 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Paper and Code
Mar 31, 2021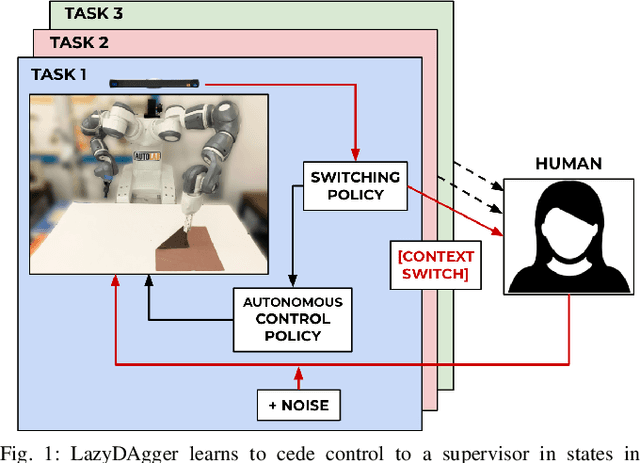
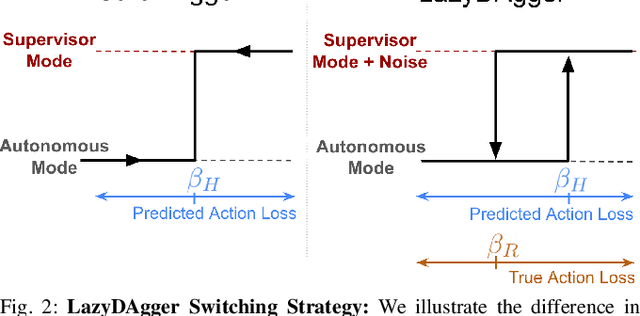
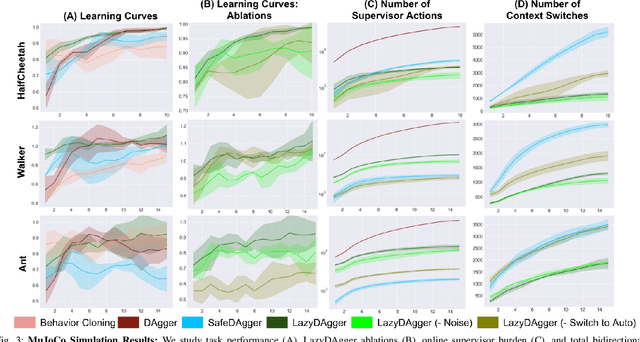
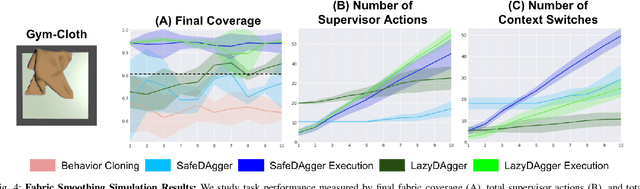
Corrective interventions while a robot is learning to automate a task provide an intuitive method for a human supervisor to assist the robot and convey information about desired behavior. However, these interventions can impose significant burden on a human supervisor, as each intervention interrupts other work the human is doing, incurs latency with each context switch between supervisor and autonomous control, and requires time to perform. We present LazyDAgger, which extends the interactive imitation learning (IL) algorithm SafeDAgger to reduce context switches between supervisor and autonomous control. We find that LazyDAgger improves the performance and robustness of the learned policy during both learning and execution while limiting burden on the supervisor. Simulation experiments suggest that LazyDAgger can reduce context switches by an average of 60% over SafeDAgger on 3 continuous control tasks while maintaining state-of-the-art policy performance. In physical fabric manipulation experiments with an ABB YuMi robot, LazyDAgger reduces context switches by 60% while achieving a 60% higher success rate than SafeDAgger at execution time.