 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-specific Distillation
Paper and Code
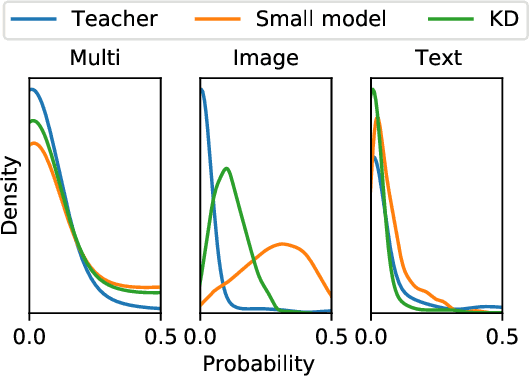
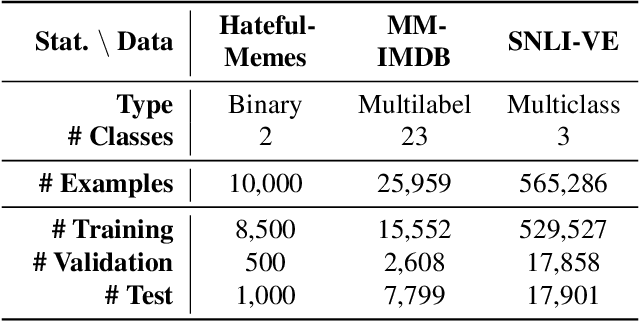
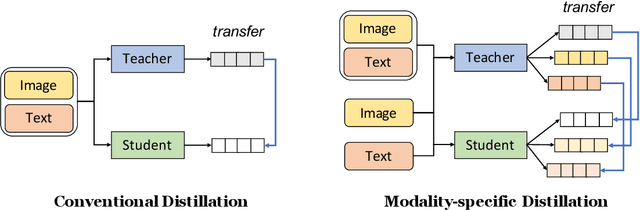
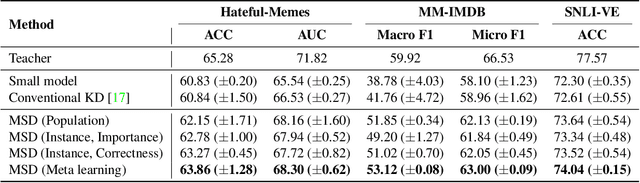
Large neural networks are impractical to deploy on mobile devices due to their heavy computational cost and slow inference. Knowledge distillation (KD) is a technique to reduce the model size while retaining performance by transferring knowledge from a large "teacher" model to a smaller "student" model. However, KD on multimodal datasets such as vision-language datasets is relatively unexplored and digesting such multimodal information is challenging since different modalities present different types of information. In this paper, we propose modality-specific distillation (MSD) to effectively transfer knowledge from a teacher on multimodal datasets. Existing KD approaches can be applied to multimodal setup, but a student doesn't have access to modality-specific predictions. Our idea aims at mimicking a teacher's modality-specific predictions by introducing an auxiliary loss term for each modality. Because each modality has different importance for predictions, we also propose weighting approaches for the auxiliary losses; a meta-learning approach to learn the optimal weights on these loss terms. In our experiments, we demonstrate the effectiveness of our MSD and the weighting scheme and show that it achieves better performance than KD.