 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-EHN: Commonsense Word Analogy from E-HowNet
Paper and Code
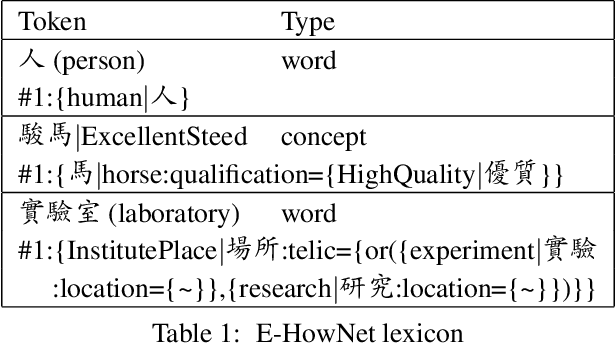

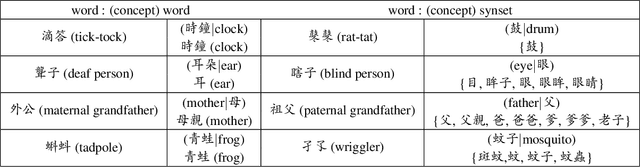
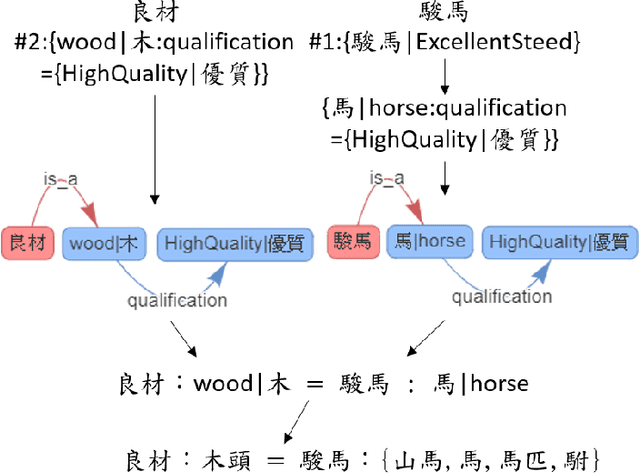
Word analogy tasks have tended to be handcrafted, involving permutations of hundreds of words with dozens of relations, mostly morphological relations and named entities. Here, we propose modeling commonsense knowledge down to word-level analogical reasoning. We present CA-EHN, the first commonsense word analogy dataset containing 85K analogies covering 5K words and 6K commonsense relations. This was compiled by leveraging E-HowNet, an ontology that annotates 88K Chinese words with their structured sense definitions and English translations. Experiments show that CA-EHN stands out as a great indicator of how well word representations embed commonsense structures, which is crucial for future end-to-end models to generalize inference beyond training corpora. The dataset is publicly available at \url{https://github.com/jacobvsdanniel/CA-EHN}.