 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3 with Test-Time Calibration for Automated Carotid Intima-Media Thickness Measurement on CUBS v1
Mar 11, 2026Carotid intima-media thickness (CIMT) measured from B-mode ultrasound is an established vascular biomarker for atherosclerosis and cardiovascular risk stratification. Although a wide range of computerized methods have been proposed for carotid boundary delineation and CIMT estimation, robust and transferable deep models that jointly address segmentation and measurement remain underexplored, particularly in the era of vision foundation models. Motivated by recent advances in adapting DINOv3 to medical segmentation and exploiting DINOv3 in test-time optimization pipelines, we investigate a DINOv3-based framework for carotid intima-media complex segmentation and subsequent CIMT measurement on the Carotid Ultrasound Boundary Study (CUBS) v1 dataset. Our pipeline predicts the intima-media band at a fixed image resolution, extracts upper and lower boundaries column-wise, corrects for image resizing using the per-image calibration factor provided by CUBS, and reports CIMT in physical units. Across three patient-level test splits, our method achieved a mean test Dice of 0.7739 $\pm$ 0.0037 and IoU of 0.6384 $\pm$ 0.0044. The mean CIMT absolute error was 181.16 $\pm$ 11.57 $μ$m, with a mean Pearson correlation of 0.480 $\pm$ 0.259. In a held-out validation subset ($n=28$), test-time threshold calibration reduced the mean absolute CIMT error from 141.0 $μ$m at the default threshold to 101.1 $μ$m at the measurement-optimized threshold, while simultaneously reducing systematic bias toward zero. Relative to the error ranges reported in the original CUBS benchmark for classical computerized methods, these results place a DINOv3-based approach within the clinically relevant $\sim$0.1 mm measurement regime. Together, our findings support the feasibility of using vision foundation models for interpretable, calibration-aware CIMT measurement.
MultiVis-Agent: A Multi-Agent Framework with Logic Rules for Reliable and Comprehensive Cross-Modal Data Visualization
Jan 26, 2026Real-world visualization tasks involve complex, multi-modal requirements that extend beyond simple text-to-chart generation, requiring reference images, code examples, and iterative refinement. Current systems exhibit fundamental limitations: single-modality input, one-shot generation, and rigid workflows. While LLM-based approaches show potential for these complex requirements, they introduce reliability challenges including catastrophic failures and infinite loop susceptibility. To address this gap, we propose MultiVis-Agent, a logic rule-enhanced multi-agent framework for reliable multi-modal and multi-scenario visualization generation. Our approach introduces a four-layer logic rule framework that provides mathematical guarantees for system reliability while maintaining flexibility. Unlike traditional rule-based systems, our logic rules are mathematical constraints that guide LLM reasoning rather than replacing it. We formalize the MultiVis task spanning four scenarios from basic generation to iterative refinement, and develop MultiVis-Bench, a benchmark with over 1,000 cases for multi-modal visualization evaluation. Extensive experiments demonstrate that our approach achieves 75.63% visualization score on challenging tasks, significantly outperforming baselines (57.54-62.79%), with task completion rates of 99.58% and code execution success rates of 94.56% (vs. 74.48% and 65.10% without logic rules), successfully addressing both complexity and reliability challenges in automated visualization generation.
Towards Robustness of Text-to-Visualization Translation against Lexical and Phrasal Variability
Apr 11, 2024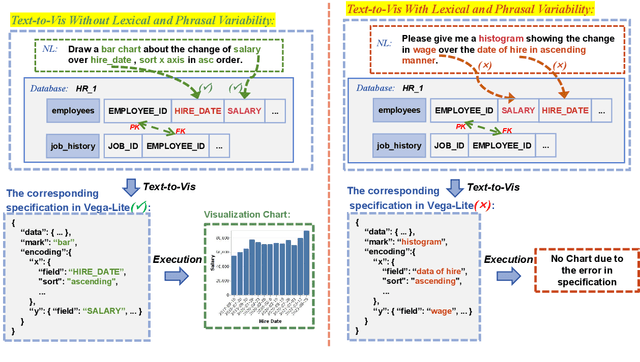
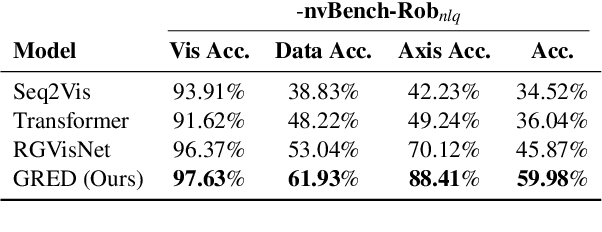
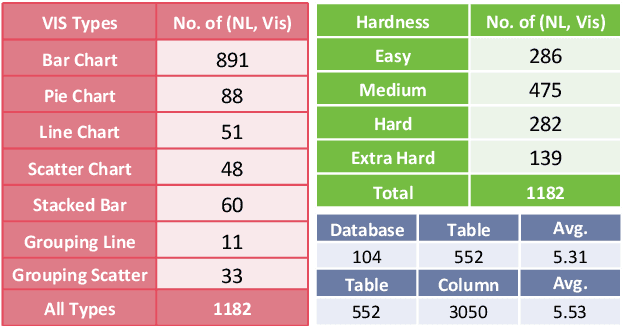
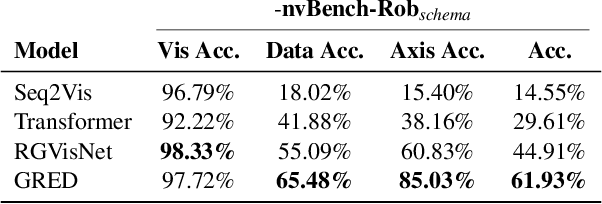
Text-to-Vis is an emerging task in the natural language processing (NLP) area that aims to automatically generate data visualizations from natural language questions (NLQs). Despite their progress, existing text-to-vis models often heavily rely on lexical matching between words in the questions and tokens in data schemas. This overreliance on lexical matching may lead to a diminished level of model robustness against input variations. In this study, we thoroughly examine the robustness of current text-to-vis models, an area that has not previously been explored. In particular, we construct the first robustness dataset nvBench-Rob, which contains diverse lexical and phrasal variations based on the original text-to-vis benchmark nvBench. Then, we found that the performance of existing text-to-vis models on this new dataset dramatically drops, implying that these methods exhibit inadequate robustness overall. Finally, we propose a novel framework based on Retrieval-Augmented Generation (RAG) technique, named GRED, specifically designed to address input perturbations in these two variants. The framework consists of three parts: NLQ-Retrieval Generator, Visualization Query-Retrieval Retuner and Annotation-based Debugger, which are used to tackle the challenges posed by natural language variants, programming style differences and data schema variants, respectively. Extensive experimental evaluations show that, compared to the state-of-the-art model RGVisNet in the Text-to-Vis field, GRED performs better in terms of model robustness, with a 32% increase in accuracy on the proposed nvBench-Rob dataset.
Application of Neural Network Algorithm in Propylene Distillation
Apr 05, 2021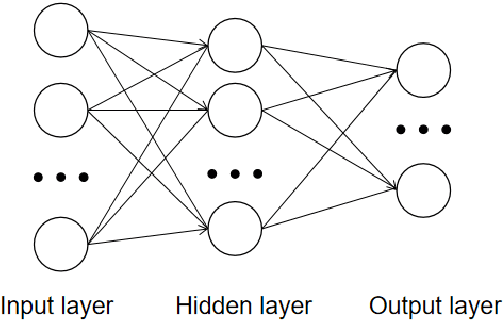
Artificial neural network modeling does not need to consider the mechanism. It can map the implicit relationship between input and output and predict the performance of the system well. At the same time, it has the advantages of self-learning ability and high fault tolerance. The gas-liquid two phases in the rectification tower conduct interphase heat and mass transfer through countercurrent contact. The functional relationship between the product concentration at the top and bottom of the tower and the process parameters is extremely complex. The functional relationship can be accurately controlled by artificial neural network algorithms. The key components of the propylene distillation tower are the propane concentration at the top of the tower and the propylene concentration at the bottom of the tower. Accurate measurement of them plays a key role in increasing propylene yield in ethylene production enterprises. This article mainly introduces the neural network model and its application in the propylene distillation tower.
Neural network algorithm and its application in temperature control of distillation tower
Jan 03, 2021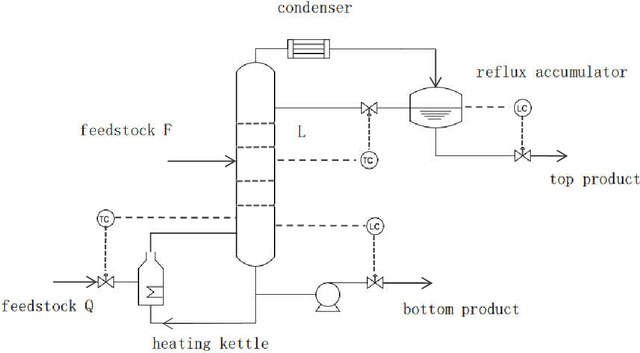
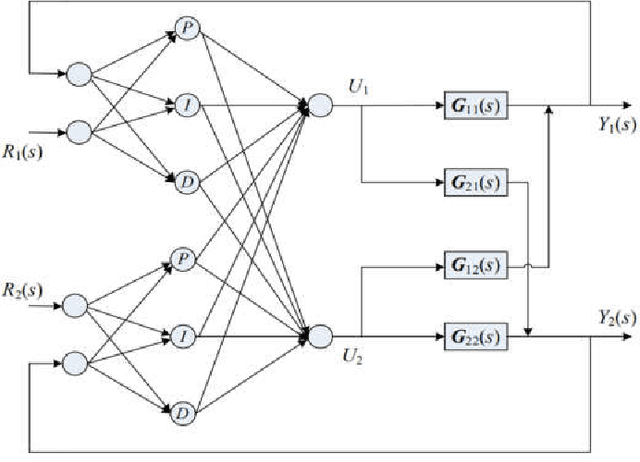
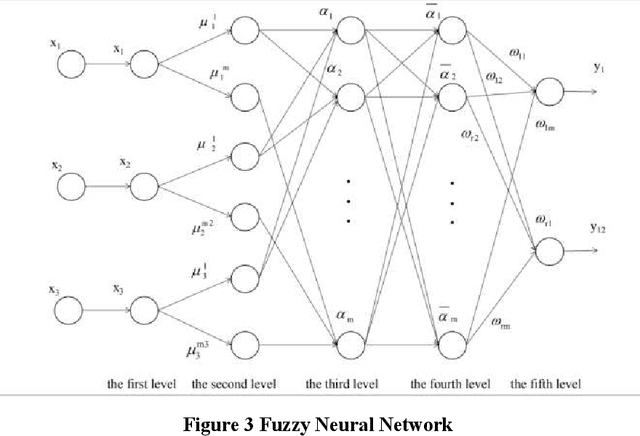
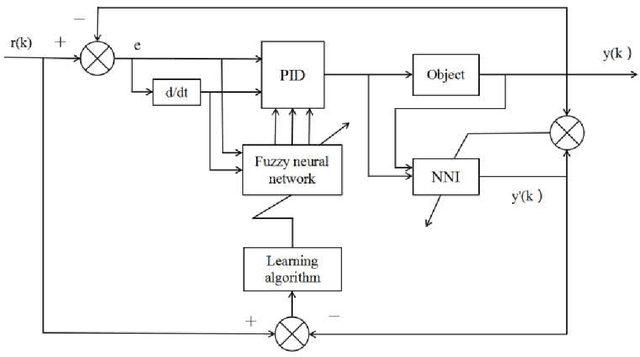
Distillation process is a complex process of conduction, mass transfer and heat conduction, which is mainly manifested as follows: The mechanism is complex and changeable with uncertainty; the process is multivariate and strong coupling; the system is nonlinear, hysteresis and time-varying. Neural networks can perform effective learning based on corresponding samples, do not rely on fixed mechanisms, have the ability to approximate arbitrary nonlinear mappings, and can be used to establish system input and output models. The temperature system of the rectification tower has a complicated structure and high accuracy requirements. The neural network is used to control the temperature of the system, which satisfies the requirements of the production process. This article briefly describes the basic concepts and research progress of neural network and distillation tower temperature control, and systematically summarizes the application of neural network in distillation tower control, aiming to provide reference for the development of related industries.