 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLVideo: A Sign Language Video Moment Retrieval Framework
Jul 22, 2024


Sign Language Recognition has been studied and developed throughout the years to help the deaf and hard-of-hearing people in their day-to-day lives. These technologies leverage manual sign recognition algorithms, however, most of them lack the recognition of facial expressions, which are also an essential part of Sign Language as they allow the speaker to add expressiveness to their dialogue or even change the meaning of certain manual signs. SLVideo is a video moment retrieval software for Sign Language videos with a focus on both hands and facial signs. The system extracts embedding representations for the hand and face signs from video frames to capture the language signs in full. This will then allow the user to search for a specific sign language video segment with text queries, or to search by similar sign language videos. To test this system, a collection of five hours of annotated Sign Language videos is used as the dataset, and the initial results are promising in a zero-shot setting.SLVideo is shown to not only address the problem of searching sign language videos but also supports a Sign Language thesaurus with a search by similarity technique. Project web page: https://novasearch.github.io/SLVideo/
Evaluating gesture-generation in a large-scale open challenge: The GENEA Challenge 2022
Mar 15, 2023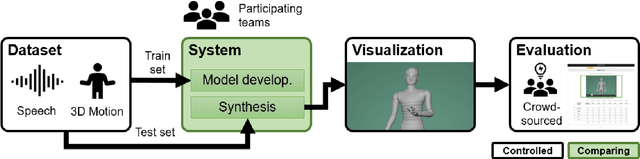
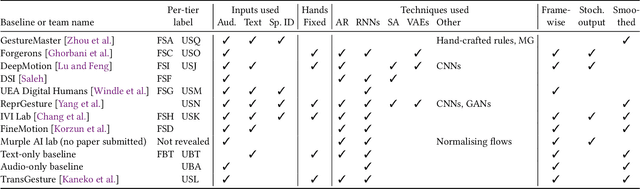
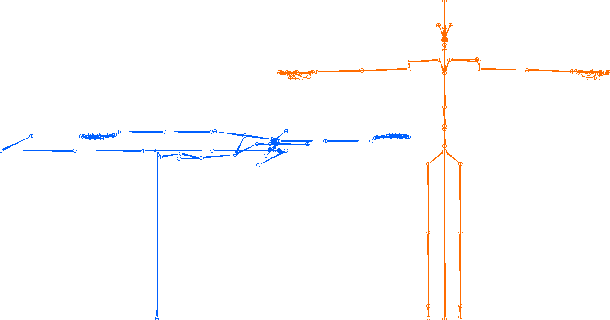
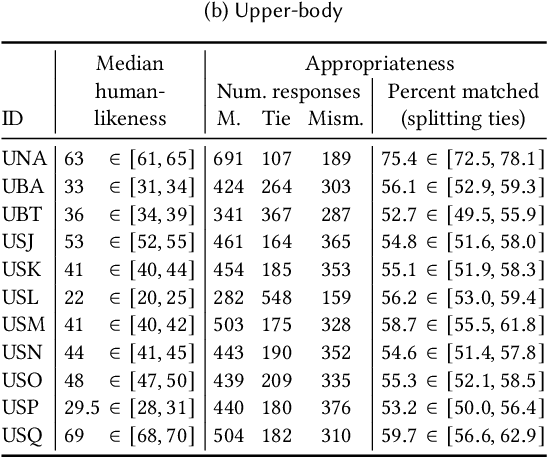
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. The dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in a dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier, we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which has been a difficult problem in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. We also find that conventional objective metrics do not correlate well with subjective human-likeness ratings in this large evaluation. The one exception is the Fr\'echet gesture distance (FGD), which achieves a Kendall's tau rank correlation of around -0.5. Based on the challenge results we formulate numerous recommendations for system building and evaluation.
The GENEA Challenge 2022: A large evaluation of data-driven co-speech gesture generation
Aug 22, 2022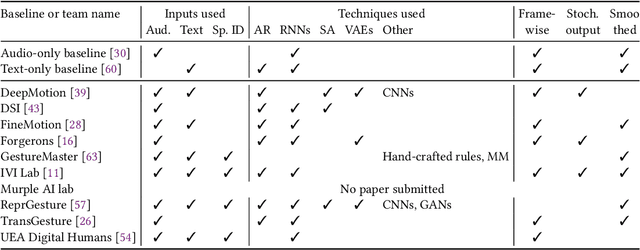
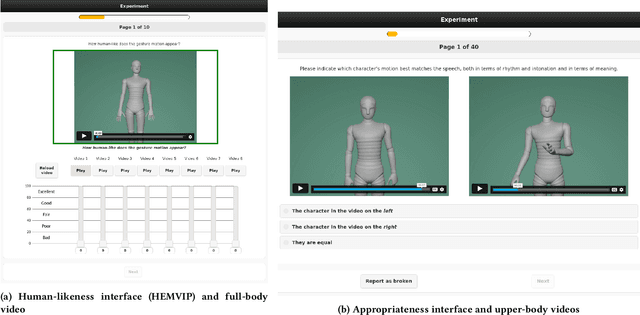
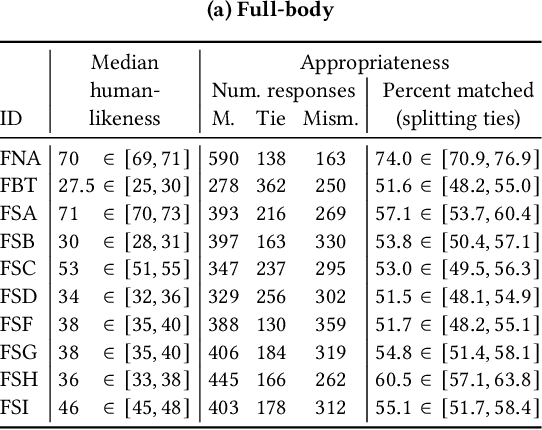
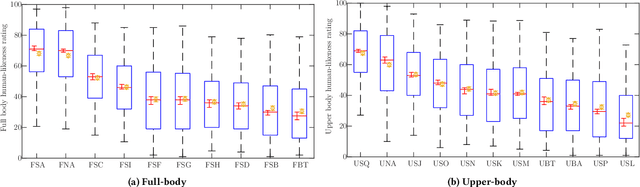
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. This year's dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which previously was a major challenge in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. Additional material is available via the project website at https://youngwoo-yoon.github.io/GENEAchallenge2022/
Including Facial Expressions in Contextual Embeddings for Sign Language Generation
Feb 11, 2022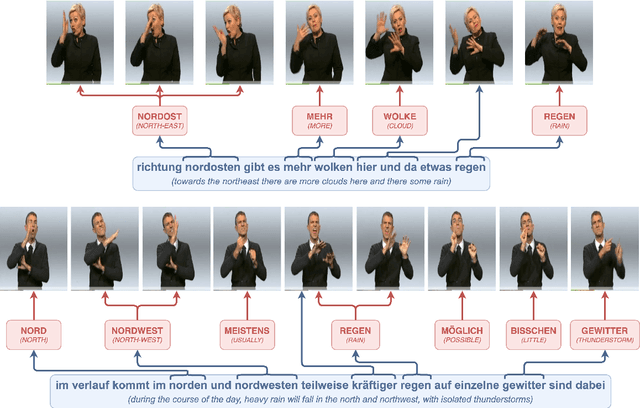

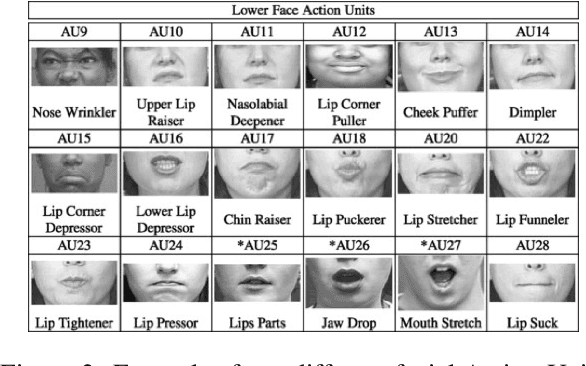

State-of-the-art sign language generation frameworks lack expressivity and naturalness which is the result of only focusing manual signs, neglecting the affective, grammatical and semantic functions of facial expressions. The purpose of this work is to augment semantic representation of sign language through grounding facial expressions. We study the effect of modeling the relationship between text, gloss, and facial expressions on the performance of the sign generation systems. In particular, we propose a Dual Encoder Transformer able to generate manual signs as well as facial expressions by capturing the similarities and differences found in text and sign gloss annotation. We take into consideration the role of facial muscle activity to express intensities of manual signs by being the first to employ facial action units in sign language generation. We perform a series of experiments showing that our proposed model improves the quality of automatically generated sign language.