 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoForce: Development of an Intuitive Axial Force Measurement Device for Endoscopic Robotic Systems
May 19, 2025Robotic endoscopic systems provide intuitive control and eliminate radiation exposure, making them a promising alternative to conventional methods. However, the lack of axial force measurement from the robot remains a major challenge, as it can lead to excessive colonic elongation, perforation, or ureteral complications. Although various methods have been proposed in previous studies, limitations such as model dependency, bulkiness, and environmental sensitivity remain challenges that should be addressed before clinical application. In this study, we propose EndoForce, a device designed for intuitive and accurate axial force measurement in endoscopic robotic systems. Inspired by the insertion motion performed by medical doctors during ureteroscopy and gastrointestinal (GI) endoscopy, EndoForce ensures precise force measuring while maintaining compatibility with clinical environments. The device features a streamlined design, allowing for the easy attachment and detachment of a sterile cover, and incorporates a commercial load cell to enhance cost-effectiveness and facilitate practical implementation in real medical applications. To validate the effectiveness of the proposed EndoForce, physical experiments were performed using a testbed that simulates the ureter. We show that the axial force generated during insertion was measured with high accuracy, regardless of whether the pathway was straight or curved, in a testbed simulating the human ureter.
Non-linear Hysteresis Compensation of a Tendon-sheath-driven Robotic Manipulator using Motor Current
Nov 03, 2020

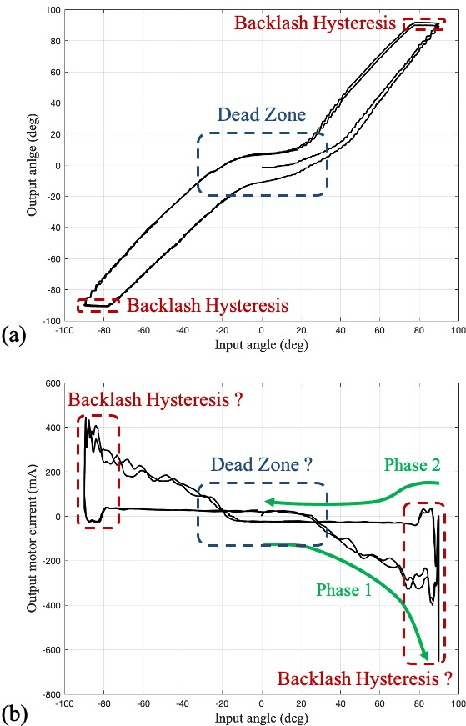
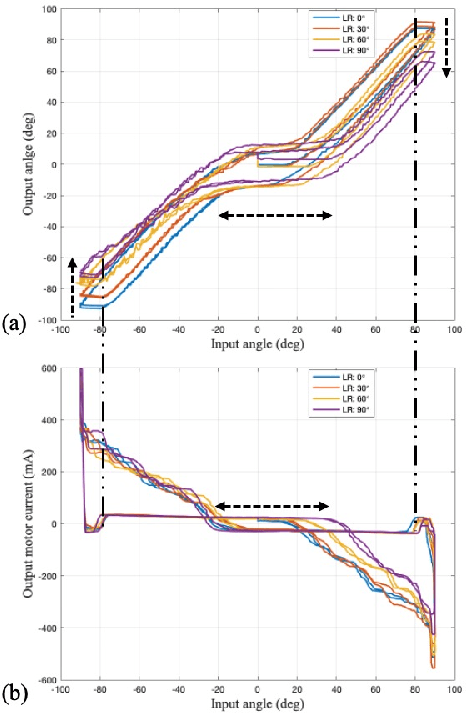
Tendon-sheath-driven manipulators (TSM) are widely used in minimally invasive surgical systems due to their long, thin shape, flexibility, and compliance making them easily steerable in narrow or tortuous environments. Many commercial TSM-based medical devices have non-linear phenomena resulting from their composition such as backlash and dead zone hysteresis, which lead to a considerable challenge for achieving precise control of the end effector pose. However, many recent works in the literature do not consider the combined effects and compensation of these phenomena, and less focus on practical ways to identify model parameters in real field. In this paper, we propose a simplified piece-wise linear model to compensate both backlash and dead zone hysteresis together. Further, we introduce a practical method to identify model parameters using motor current from a robotic controller for the TSM. We analyze our proposed methods with multiple Intra-cardiac Echocardiography catheters, which are typical commercial example of TSM. Our results show that the errors from backlash and dead zone hysteresis are considerably reduced and therefore the accuracy of robotic control is improved when applying the presented methods.
Baseline CNN structure analysis for facial expression recognition
Nov 14, 2016
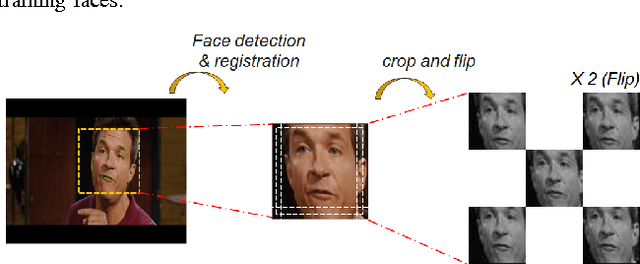

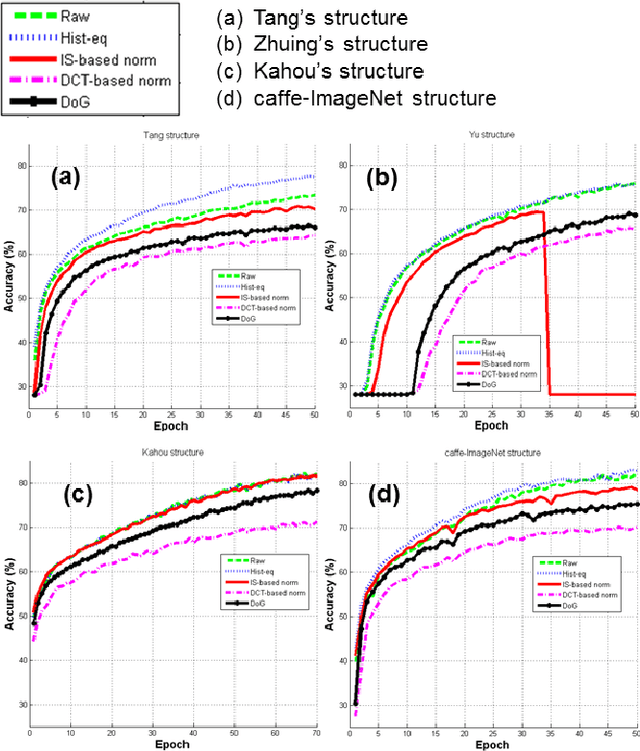
We present a baseline convolutional neural network (CNN) structure and image preprocessing methodology to improve facial expression recognition algorithm using CNN. To analyze the most efficient network structure, we investigated four network structures that are known to show good performance in facial expression recognition. Moreover, we also investigated the effect of input image preprocessing methods. Five types of data input (raw, histogram equalization, isotropic smoothing, diffusion-based normalization, difference of Gaussian) were tested, and the accuracy was compared. We trained 20 different CNN models (4 networks x 5 data input types) and verified the performance of each network with test images from five different databases. The experiment result showed that a three-layer structure consisting of a simple convolutional and a max pooling layer with histogram equalization image input was the most efficient. We describe the detailed training procedure and analyze the result of the test accuracy based on considerable observation.