 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Modeling Method for RF Devices Based on Uniform Noise Training Set
Dec 05, 2024As the scale and complexity of integrated circuits continue to increase, traditional modeling methods are struggling to address the nonlinear challenges in radio frequency (RF) chips. Deep learning has been increasingly applied to RF device modeling. This paper proposes a deep learning-based modeling method for RF devices using a uniform noise training set, aimed at modeling and fitting the nonlinear characteristics of RF devices. We hypothesize that a uniform noise signal can encompass the full range of characteristics across both frequency and amplitude, and that a deep learning model can effectively capture and learn these features. Based on this hypothesis, the paper designs a complete integrated circuit modeling process based on measured data, including data collection, processing, and neural network training. The proposed method is experimentally validated using the RF amplifier PW210 as a case study. Experimental results show that the uniform noise training set allows the model to capture the nonlinear characteristics of RF devices, and the trained model can predict waveform patterns it has never encountered before. The proposed deep learning-based RF device modeling method, using a uniform noise training set, demonstrates strong generalization capability and excellent training performance, offering high practical application value.
Faster and Safer Training by Embedding High-Level Knowledge into Deep Reinforcement Learning
Oct 22, 2019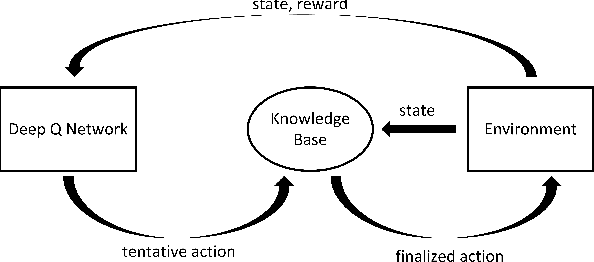
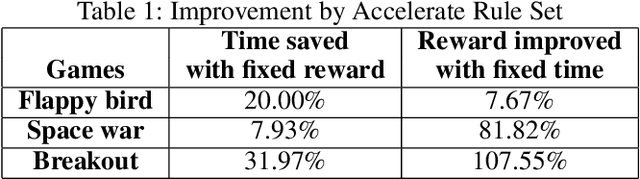

Deep reinforcement learning has been successfully used in many dynamic decision making domains, especially those with very large state spaces. However, it is also well-known that deep reinforcement learning can be very slow and resource intensive. The resulting system is often brittle and difficult to explain. In this paper, we attempt to address some of these problems by proposing a framework of Rule-interposing Learning (RIL) that embeds high level rules into the deep reinforcement learning. With some good rules, this framework not only can accelerate the learning process, but also keep it away from catastrophic explorations, thus making the system relatively stable even during the very early stage of training. Moreover, given the rules are high level and easy to interpret, they can be easily maintained, updated and shared with other similar tasks.