 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointNeRF++: A multi-scale, point-based Neural Radiance Field
Dec 04, 2023



Point clouds offer an attractive source of information to complement images in neural scene representations, especially when few images are available. Neural rendering methods based on point clouds do exist, but they do not perform well when the point cloud quality is low -- e.g., sparse or incomplete, which is often the case with real-world data. We overcome these problems with a simple representation that aggregates point clouds at multiple scale levels with sparse voxel grids at different resolutions. To deal with point cloud sparsity, we average across multiple scale levels -- but only among those that are valid, i.e., that have enough neighboring points in proximity to the ray of a pixel. To help model areas without points, we add a global voxel at the coarsest scale, thus unifying "classical" and point-based NeRF formulations. We validate our method on the NeRF Synthetic, ScanNet, and KITTI-360 datasets, outperforming the state of the art by a significant margin.
Orbeez-SLAM: A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
Sep 27, 2022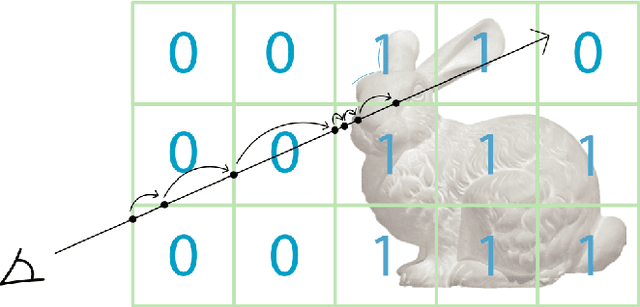
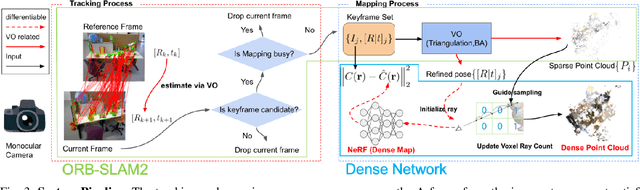
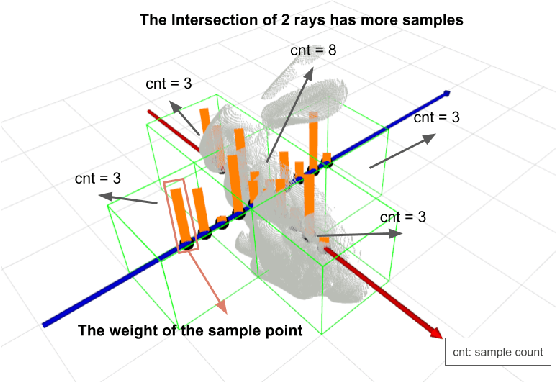

A spatial AI that can perform complex tasks through visual signals and cooperate with humans is highly anticipated. To achieve this, we need a visual SLAM that easily adapts to new scenes without pre-training and generates dense maps for downstream tasks in real-time. None of the previous learning-based and non-learning-based visual SLAMs satisfy all needs due to the intrinsic limitations of their components. In this work, we develop a visual SLAM named Orbeez-SLAM, which successfully collaborates with implicit neural representation (NeRF) and visual odometry to achieve our goals. Moreover, Orbeez-SLAM can work with the monocular camera since it only needs RGB inputs, making it widely applicable to the real world. We validate its effectiveness on various challenging benchmarks. Results show that our SLAM is up to 800x faster than the strong baseline with superior rendering outcomes.