 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Representation of Temporal Image Sequences and Object Motion for Video Object Detection
Paper and Code
Nov 20, 2020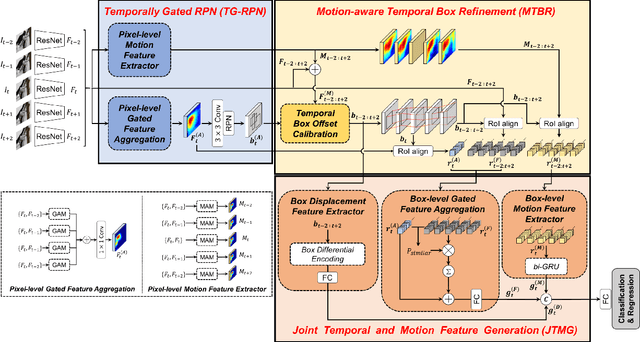
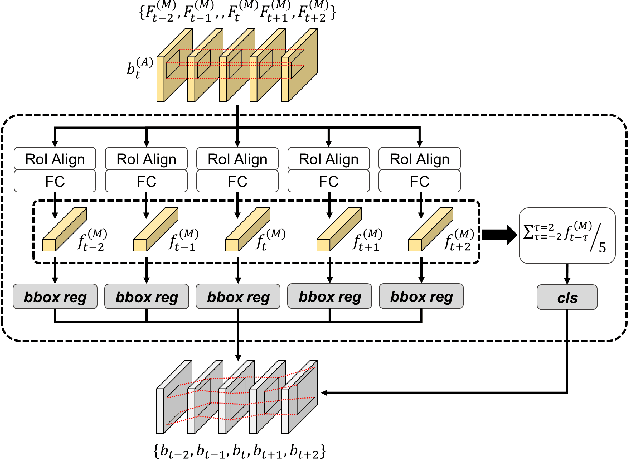
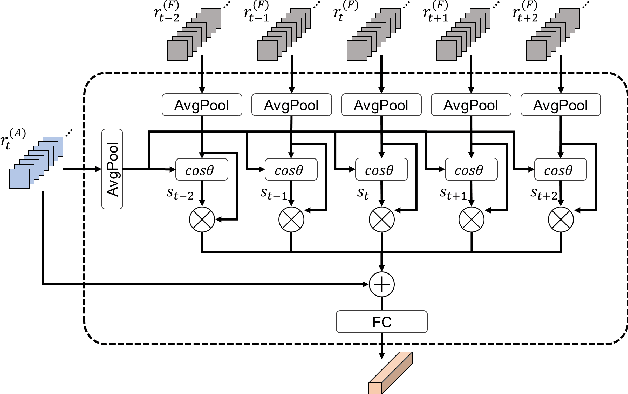

In this paper, we propose a new video object detector (VoD) method referred to as temporal feature aggregation and motion-aware VoD (TM-VoD), which produces a joint representation of temporal image sequences and object motion. The proposed TM-VoD aggregates visual feature maps extracted by convolutional neural networks applying the temporal attention gating and spatial feature alignment. This temporal feature aggregation is performed in two stages in a hierarchical fashion. In the first stage, the visual feature maps are fused at a pixel level via gated attention model. In the second stage, the proposed method aggregates the features after aligning the object features using temporal box offset calibration and weights them according to the cosine similarity measure. The proposed TM-VoD also finds the representation of the motion of objects in two successive steps. The pixel-level motion features are first computed based on the incremental changes between the adjacent visual feature maps. Then, box-level motion features are obtained from both the region of interest (RoI)-aligned pixel-level motion features and the sequential changes of the box coordinates. Finally, all these features are concatenated to produce a joint representation of the objects for VoD. The experiments conducted on the ImageNet VID dataset demonstrate that the proposed method outperforms existing VoD methods and achieves a performance comparable to that of state-of-the-art VoDs.