 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Attention? Analyzing and Remedying BiLSTM Deficiency in Modeling Cross-Context for NER
Oct 07, 2019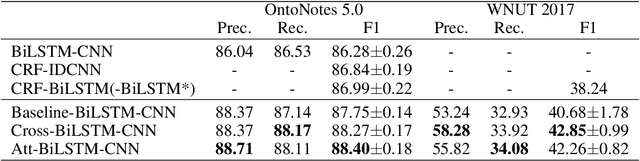



State-of-the-art approaches of NER have used sequence-labeling BiLSTM as a core module. This paper formally shows the limitation of BiLSTM in modeling cross-context patterns. Two types of simple cross-structures -- self-attention and Cross-BiLSTM -- are shown to effectively remedy the problem. On both OntoNotes 5.0 and WNUT 2017, clear and consistent improvements are achieved over bare-bone models, up to 8.7% on some of the multi-token mentions. In-depth analyses across several aspects of the improvements, especially the identification of multi-token mentions, are further given.
Remedying BiLSTM-CNN Deficiency in Modeling Cross-Context for NER
Aug 29, 2019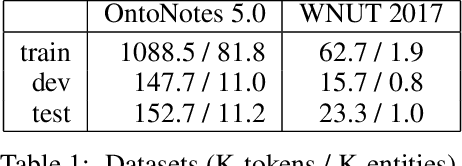

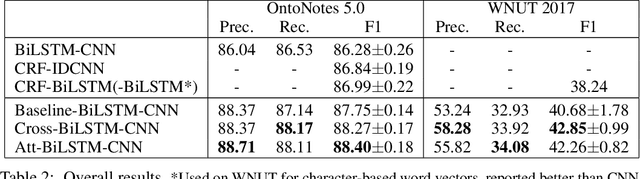
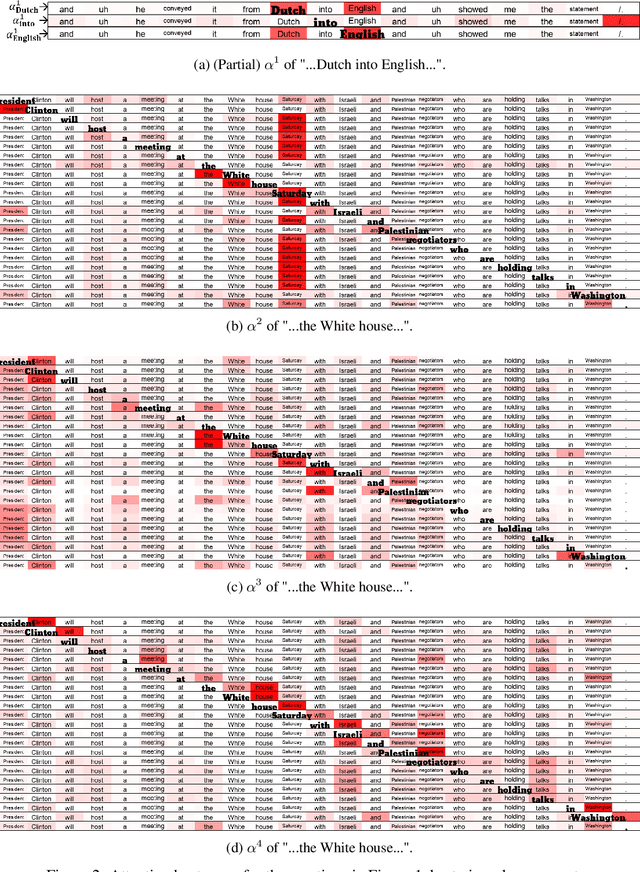
Recent researches prevalently used BiLSTM-CNN as a core module for NER in a sequence-labeling setup. This paper formally shows the limitation of BiLSTM-CNN encoders in modeling cross-context patterns for each word, i.e., patterns crossing past and future for a specific time step. Two types of cross-structures are used to remedy the problem: A BiLSTM variant with cross-link between layers; a multi-head self-attention mechanism. These cross-structures bring consistent improvements across a wide range of NER domains for a core system using BiLSTM-CNN without additional gazetteers, POS taggers, language-modeling, or multi-task supervision. The model surpasses comparable previous models on OntoNotes 5.0 and WNUT 2017 by 1.4% and 4.6%, especially improving emerging, complex, confusing, and multi-token entity mentions, showing the importance of remedying the core module of NER.
CA-EHN: Commonsense Word Analogy from E-HowNet
Aug 21, 2019

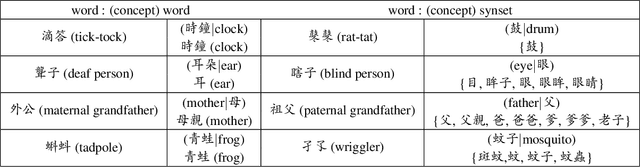
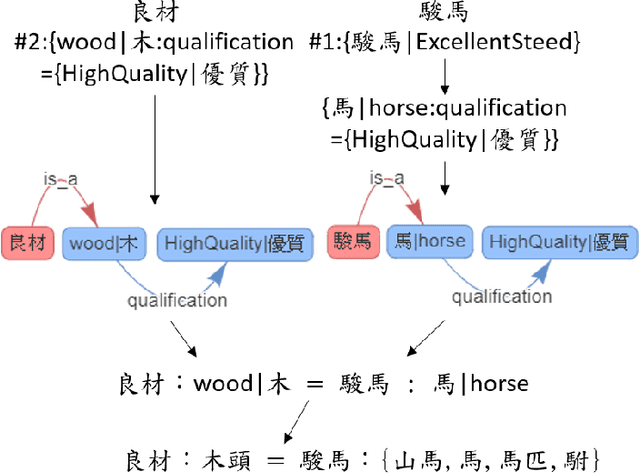
Word analogy tasks have tended to be handcrafted, involving permutations of hundreds of words with dozens of relations, mostly morphological relations and named entities. Here, we propose modeling commonsense knowledge down to word-level analogical reasoning. We present CA-EHN, the first commonsense word analogy dataset containing 85K analogies covering 5K words and 6K commonsense relations. This was compiled by leveraging E-HowNet, an ontology that annotates 88K Chinese words with their structured sense definitions and English translations. Experiments show that CA-EHN stands out as a great indicator of how well word representations embed commonsense structures, which is crucial for future end-to-end models to generalize inference beyond training corpora. The dataset is publicly available at \url{https://github.com/jacobvsdanniel/CA-EHN}.