 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Model for Long-term Video Prediction
Paper and Code
Jul 03, 2017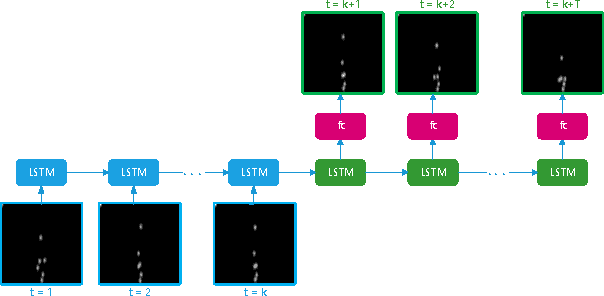
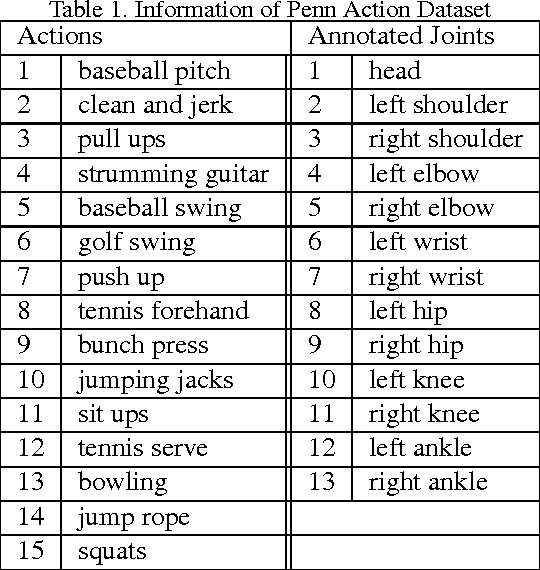

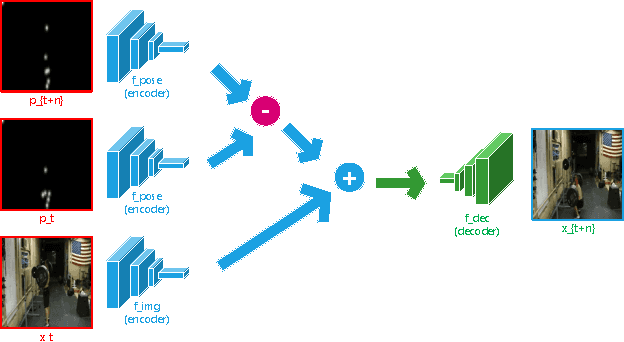
Video prediction has been an active topic of research in the past few years. Many algorithms focus on pixel-level predictions, which generates results that blur and disintegrate within a few frames. In this project, we use a hierarchical approach for long-term video prediction. We aim at estimating high-level structure in the input frame first, then predict how that structure grows in the future. Finally, we use an image analogy network to recover a realistic image from the predicted structure. Our method is largely adopted from the work by Villegas et al. The method is built with a combination of LSTMs and analogy-based convolutional auto-encoder networks. Additionally, in order to generate more realistic frame predictions, we also adopt adversarial loss. We evaluate our method on the Penn Action dataset, and demonstrate good results on high-level long-term structure prediction.