 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinoViz: Probing Visual Properties of Objects Under Different States
Paper and Code
Feb 21, 2024

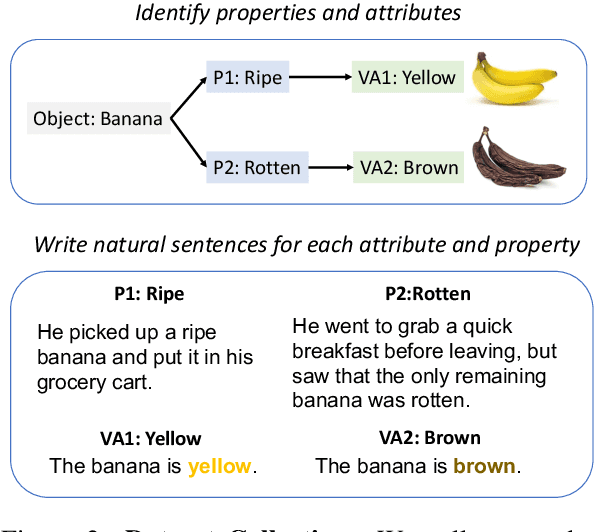

Humans perceive and comprehend different visual properties of an object based on specific contexts. For instance, we know that a banana turns brown ``when it becomes rotten,'' whereas it appears green ``when it is unripe.'' Previous studies on probing visual commonsense knowledge have primarily focused on examining language models' understanding of typical properties (e.g., colors and shapes) of objects. We present WinoViz, a text-only evaluation dataset, consisting of 1,380 examples that probe the reasoning abilities of language models regarding variant visual properties of objects under different contexts or states. Our task is challenging since it requires pragmatic reasoning (finding intended meanings) and visual knowledge reasoning. We also present multi-hop data, a more challenging version of our data, which requires multi-step reasoning chains to solve our task. In our experimental analysis, our findings are: a) Large language models such as GPT-4 demonstrate effective performance, but when it comes to multi-hop data, their performance is significantly degraded. b) Large models perform well on pragmatic reasoning, but visual knowledge reasoning is a bottleneck in our task. c) Vision-language models outperform their language-model counterparts. d) A model with machine-generated images performs poorly in our task. This is due to the poor quality of the generated images.