 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClicks Versus Conversion: Choosing a Recommender's Training Objective in E-Commerce
Aug 14, 2025



Ranking product recommendations to optimize for a high click-through rate (CTR) or for high conversion, such as add-to-cart rate (ACR) and Order-Submit-Rate (OSR, view-to-purchase conversion) are standard practices in e-commerce. Optimizing for CTR appears like a straightforward choice: Training data (i.e., click data) are simple to collect and often available in large quantities. Additionally, CTR is used far beyond e-commerce, making it a generalist, easily implemented option. ACR and OSR, on the other hand, are more directly linked to a shop's business goals, such as the Gross Merchandise Value (GMV). In this paper, we compare the effects of using either of these objectives using an online A/B test. Among our key findings, we demonstrate that in our shops, optimizing for OSR produces a GMV uplift more than five times larger than when optimizing for CTR, without sacrificing new product discovery. Our results also provide insights into the different feature importances for each of the objectives.
Fine-Tuning Topics through Weighting Aspect Keywords
Feb 12, 2025Topic modeling often requires examining topics from multiple perspectives to uncover hidden patterns, especially in less explored areas. This paper presents an approach to address this need, utilizing weighted keywords from various aspects derived from a domain knowledge. The research method starts with standard topic modeling. Then, it adds a process consisting of four key steps. First, it defines keywords for each aspect. Second, it gives weights to these keywords based on their relevance. Third, it calculates relevance scores for aspect-weighted keywords and topic keywords to create aspect-topic models. Fourth, it uses these scores to tune relevant new documents. Finally, the generated topic models are interpreted and validated. The findings show that top-scoring documents are more likely to be about the same aspect of a topic. This highlights the model's effectiveness in finding the related documents to the aspects.
An Exploration of Pattern Mining with ChatGPT
Dec 22, 2024



This paper takes an exploratory approach to examine the use of ChatGPT for pattern mining. It proposes an eight-step collaborative process that combines human insight with AI capabilities to extract patterns from known uses. The paper offers a practical demonstration of this process by creating a pattern language for integrating Large Language Models (LLMs) with data sources and tools. LLMs, such as ChatGPT, are a new class of AI models that have been trained on large amounts of text, and can create new content, including text, images, or video. The paper also argues for adding affordances of the underlying components as a new element of pattern descriptions. The primary audience of the paper includes pattern writers interested in pattern mining using LLMs.
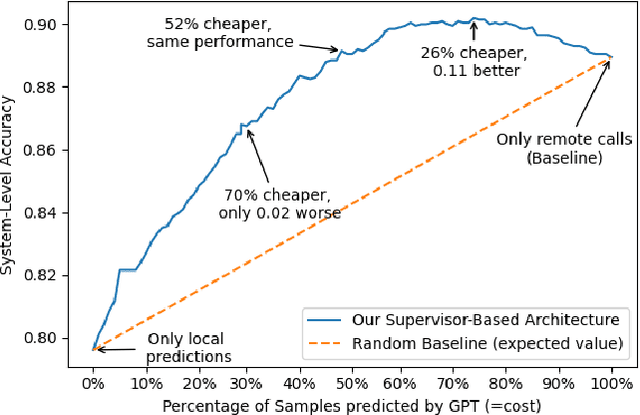
Adopting Two Supervisors for Efficient Use of Large-Scale Remote Deep Neural Networks
Apr 05, 2023Recent decades have seen the rise of large-scale Deep Neural Networks (DNNs) to achieve human-competitive performance in a variety of artificial intelligence tasks. Often consisting of hundreds of millions, if not hundreds of billion parameters, these DNNs are too large to be deployed to, or efficiently run on resource-constrained devices such as mobile phones or IoT microcontrollers. Systems relying on large-scale DNNs thus have to call the corresponding model over the network, leading to substantial costs for hosting and running the large-scale remote model, costs which are often charged on a per-use basis. In this paper, we propose BiSupervised, a novel architecture, where, before relying on a large remote DNN, a system attempts to make a prediction on a small-scale local model. A DNN supervisor monitors said prediction process and identifies easy inputs for which the local prediction can be trusted. For these inputs, the remote model does not have to be invoked, thus saving costs, while only marginally impacting the overall system accuracy. Our architecture furthermore foresees a second supervisor to monitor the remote predictions and identify inputs for which not even these can be trusted, allowing to raise an exception or run a fallback strategy instead. We evaluate the cost savings, and the ability to detect incorrectly predicted inputs on four diverse case studies: IMDB movie review sentiment classification, Github issue triaging, Imagenet image classification, and SQuADv2 free-text question answering
Uncertainty Quantification for Deep Neural Networks: An Empirical Comparison and Usage Guidelines
Dec 14, 2022Deep Neural Networks (DNN) are increasingly used as components of larger software systems that need to process complex data, such as images, written texts, audio/video signals. DNN predictions cannot be assumed to be always correct for several reasons, among which the huge input space that is dealt with, the ambiguity of some inputs data, as well as the intrinsic properties of learning algorithms, which can provide only statistical warranties. Hence, developers have to cope with some residual error probability. An architectural pattern commonly adopted to manage failure-prone components is the supervisor, an additional component that can estimate the reliability of the predictions made by untrusted (e.g., DNN) components and can activate an automated healing procedure when these are likely to fail, ensuring that the Deep Learning based System (DLS) does not cause damages, despite its main functionality being suspended. In this paper, we consider DLS that implement a supervisor by means of uncertainty estimation. After overviewing the main approaches to uncertainty estimation and discussing their pros and cons, we motivate the need for a specific empirical assessment method that can deal with the experimental setting in which supervisors are used, where the accuracy of the DNN matters only as long as the supervisor lets the DLS continue to operate. Then we present a large empirical study conducted to compare the alternative approaches to uncertainty estimation. We distilled a set of guidelines for developers that are useful to incorporate a supervisor based on uncertainty monitoring into a DLS.
CheapET-3: Cost-Efficient Use of Remote DNN Models
Aug 24, 2022
On complex problems, state of the art prediction accuracy of Deep Neural Networks (DNN) can be achieved using very large-scale models, consisting of billions of parameters. Such models can only be run on dedicated servers, typically provided by a 3rd party service, which leads to a substantial monetary cost for every prediction. We propose a new software architecture for client-side applications, where a small local DNN is used alongside a remote large-scale model, aiming to make easy predictions locally at negligible monetary cost, while still leveraging the benefits of a large model for challenging inputs. In a proof of concept we reduce prediction cost by up to 50% without negatively impacting system accuracy.
A Forgotten Danger in DNN Supervision Testing: Generating and Detecting True Ambiguity
Jul 21, 2022
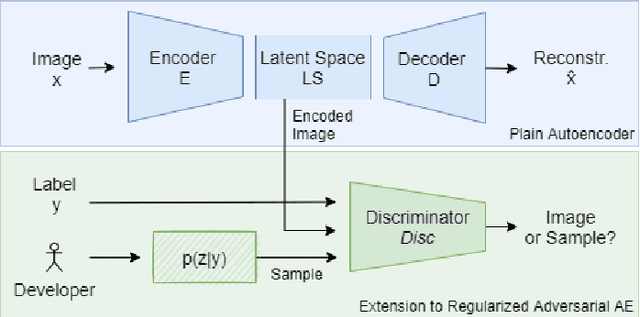
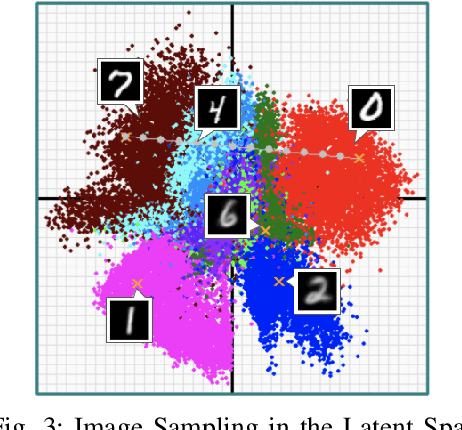
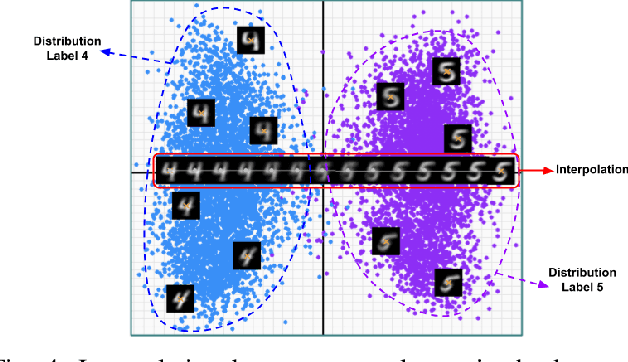
Deep Neural Networks (DNNs) are becoming a crucial component of modern software systems, but they are prone to fail under conditions that are different from the ones observed during training (out-of-distribution inputs) or on inputs that are truly ambiguous, i.e., inputs that admit multiple classes with nonzero probability in their ground truth labels. Recent work proposed DNN supervisors to detect high-uncertainty inputs before their possible misclassification leads to any harm. To test and compare the capabilities of DNN supervisors, researchers proposed test generation techniques, to focus the testing effort on high-uncertainty inputs that should be recognized as anomalous by supervisors. However, existing test generators can only produce out-of-distribution inputs. No existing model- and supervisor-independent technique supports the generation of truly ambiguous test inputs. In this paper, we propose a novel way to generate ambiguous inputs to test DNN supervisors and used it to empirically compare several existing supervisor techniques. In particular, we propose AmbiGuess to generate ambiguous samples for image classification problems. AmbiGuess is based on gradient-guided sampling in the latent space of a regularized adversarial autoencoder. Moreover, we conducted what is - to the best of our knowledge - the most extensive comparative study of DNN supervisors, considering their capabilities to detect 4 distinct types of high-uncertainty inputs, including truly ambiguous ones.
Simple Techniques Work Surprisingly Well for Neural Network Test Prioritization and Active Learning (Replicability Study)
May 02, 2022

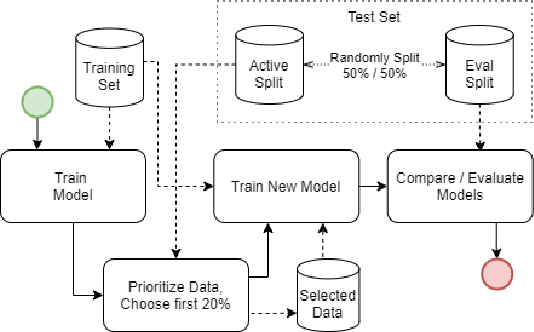
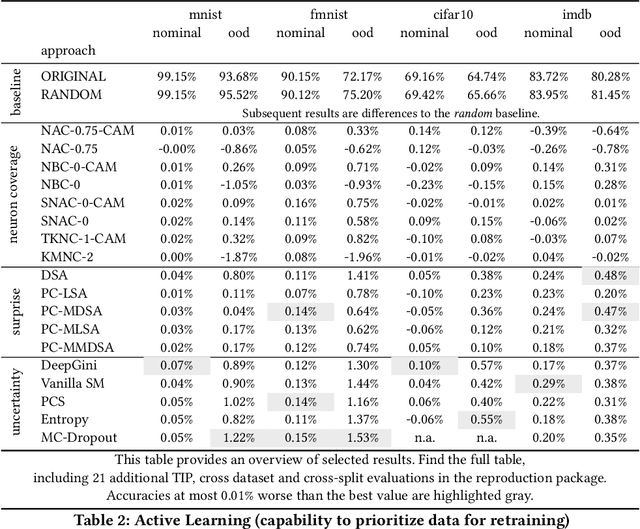
Test Input Prioritizers (TIP) for Deep Neural Networks (DNN) are an important technique to handle the typically very large test datasets efficiently, saving computation and labeling costs. This is particularly true for large-scale, deployed systems, where inputs observed in production are recorded to serve as potential test or training data for the next versions of the system. Feng et. al. propose DeepGini, a very fast and simple TIP, and show that it outperforms more elaborate techniques such as neuron- and surprise coverage. In a large-scale study (4 case studies, 8 test datasets, 32'200 trained models) we verify their findings. However, we also find that other comparable or even simpler baselines from the field of uncertainty quantification, such as the predicted softmax likelihood or the entropy of the predicted softmax likelihoods perform equally well as DeepGini.
A Review and Refinement of Surprise Adequacy
Mar 10, 2021
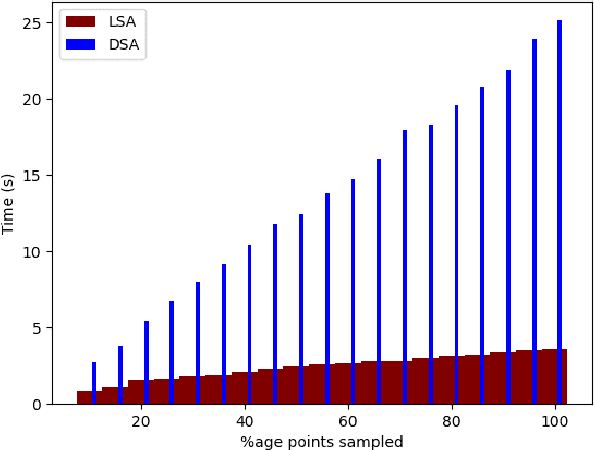
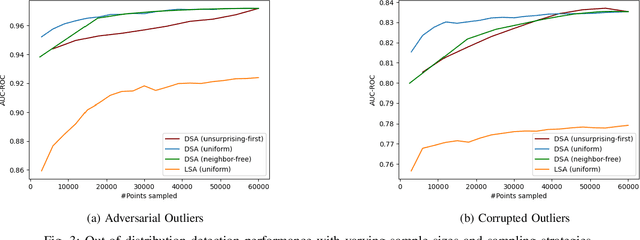
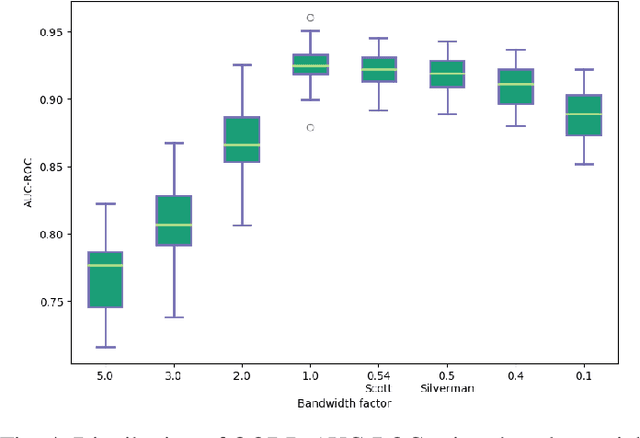
Surprise Adequacy (SA) is one of the emerging and most promising adequacy criteria for Deep Learning (DL) testing. As an adequacy criterion, it has been used to assess the strength of DL test suites. In addition, it has also been used to find inputs to a Deep Neural Network (DNN) which were not sufficiently represented in the training data, or to select samples for DNN retraining. However, computation of the SA metric for a test suite can be prohibitively expensive, as it involves a quadratic number of distance calculations. Hence, we developed and released a performance-optimized, but functionally equivalent, implementation of SA, reducing the evaluation time by up to 97\%. We also propose refined variants of the SA omputation algorithm, aiming to further increase the evaluation speed. We then performed an empirical study on MNIST, focused on the out-of-distribution detection capabilities of SA, which allowed us to reproduce parts of the results presented when SA was first released. The experiments show that our refined variants are substantially faster than plain SA, while producing comparable outcomes. Our experimental results exposed also an overlooked issue of SA: it can be highly sensitive to the non-determinism associated with the DNN training procedure.
Fail-Safe Execution of Deep Learning based Systems through Uncertainty Monitoring
Feb 01, 2021
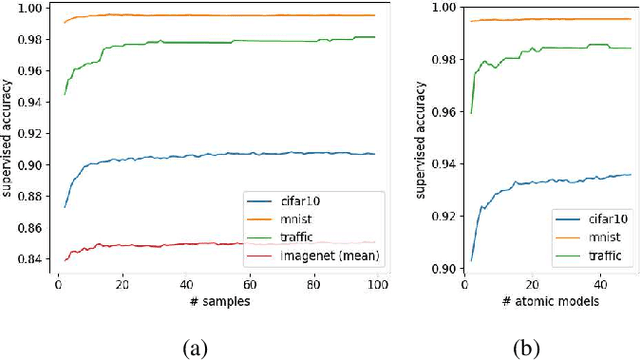
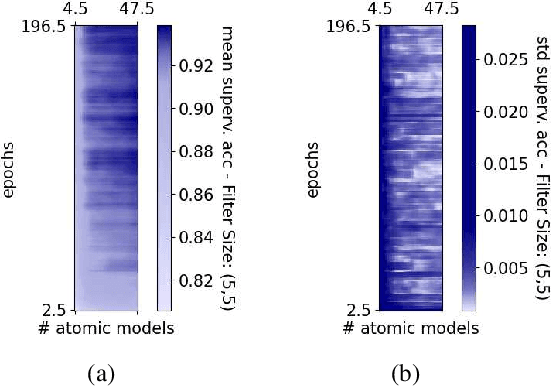
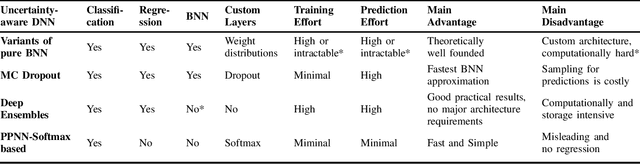
Modern software systems rely on Deep Neural Networks (DNN) when processing complex, unstructured inputs, such as images, videos, natural language texts or audio signals. Provided the intractably large size of such input spaces, the intrinsic limitations of learning algorithms, and the ambiguity about the expected predictions for some of the inputs, not only there is no guarantee that DNN's predictions are always correct, but rather developers must safely assume a low, though not negligible, error probability. A fail-safe Deep Learning based System (DLS) is one equipped to handle DNN faults by means of a supervisor, capable of recognizing predictions that should not be trusted and that should activate a healing procedure bringing the DLS to a safe state. In this paper, we propose an approach to use DNN uncertainty estimators to implement such a supervisor. We first discuss the advantages and disadvantages of existing approaches to measure uncertainty for DNNs and propose novel metrics for the empirical assessment of the supervisor that rely on such approaches. We then describe our publicly available tool UNCERTAINTY-WIZARD, which allows transparent estimation of uncertainty for regular tf.keras DNNs. Lastly, we discuss a large-scale study conducted on four different subjects to empirically validate the approach, reporting the lessons-learned as guidance for software engineers who intend to monitor uncertainty for fail-safe execution of DLS.