 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend-and-Refine: Interactive keypoint estimation and quantitative cervical vertebrae analysis for bone age assessment
Jul 10, 2025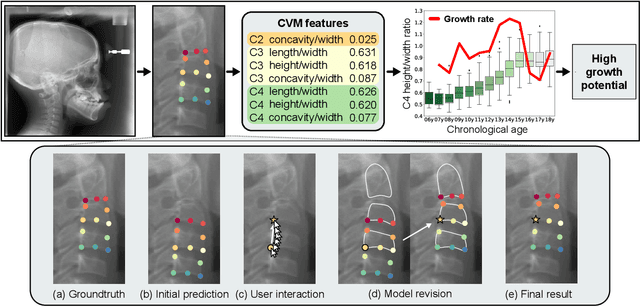
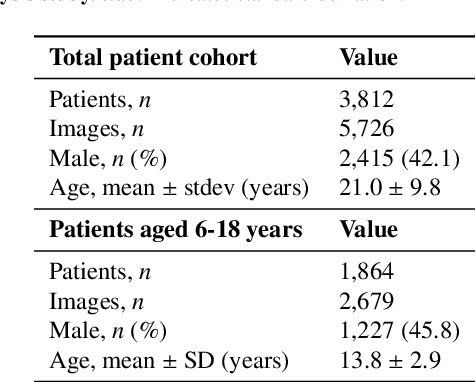
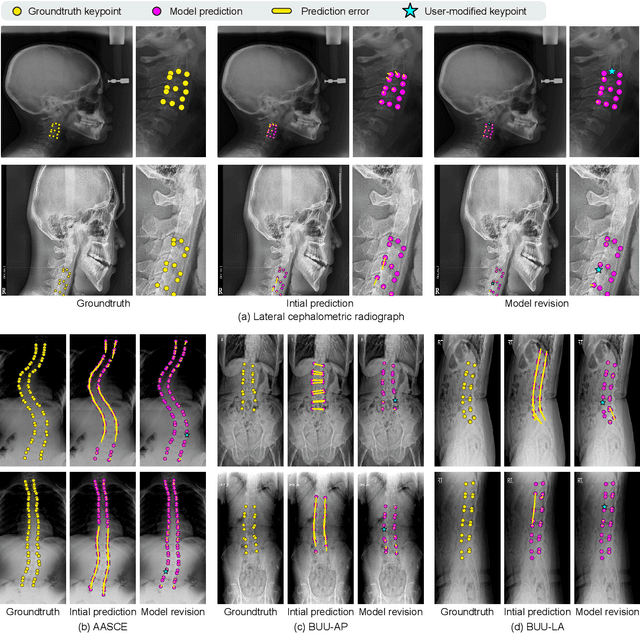
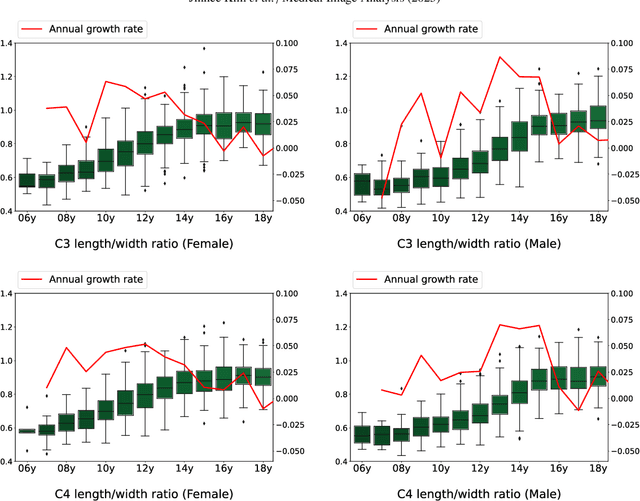
In pediatric orthodontics, accurate estimation of growth potential is essential for developing effective treatment strategies. Our research aims to predict this potential by identifying the growth peak and analyzing cervical vertebra morphology solely through lateral cephalometric radiographs. We accomplish this by comprehensively analyzing cervical vertebral maturation (CVM) features from these radiographs. This methodology provides clinicians with a reliable and efficient tool to determine the optimal timings for orthodontic interventions, ultimately enhancing patient outcomes. A crucial aspect of this approach is the meticulous annotation of keypoints on the cervical vertebrae, a task often challenged by its labor-intensive nature. To mitigate this, we introduce Attend-and-Refine Network (ARNet), a user-interactive, deep learning-based model designed to streamline the annotation process. ARNet features Interaction-guided recalibration network, which adaptively recalibrates image features in response to user feedback, coupled with a morphology-aware loss function that preserves the structural consistency of keypoints. This novel approach substantially reduces manual effort in keypoint identification, thereby enhancing the efficiency and accuracy of the process. Extensively validated across various datasets, ARNet demonstrates remarkable performance and exhibits wide-ranging applicability in medical imaging. In conclusion, our research offers an effective AI-assisted diagnostic tool for assessing growth potential in pediatric orthodontics, marking a significant advancement in the field.
Bones Can't Be Triangles: Accurate and Efficient Vertebrae Keypoint Estimation through Collaborative Error Revision
Sep 05, 2024Recent advances in interactive keypoint estimation methods have enhanced accuracy while minimizing user intervention. However, these methods require user input for error correction, which can be costly in vertebrae keypoint estimation where inaccurate keypoints are densely clustered or overlap. We introduce a novel approach, KeyBot, specifically designed to identify and correct significant and typical errors in existing models, akin to user revision. By characterizing typical error types and using simulated errors for training, KeyBot effectively corrects these errors and significantly reduces user workload. Comprehensive quantitative and qualitative evaluations on three public datasets confirm that KeyBot significantly outperforms existing methods, achieving state-of-the-art performance in interactive vertebrae keypoint estimation. The source code and demo video are available at: https://ts-kim.github.io/KeyBot/
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Apr 15, 2024



Generating realistic synthetic tabular data presents a critical challenge in machine learning. This study introduces a simple yet effective method employing Large Language Models (LLMs) tailored to generate synthetic data, specifically addressing data imbalance problems. We propose a novel group-wise prompting method in CSV-style formatting that leverages the in-context learning capabilities of LLMs to produce data that closely adheres to the specified requirements and characteristics of the target dataset. Moreover, our proposed random word replacement strategy significantly improves the handling of monotonous categorical values, enhancing the accuracy and representativeness of the synthetic data. The effectiveness of our method is extensively validated across eight real-world public datasets, achieving state-of-the-art performance in downstream classification and regression tasks while maintaining inter-feature correlations and improving token efficiency over existing approaches. This advancement significantly contributes to addressing the key challenges of machine learning applications, particularly in the context of tabular data generation and handling class imbalance. The source code for our work is available at: https://github.com/seharanul17/synthetic-tabular-LLM
Morphology-Aware Interactive Keypoint Estimation
Sep 15, 2022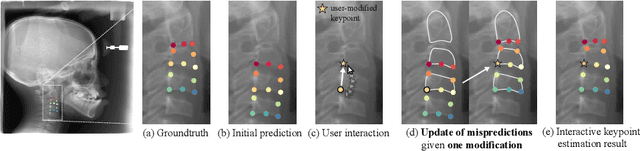
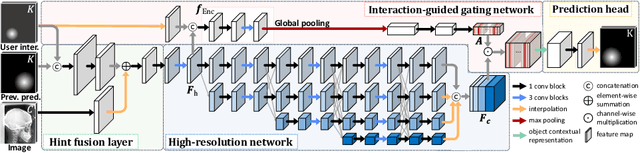
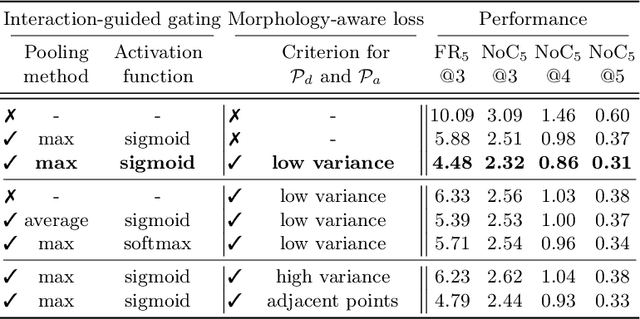

Diagnosis based on medical images, such as X-ray images, often involves manual annotation of anatomical keypoints. However, this process involves significant human efforts and can thus be a bottleneck in the diagnostic process. To fully automate this procedure, deep-learning-based methods have been widely proposed and have achieved high performance in detecting keypoints in medical images. However, these methods still have clinical limitations: accuracy cannot be guaranteed for all cases, and it is necessary for doctors to double-check all predictions of models. In response, we propose a novel deep neural network that, given an X-ray image, automatically detects and refines the anatomical keypoints through a user-interactive system in which doctors can fix mispredicted keypoints with fewer clicks than needed during manual revision. Using our own collected data and the publicly available AASCE dataset, we demonstrate the effectiveness of the proposed method in reducing the annotation costs via extensive quantitative and qualitative results. A demo video of our approach is available on our project webpage.