 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation
Paper and Code
Dec 10, 2021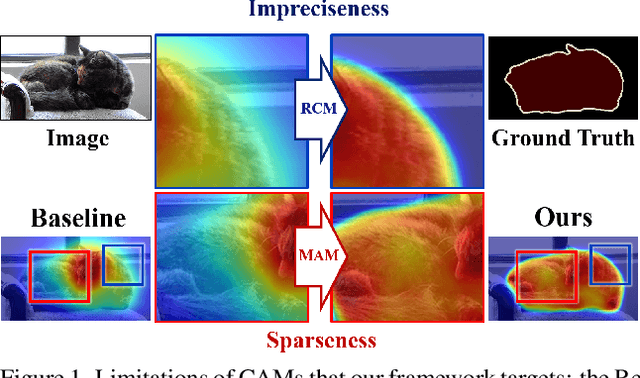
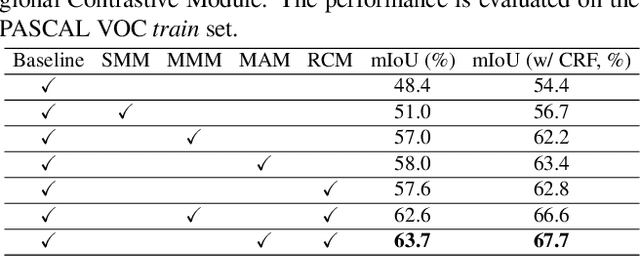
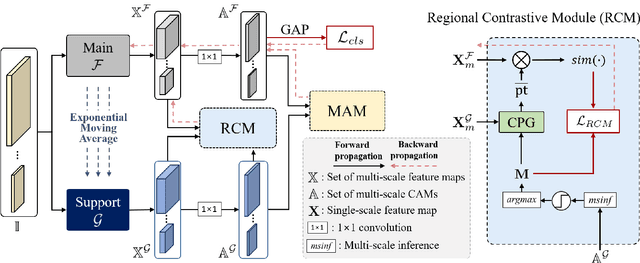
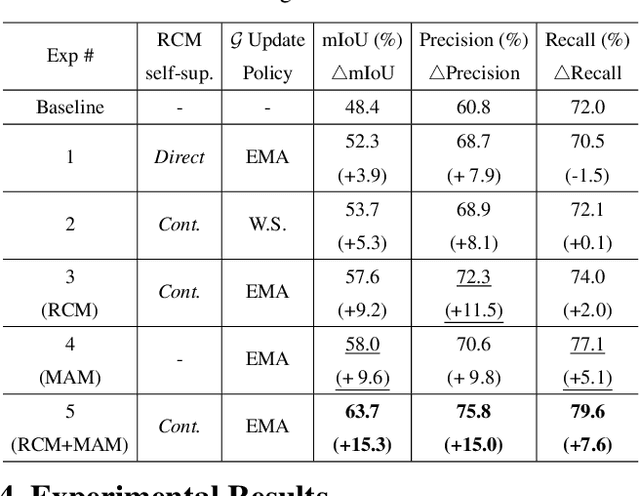
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects. However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness). To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision. In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet. The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks. Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs. The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet. Based on the dissimilarity between the multi-scale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions. The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset. For reproducibility, code will be available publicly soon.