 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Oct 08, 2024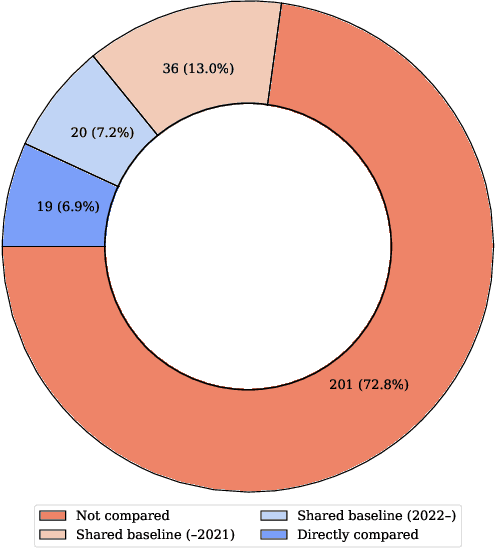

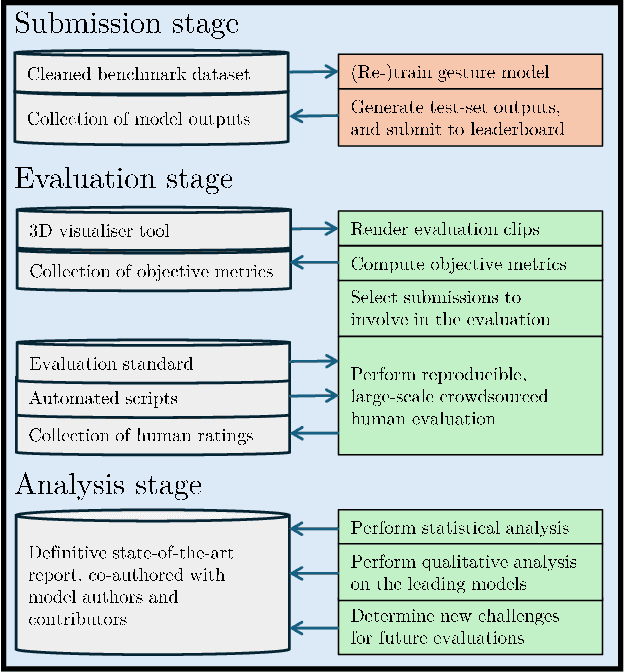

Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
Integrating Representational Gestures into Automatically Generated Embodied Explanations and its Effects on Understanding and Interaction Quality
Jun 18, 2024In human interaction, gestures serve various functions such as marking speech rhythm, highlighting key elements, and supplementing information. These gestures are also observed in explanatory contexts. However, the impact of gestures on explanations provided by virtual agents remains underexplored. A user study was carried out to investigate how different types of gestures influence perceived interaction quality and listener understanding. This study addresses the effect of gestures in explanation by developing an embodied virtual explainer integrating both beat gestures and iconic gestures to enhance its automatically generated verbal explanations. Our model combines beat gestures generated by a learned speech-driven synthesis module with manually captured iconic gestures, supporting the agent's verbal expressions about the board game Quarto! as an explanation scenario. Findings indicate that neither the use of iconic gestures alone nor their combination with beat gestures outperforms the baseline or beat-only conditions in terms of understanding. Nonetheless, compared to prior research, the embodied agent significantly enhances understanding.