 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift R-CNN: Deep Monocular 3D Object Detection with Closed-Form Geometric Constraints
May 23, 2019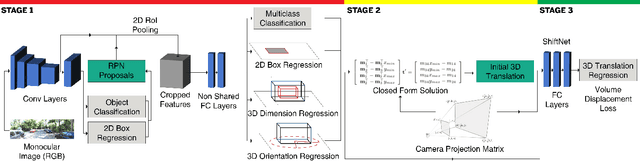
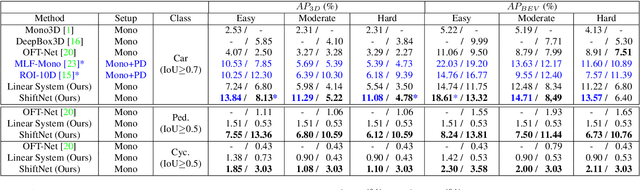

We propose Shift R-CNN, a hybrid model for monocular 3D object detection, which combines deep learning with the power of geometry. We adapt a Faster R-CNN network for regressing initial 2D and 3D object properties and combine it with a least squares solution for the inverse 2D to 3D geometric mapping problem, using the camera projection matrix. The closed-form solution of the mathematical system, along with the initial output of the adapted Faster R-CNN are then passed through a final ShiftNet network that refines the result using our newly proposed Volume Displacement Loss. Our novel, geometrically constrained deep learning approach to monocular 3D object detection obtains top results on KITTI 3D Object Detection Benchmark, being the best among all monocular methods that do not use any pre-trained network for depth estimation.
Scene Understanding Networks for Autonomous Driving based on Around View Monitoring System
May 18, 2018
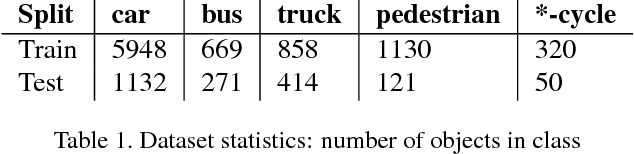

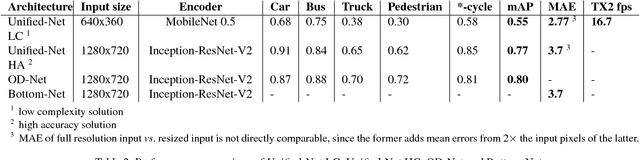
Modern driver assistance systems rely on a wide range of sensors (RADAR, LIDAR, ultrasound and cameras) for scene understanding and prediction. These sensors are typically used for detecting traffic participants and scene elements required for navigation. In this paper we argue that relying on camera based systems, specifically Around View Monitoring (AVM) system has great potential to achieve these goals in both parking and driving modes with decreased costs. The contributions of this paper are as follows: we present a new end-to-end solution for delimiting the safe drivable area for each frame by means of identifying the closest obstacle in each direction from the driving vehicle, we use this approach to calculate the distance to the nearest obstacles and we incorporate it into a unified end-to-end architecture capable of joint object detection, curb detection and safe drivable area detection. Furthermore, we describe the family of networks for both a high accuracy solution and a low complexity solution. We also introduce further augmentation of the base architecture with 3D object detection.