 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Sep 22, 2024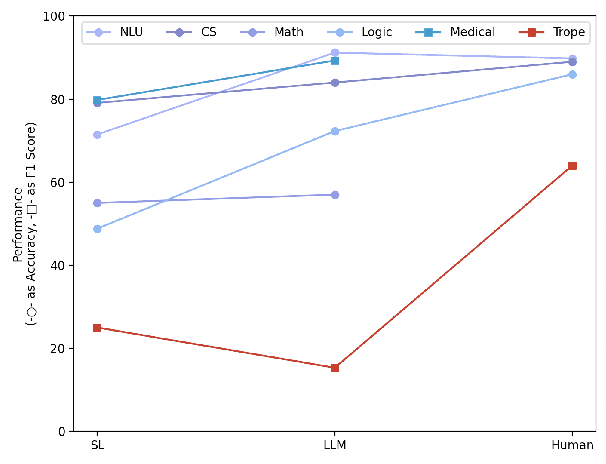

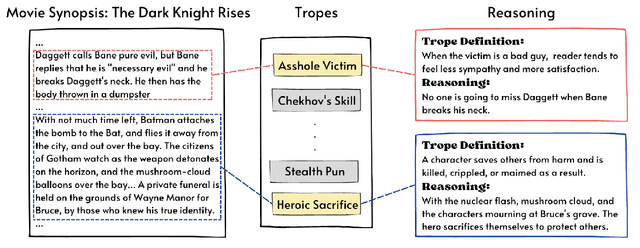

Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
Orbeez-SLAM: A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
Sep 27, 2022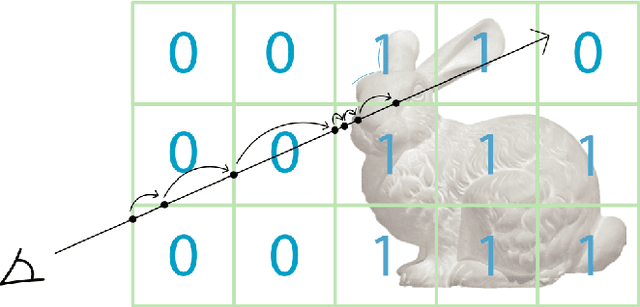
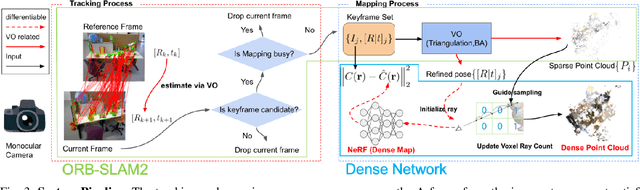

A spatial AI that can perform complex tasks through visual signals and cooperate with humans is highly anticipated. To achieve this, we need a visual SLAM that easily adapts to new scenes without pre-training and generates dense maps for downstream tasks in real-time. None of the previous learning-based and non-learning-based visual SLAMs satisfy all needs due to the intrinsic limitations of their components. In this work, we develop a visual SLAM named Orbeez-SLAM, which successfully collaborates with implicit neural representation (NeRF) and visual odometry to achieve our goals. Moreover, Orbeez-SLAM can work with the monocular camera since it only needs RGB inputs, making it widely applicable to the real world. We validate its effectiveness on various challenging benchmarks. Results show that our SLAM is up to 800x faster than the strong baseline with superior rendering outcomes.