VRPs) are a class of combinatorial problems with wide practical applications. While previous heuristic or learning-based works achieve decent solutions on small problem instances of up to 100 customers, their performance does not scale to large problems. This article presents a novel learning-augmented local search algorithm to solve large-scale VRP. The method iteratively improves the solution by identifying appropriate subproblems and $\textit{delegating}$ their improvement to a black box subsolver. At each step, we leverage spatial locality to consider only a linear number of subproblems, rather than exponential. We frame subproblem selection as a regression problem and train a Transformer on a generated training set of problem instances. We show that our method achieves state-of-the-art performance, with a speed-up of up to 15 times over strong baselines, on VRPs with sizes ranging from 500 to 3000.
MicroNet for Efficient Language Modeling
May 16, 2020
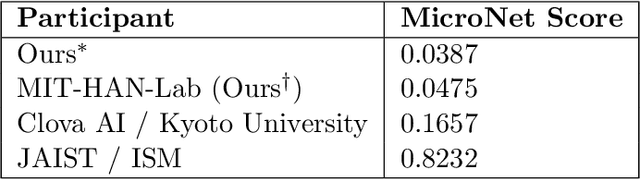

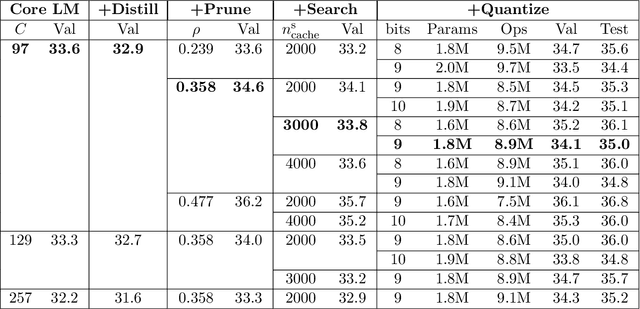
It is important to design compact language models for efficient deployment. We improve upon recent advances in both the language modeling domain and the model-compression domain to construct parameter and computation efficient language models. We use an efficient transformer-based architecture with adaptive embedding and softmax, differentiable non-parametric cache, Hebbian softmax, knowledge distillation, network pruning, and low-bit quantization. In this paper, we provide the winning solution to the NeurIPS 2019 MicroNet Challenge in the language modeling track. Compared to the baseline language model provided by the MicroNet Challenge, our model is 90 times more parameter-efficient and 36 times more computation-efficient while achieving the required test perplexity of 35 on the Wikitext-103 dataset. We hope that this work will aid future research into efficient language models, and we have released our full source code at https://github.com/mit-han-lab/neurips-micronet.
Hierarchical Model for Long-term Video Prediction
Jul 03, 2017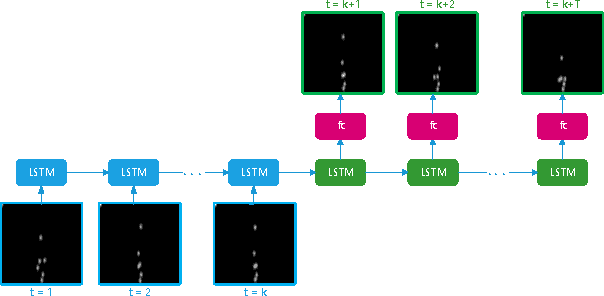
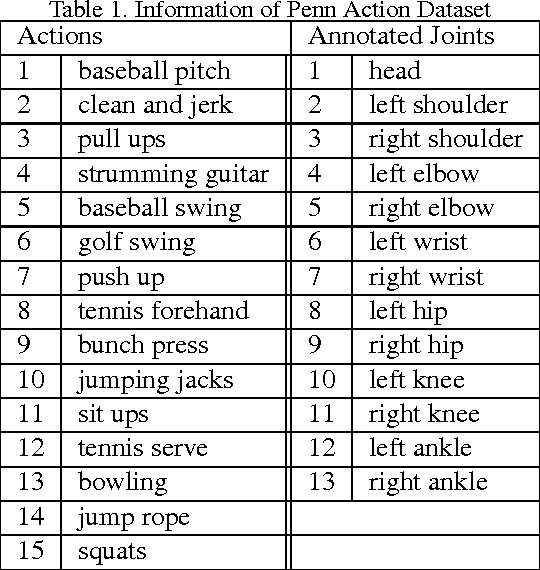

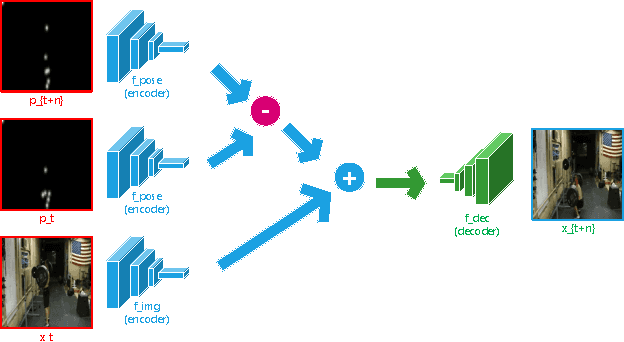
Video prediction has been an active topic of research in the past few years. Many algorithms focus on pixel-level predictions, which generates results that blur and disintegrate within a few frames. In this project, we use a hierarchical approach for long-term video prediction. We aim at estimating high-level structure in the input frame first, then predict how that structure grows in the future. Finally, we use an image analogy network to recover a realistic image from the predicted structure. Our method is largely adopted from the work by Villegas et al. The method is built with a combination of LSTMs and analogy-based convolutional auto-encoder networks. Additionally, in order to generate more realistic frame predictions, we also adopt adversarial loss. We evaluate our method on the Penn Action dataset, and demonstrate good results on high-level long-term structure prediction.